1. 컴포넌트화의 필요성
전산학 중에서 소프트웨어공학이라는 것은 방대한 소프트웨어를 인간이 여전히 유지보수 가능하게 복잡도를 제어하며 설계하기, 기능과 파트별로 역할을 잘 분담시켜서 각 파트만 재사용하거나 딴 걸로 교체를 쉽게 가능하게 하기, 소프트웨어의 분량· 작업량· 품질을 정확하게 측정하고 효율적인 개발 절차를 정립하기처럼..
응용수학이나 전자공학보다는 산업공학과 가까운 측면이 있다. 단지, 얘는 유형의 제품이 아니라 무형의 코드 형태이기 때문에 여느 공산품과는 성격이 약간 다르게 취급될 뿐이다.
20세기 후반에 인공지능 연구 업계에 "AI 겨울"이 있었고 게임 업계에 "아타리 쇼크"라는 재앙이 있었던 것처럼, 프로그래밍 업계에도 "소프트웨어의 위기"라는 게 이미 1970년대에부터 있었다.
- 코딩을 너무 중구난방으로 하고 나니, 일정 규모 이상의 프로젝트에서는 도대체 유지보수가 되질 않고 그냥 처음부터 다시 새로 만드는 게 더 나을 지경이 된다.
- 이놈의 빌어먹을 스파게티 코드는 하는 일도 별로 없는데 쓸데없이 너무 복잡해서.. 처음에 작성했던 사람 말고는 알아먹을 수가 없고 maintainable하지가 않다.
- 소프트웨어의 개발 속도가 오히려 하드웨어의 발전 속도를 따라가지 못한다.
- 작업 기간을 줄이기 위해서 사람을 더 뽑았는데.. 웬걸, 신입들을 가르치느라 시간이 더 소요된다;;;
그래서일까..??
"무식한 goto문 사용을 자제하자"라는 구조화 프로그래밍 이후로 객체지향 프로그래밍이란 게 프로그래밍 언어와 코딩 패러다임을 완전히 정복했다. 요즘 주류 언어들 중에 '클래스', 그리고 '상속'이라는 게 없는 언어는 찾을 수 없을 것이다.;; 이게 캡슐화, 은닉, 재사용성 등 소프트웨어공학적으로 여러 바람직한 이념을 코드에다 자연스럽게 반영해 주기 때문이다.
실험적으로 시도됐던 초창기의 순수 객체지향 언어들은 유연하지만 느린 런타임 바인딩 기반의 메시지로 객체 메소드를 호출한다거나.. 심지어 정수 하나 같은 built-in type에다가도 몽땅 타입 정보 같은 걸 덧붙이며 객체지향을 구현하느라 성능 삽질이 많은 경우도 있었다.
그러나 C++은 객체지향 이념에다가 C의 저수준, 그리고 빌드타임 바인딩(경직되지만 빠른..)을 지향하는 현실 절충형 디자인 덕분에 상업적으로 굉장히 성공한 객체지향 언어로 등극했다.
2. 마소의 실험
자 그래서..
1990년대에 마소에서는 고유 브랜드인 Windows가 대히트를 치고 소프트웨어 OEM (IBM 납품..)으로 그럭저럭 먹고 살던 처지를 완전히 벗어나니.. 당장 먹고 사는 고민보다 더 본질적이고 고차원적인, 소프트웨어공학적인 고민을 시작했던 것 같다.
얘들 역시 소프트웨어를 재사용 가능한 컴포넌트 형태로 만드는 것에 관심을 많이 기울였다. 그래서 재사용을 위해 바이너리 수준의 공통 규약, 프로토콜을 만들어서 자기들의 운영체제 차원에서 밀어붙이고 홍보하기 시작했다.
이때가 마침 C에 이어 C++ 컴파일러를 개발하고 MFC라는 라이브러리도 만들고, 코딩 스타일에 본격적으로 '객체지향'이란 게 가미되기도 했던 때이다. 하지만 마소에서 추구했던 것은 단순히 언어나 개발툴 차원에서 함수나 클래스의 모음집인 라이브러리 SDK 만들고 DLL 만드는 것 이상의 수준이었다.
제일 먼저.. (1) Windows라는 이름답게, 특정 기능을 수행하는 윈도 컨트롤을 컴포넌트화한다. 리치 에디트 컨트롤을 비롯해 각종 공용 컨트롤, 웹브라우저 컨트롤 같은 것 말이다. 이 사고방식이 극대화되어 "컴포넌트를 내 폼에다가 끌어다 놓고, 프로퍼티를 설정하고 이벤트 핸들러를 구현해서 응용 프로그램을 곧바로 만든다" RAD라는 개념이 완성되었으며.. Visual Basic이라는 정말 똘끼 충만한 개발툴이 만들어지게 됐다.
