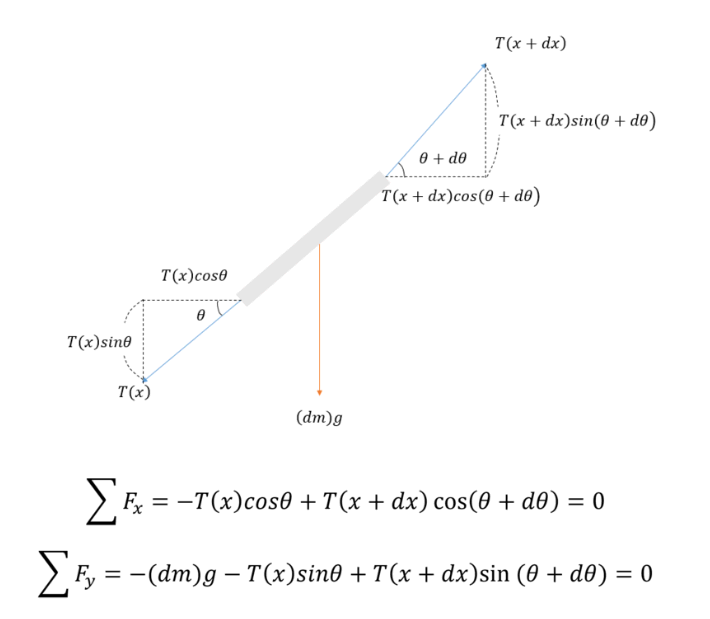
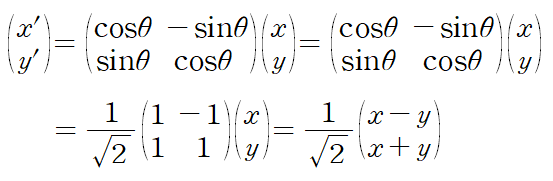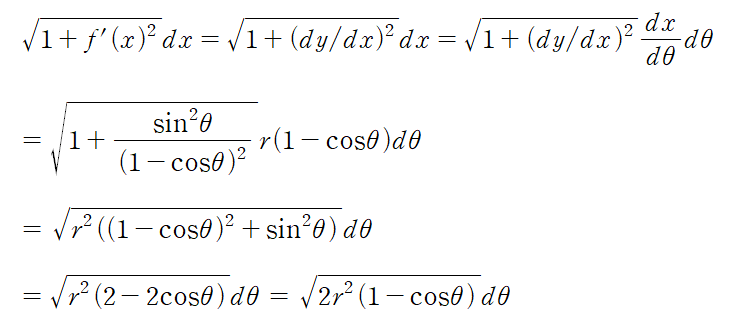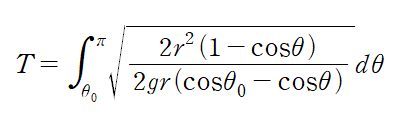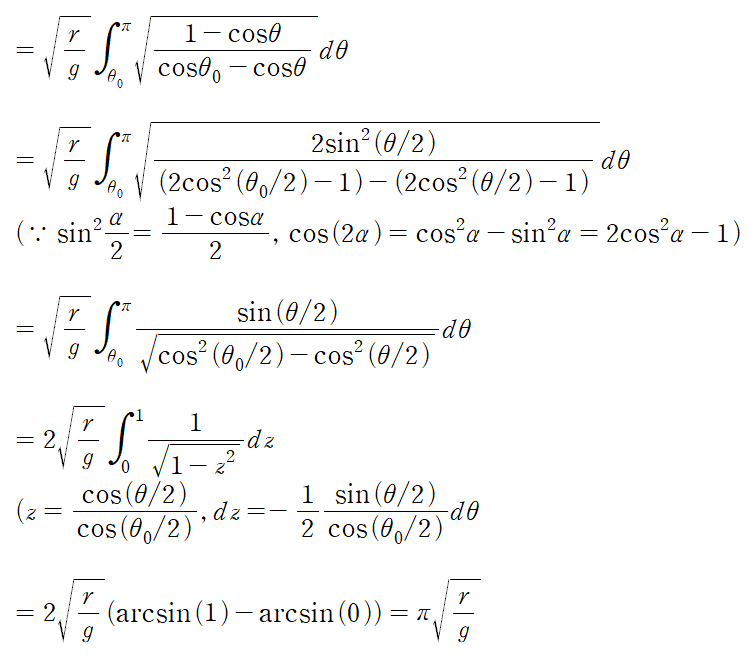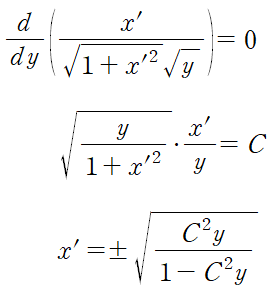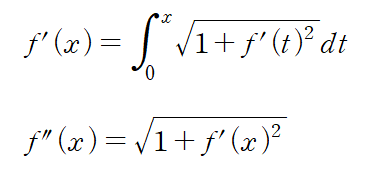1. 행렬의 기본연산
우리는 학교에서 방정식을 푸는 방법에 대해 배울 때, 등식에 대해 너무 당연해 보이는 원리를 배운다.