도스 시절의 GWBASIC이나 QuickBasic에서 참신한 점은 그 특유의 대화식 환경이었는데, Visual Basic은 또 다른 새로운 돌풍을 일으켰다. 경쟁사인 볼랜드에서는 이런 개발 스타일을 파스칼과 C++에다가도 도입하게 됐다.
(2) 그리고 마소에서는 서로 다른 응용 프로그램에서 만든 결과물을 문서에 자유롭게 삽입할 수 있게 했다. 이름하여 OLE라는 기술이다.
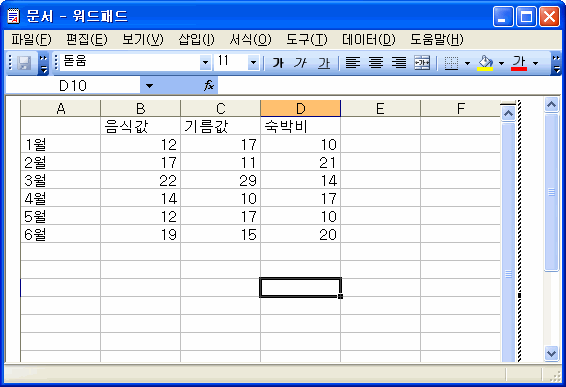
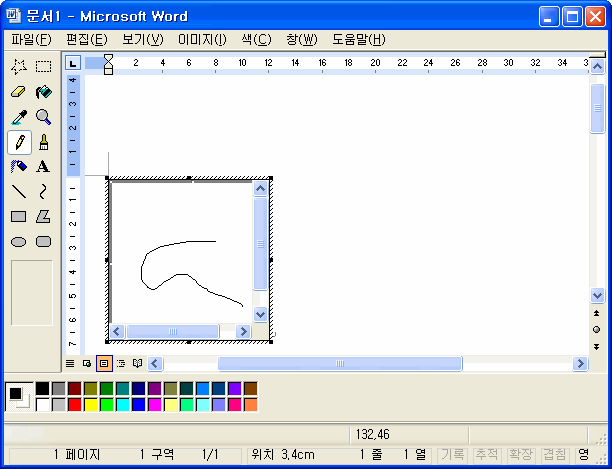
가령, Windows의 워드패드는 아래아한글이나 MS Office Word에 비하면 아주 허접한 프로그램일 뿐이다. 하지만 문서 안에 그림판에서 만든 비트맵 이미지를 집어넣고, 엑셀에서 만든 차트를 집어넣을 수 있다.
별도의 수학 수식 편집기에서 만든 수식, 악보 편집기에서 만든 악보, 그리고 WordArt/글맵시 같은 프로그램으로 만든 각종 글자 꾸임 배너까지..
단순히 무식한 그림 형태로 집어넣는 게 아니라는 것이 핵심이다. 이것들은 벡터 이미지로 취급되기 때문에 크기를 키워도 화질이 깔끔하게 유지된다.
그리고 그런 출력 이미지 자체뿐만 아니라, 각 프로그램에서 취급하는 내부 원본 데이터, 즉 소스가 그대로 보존된다. 그렇기 때문에 만들었던 객체를 손쉽게 수정도 할 수 있다.
그 객체를 더블 클릭하면 프로그램 내부에서 그림판이나 악보 편집기, 수식 편집기 등이 잠시 실행돼서 객체를 수정하는 상태가 된다..;;
 |  |
서로 다른 프로그램이 이런 식으로 서로 분업 협업한다니.. 신기하지 않은가? 도스 시절에는 상상도 못 한 일일 것이다.
3. 프로그래밍의 관점
그러니 Windows에서 워드처럼 뭔가 인쇄 가능한 출력물을 만드는 업무 프로그램이라면 OLE 지원은 그냥 닥치고 무조건 필수였다. 다른 OLE 프로그램의 결과물을 삽입하든(클라), 아니면 다른 프로그램에다 자기 결과물을 제공하든(서버), 혹은 둘 다 말이다. macOS나 리눅스에는 비슷한 역할을 하는 규격이나 기술이 있는지 궁금하다.