등식의 양변에 같은 수를 더하거나 빼거나 곱하거나, 나누더라도(비영) 등식은 성립한다는 거.
이건 사실 너무 당연한 얘기이다. 이미 값이 같은 두 수에다가 동일한 수로 동일한 연산을 하면 그 결과도 서로 일치할 수밖에 없다. 그런데 그 당연한 이치만 이용해서 복잡한 방정식을 푸는 게 수학의 묘미이다.
등식의 좌변과 우변을 마법 같이 변형하고 복잡한 항을 옮기거나 없애고, 궁극적으로 좌변에 x 하나만 남기니까 말이다.
그런데 행렬을 다루는 선형대수학으로 가면 이와 비슷한 방법론이 또 등장한다. 이른바 행렬을 줄 단위로 변형하는 기본 연산 말이다.
저 줄이라는 게 가로줄(row 행)인지 세로줄(col 열)인지는 중요하지 않다. 행렬에서 임의의 두 줄을 뽑아서 한 줄의 숫자를 그대로 또는 스칼라(상수)배 한 뒤, 다른 줄에다가 그대로 더해 준다. 두 벡터 A, B에 대해서 A = A + n*B 같은 셈이다.
행렬이라는 건 그냥 방정식이 아니라 변수도 여러 개, 식도 여러 개인 연립방정식을 풀기 위해 도입된 물건이다.
연립방정식을 풀기 위해서 우리가 하는 일은 식에서 변수를 하나씩 소거하는 것이다.
어떤 식은 x y z 변수가 모두 등장하지만 다음 식은 x를 소거하여 y z만 남기고, 마지막 식은 z만 남기고..
그러면 그 z를 y-z 식에다가 대입해서 y를 구하고, 이걸 x-y-z 식에다가 대입해서 x까지 모두 구하면 된다.
이 과정이 행렬로 치면 '삼각화'이다. 행렬이 나타내는 방정식의 특성(= 근)을 변형하지 않으면서 0이 아닌 숫자를 행렬의 반쪽에다가만 남기는 것이다.
그리고 그렇게 삼각화하는 수단이 바로 저 줄 단위 기본연산이다. 없애고 싶은 칸의 숫자를 스칼라배를 통해 동기화시키고 나서 빼 주면 그 칸은 0이 되어 소거된다.
행렬의 기본연산의 묘미는 바로..
한 줄 내용의 상수 배를 딴 줄에다가 아무리 더해 주더라도 행렬 내지 방정식의 전체 특성이 전혀 바뀌지 않는다는 것이다. 특히 그 행렬의 행렬식의 값이 변하지 않는다. 오로지 자기 자신을 상수 배 했을 때만 행렬식 값에도 그 배율이 반영된다.
왜? xyz축을 각각 가리키는 단위 벡터들을 생각해 보자. z축을 1만치 향하는 벡터에다가 완전히 다른 방향인 x, y축을 가리키는 벡터를 제아무리 더해 줘도 z축 방향은 영향을 받지 않는다.
커버하는 벡터 공간이 정육면체이던 것이 찌그러진 평행육면체가 될지언정, 그 육면체의 부피가 바뀌지는 않는다는 걸 생각하면 이해에 도움이 될 것이다. 오로지 z축 자체의 크기를 키워야만 육면체의 부피가 바뀔 것이다.
이 기본연산으로부터 유도 가능한 재미있는 특성이 또 있다.
행렬에서 서로 다른 임의의 두 줄을 맞바꾸는, 다시 말해 교환하는 것을 저 기본연산들의 조합으로 구현할 수 있다. 그리고 이렇게 교환을 하면 행렬식 값이 부호가 바뀐다.
- 임의의 두 줄 (A,B)가 있는데 먼저 A줄에다가 B줄 내용을 빼서 (A-B,B)를 만든다.
- 그 뒤 B에다가 지금 A줄의 값이 돼 있는 A-B를 더해 주면 B가 소거되어 (A-B,A)가 되고..
- A-B가 돼 있는 A줄에다가 지금 B줄의 값인 A를 빼면 (-B,A)가 된다.
- 이제 -B에다가 -1을 곱하면 (A,B)가 (B,A)로 교환이 완료되고.. 이때 행렬식의 부호도 -1이 곱해지면서 바뀐다. 이런 원리 때문이다. =_=;;
이 바닥에서는 피연산자의 순서가 바뀌면 결과의 부호가 달라지는 연산을 심심찮게 보는 것 같다. 벡터곱(외적)이라든가, 사원수 i,j,k끼리의 곱 같은 거 말이다. 행렬의 줄 교환 기본연산도 그런 축에 드는 셈이다.
2. 두 변수 교환
그리고 위의 저 로직은 컴퓨터 코딩깨나 하는 분들에게는 꽤 낯익을 것이다.