Windows 프로그래밍을 다루는 책은 고급 topic에서 OLE를 다루는 것이 관행이었다. 다만, Windows API만으로 OLE 지원을 저수준 구현하는 건 굉장히 노가다가 심하고 귀찮았다. 그래서 MFC 같은 라이브러리 내지 아예 VB 같은 상위 런타임이 이 일을 상당수 간소화해 줬었다. MFC 앱 신규 프로젝트 세팅 마법사의 경우, OLE 지원 기능의 추가 여부를 선택하는 옵션이 응당 제공되었다.
Windows라는 플랫폼의 프로그래밍에 입문하려면 창(윈도)의 스타일과 특성, 메시지 메커니즘을 알아야 할 것이고 그래픽 API라든가 셸의 구조에 대해서도 알아야 할 것이다.
그런데 그런 것뿐만 아니라 이 바닥도 완전히 독립된 별개의 프로그래밍 분야이며, 기초부터 고급까지 한데 연결된 Windows 프로그래밍의 정수라고 생각된다.
이건 제일 간단하게는 확장자 연결이나 클립보드, drag & drop 구현과도 연결고리가 있다. 이 분야 API를 제공하다 보니 COM이라는 IUnknown이 어떻고 type library가 어떻고 하는 규격이 제정되었다.
사실, Windows에 레지스트리라는 것도 맨 처음엔 확장자 연결이나 OLE 클라/서버 정보만 저장하기 위해서 만들어졌다가.. 나중에 ini를 대체하는 응용 프로그램 설정 저장 DB로 용도가 확장된 것이다.
COM 형태로 제공되는 운영체제 기능을 사용하려면 CoCreateInstance를 호출해야 하고, 이런 프로그램은 처음에 CoInitialize라는 함수를 호출해 줘야 한다. 즉, 운영체제를 상대로도 별도의 초기화가 필요하다는 것이다.
그런데 OLE 기능을 사용하려면 OleInitialize라는 함수를 사용하게 돼 있는데, 얘가 하는 일은 CoInitialize의 상위 호환이다. OLE가 COM의 형태로 구현돼 있기 때문에 그렇다. 둘의 관계가 이러하다.
굳이 OLE 관련 기능뿐만 아니라 가까이에는 DirectX, 그리고 날개셋 한글 입력기와도 관계가 있는 TSF 문자 입력 인터페이스도 다 COM 기반이다. 하지만 문자 입력은 굳이 COM이나 OLE 따위 기능을 사용하지 않는 프로그램에서도 관련 기능을 접근할 수 있어야 하기 때문에 COM 초기화 없이 관련 인터페이스들을 바로 생성해 주는 함수를 별도로 제공하는 편이다.
4. ActiveX
과거에 인터넷 환경에서 마소 IE 브라우저의 지저분한 독점과 비표준 ActiveX는 정말 악명 높았다. 그런데 ActiveX라는 건 도대체 무슨 물건인 걸까??
마소에서는 앞서 컴포넌트화했던 그 윈도 컨트롤들을 데스크톱 앱뿐만 아니라 인터넷 웹에서도 그대로 돌려서 그 당시 1990년대 중후반에 각광받고 있던 Java applet에 대항하려 했다. Visual Basic 폼 내지, 특정 프로그램의 내부에서 플래시나 IE 컨트롤 생성하듯이 꺼내 쓸 법한 물건을 웹에서 HTML object 태그를 지정해서 그대로 띄운다는 것이다.
그때는 컴퓨터의 성능이 지금처럼 좋지 못했고 지금 같은 방대한 웹 표준이 존재하지도 않았었다.
그러니 웹브라우저에서 동영상도 보고 초고속으로 돌아가는 게임도 하고, 특히 무엇보다도 금융 거래를 위한 각종 암호화 기능을 돌리기 위해서는 닥치고 웹에서 그냥 생짜 x86 native 앱을 돌리는 게 제일 편했다.
이런 컴포넌트의 이름이 OLE Control이었는데, 이걸 웹에다 특화된 형태로 신비주의 마케팅 명칭을 붙인 게 ActiveX 컨트롤이다. 아마 마소 역사를 통틀어 길이 남을 엽기적인 작명이 아닐까? 하긴, DirectX도 비슷한 시기의 작명이니까 말이다. ㅡ,.ㅡ;;
하지만 웹에서 가상 머신이 아니라 특정 플랫폼의 네이티브 코드를 직접 구동하는 건 너무 무식하고 이식성도 떨어지고 표준 친화적이지 못하니 ActiveX는 마소에서도 버림받고 늦어도 2010년대부터는 완전히 퇴출 단계에 들어섰다.
지금은 Java applet도 완전히 멸망했고, 이들의 대체제는 정말 눈부시게 성능이 향상된 JavaScript 가상 머신이라고 보면 될 것이다.
5. OLE와 관련된 과거 유행: embed된 형태로 실행
저렇게 마소에서 COM/OLE니 ActiveX를 막 밀고 양성하던 1990년대 말~2000년대 초에는 어떤 프로그램이 다른 프로그램의 내부에 embed된 형태로 실행된 모습을 지금보다 훨씬 더 자주 볼 수 있었던 것 같다. 그와 관련해서 ActiveDocument (!!)라는 기술도 있긴 했다.
당장, MS Office 97에 있었던 Binder라는 유틸은 여러 Word, Excel 따위의 문서를 한데 묶어서 자기 안에서 해당 프로그램을 띄워서 내용을 편집하는 유틸이었다. 대단한 기술이 동원됐을 것 같지만 그래도 쓸모는 별로 없었는지 후대에는 짤리고 없어졌다.
Visual C++ 6의 IDE는 “새 파일” 대화상자를 보면 통상적인 텍스트 파일이나 프로젝트/Workspace뿐만 아니라 맨 끝에 Other documents라는 탭도 있어서 MS Office 문서를 자기 IDE 안에서 열어서 편집할 수 있었다. 당연히 MS Office가 설치돼 있는 경우에만 한해서.. 아까 그 Binder처럼 말이다.
그런데 이 역시 현실에서는.. 그냥 Word/Excel을 따로 띄우고 말지 굳이 워드/엑셀 문서를 왜 Visual C++ IDE에서 편집하겠는가? 그 기능은 후대엔 없어졌다.
ActiveX 기술의 본가인 IE 브라우저야 더 말할 것도 없다.
저런 MS Office 문서를 다운로드 해서 열면 해당 앱이 따로 열리는 게 아니라, 문서 보기/편집창이 웹페이지 화면에 떴었다. 별도의 프로세스로 말이다. 그 기술이 최초로 도입된 건 IE4가 아니라 1996년의 IE3부터였다.
파워포인트 슬라이드는 그 웹페이지 화면에서 곧장 슬라이드 쇼가 시작됐다. 이건 괜찮은 기능인 것 같다.
옛날에 pdf를 보기 위해서 Acrobat Reader를 쓰던 시절엔, 이 앱도 OLE 기술을 이용해서 IE 내부에 embed된 상태로 뜨는 걸 지원했었다. 지금이야 브라우저가 자체적으로 PDF를 표시해 주는 시대이지만 말이다.;;
요즘 컴터 다루면서 OLE 개체 삽입 기능을 쓸 일이 과연 얼마나 될까?
요즘은 개체 삽입으로 프로그램을 실행했을 때, 예전처럼 프로그램이 embed 형태로 실행되는 게 아니라 그냥 별도의 창으로 따로 뜨는 편인 것 같다. 앞서 소개했던 XP 시절의 모습과는 좀 다르다.
따로 실행됐을 때는 원래 문서에 표시된 컨텐츠와 자기가 다루는 컨텐츠가 따로 노니, 전자는 검은 빗금을 쳐셔 구분해야 한다는 UI 가이드라인도 있긴 하다.
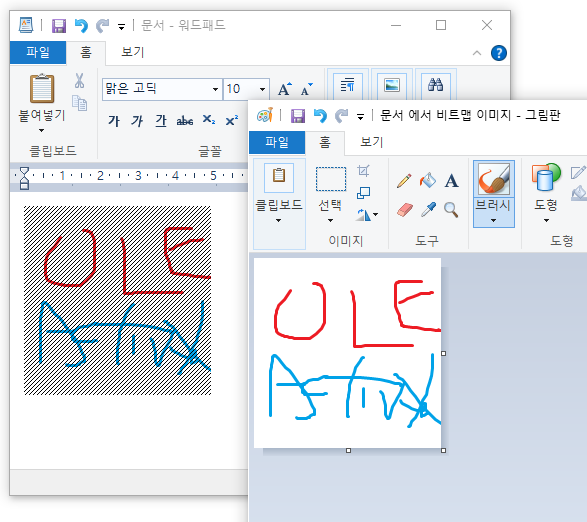
이런 것들이 다 20여 년 전의 아련한 추억이고 한물 간 유행이다.
그나저나 인터넷으로 ppt 슬라이드를 받으면 바로 열리지 않아서 불편하다. 속성을 꺼내서 ‘신뢰할 수 없는 파일 차단’을 해제해야 볼 수 있다. 이것도 chm 도움말 파일을 바로 열리지 않는 것처럼 보안 강화를 위해서 취해진 조치인지 모르겠다.
Posted by 사무엘