임시 변수를 사용하지 않고 두 변수 값을 맞바꾸는 swap 알고리즘과 개념적으로 일맥상통하기 때문이다. 즉, C 코드로 치면 아래 식을 적용한 거나 마찬가지이다. ㄲㄲㄲㄲㄲㄲㄲ
a -= b, b += a, a -= b; a=-a;
물론, 코딩을 할 때는 꼭 합성 대입 연산자에만 집착할 필요는 없으니, 피연산자의 배치 순서를 바꿔서 부호 전환을 축약시키곤 한다.
a += b, b = a-b, a = a-b;
덧셈과 뺄셈 대신, 곱셈과 나눗셈을 써도 되기는 한다. 그러나 이건 실용성이 최악이다.
그렇잖아도 임시 변수 안 쓰는 swap 자체가 실무에서는 딱히 쓰이지는 않고 "이런 테크닉도 있다" 수준으로 짚고 넘어가는 잉여이다. 근데 하물며 swap을 위해서 덧셈-뺄셈보다도 더 무거운 곱셈과 나눗셈이라고??
오버플로 가능성, 피연산자에 0이 있을 때의 문제, 부동소수점인 경우에는 오차 문제.. 정말 할 짓이 못 된다.
사실, 컴퓨터의 입장에서 이런 맞교환 용도로 덧셈· 뺄셈보다도 더 낫고 최고 적합한 연산자는 바로 비트 xor이다. 얘는 같은 피연산자를 두 번 적용하면 도로 원래 숫자로 돌아온다는 마법 같은 특성이 있기 때문이다. (A ^ B)^B = A 다시 말해 xor은 항등원이 0이고 역원은 걍 자기 자신.. 그래서 프로그래머라면 잘 아시다시피
a ^= b, b ^= a, a ^= b;
정말 매끄럽고 단순한 합성 대입 연산자 3방으로 swap이 바로 구현된다. 컴퓨터의 입장에서 xor은 산술 연산보다 속도도 더 빠르며, overflow 문제도 전무하니.. 가히 최적이다.
다만, 다시 얘기하지만 임시 변수 안 쓰는 swap은 실용성이 별로 없다.
연산이 병렬화 이념과 맞지 않으며, 실수로 a와 b에다 같거나 겹치는 메모리 주소를 줘서는 절대로 안 된다.
"하이고, swap 때 변수 하나 줄여 갖고 메모리 얼마나 절약했고 얼마나 팔짜 폈나? ㅋㅋㅋ" 이런 비아냥이 나올 만도 하다.
임시 변수 안 쓰는 swap의 자매품으로는..
O(1)을 초과하는 추가 메모리를 쓰지 않는 n log n 정렬 알고리즘(heap 정렬)이라든가 parent node가 없는 트리 자료구조를 생각할 수 있을 것 같다.
하지만 현실에서는 안정성 있는(stable) n log n인 merge sort라든가, 아예 n^2이지만 아주 가벼운 insert sort가 소규모 한정으로 선호된다. heap sort가 막 메리트가 있다고 여겨지지는 않고 있다.
그리고 parent node 없이 스스로 균형잡는 tree 자료구조의 삽입· 삭제를 구현하는 것 자체는 당연히 가능하다.
그러나 C++에서 제공하는 set, map 부류의 컨테이너들은 가벼운 포인터 기반의 iterator로 원소 순회 기능을 제공하다 보니.. 어차피 다들 node에다가 parent 포인터를 갖추고 있다.
이게 없으면 iterator가 자체적으로 스택을 가진(= 현 순회 상태를 저장) 복잡한 클래스가 돼야만 트리 내부를 순회할 수 있기 때문이다.
뭐, 노드 하나당 8바이트짜리 포인터 오버헤드가 추가됐다고 해서 요즘 세상에 컴퓨터가 메모리가 부족하다고 징징대지는 않는다. ^^
3. 여담
(1) 행렬 얘기를 하다가 프로그래밍 얘기가 너무 길어졌군..;;
아무튼 선형대수학에서 행렬을 다루는 기법을 보면 원소들을 쭉쭉 옮겨서 행렬을 \ 모양의 삼각형 형태로 가공하는 게 많다. 삼각형 모양이 된 행렬은 그 대각선상에 있는 원소만 쭈룩 곱하면 행렬식을 구할 수 있고 여러 모로 취급이 편하기 때문이다.
행렬식이나 역행렬을 구할 때는 행렬에다가 앞서 언급했던 기본연산을 적용하면서 행렬을 삼각화하게 된다. 그런데 이 과정을 기록으로 남겨서 원본 행렬을 아예 하삼각행렬과 상삼각행렬의 곱으로 일종의 분해를 할 수 있다. 단, 앞서 등장하는 하삼각행렬은 주대각 성분이 모두 1... 이걸 LU 분해라고 부른다.
(2) LU 분해 말고 PD(P^-1)이라는 세 형태로 행렬을 분해하는 더 어려운 기법도 나중에 다뤄진다. 이건 행렬의 고유값/고유벡터와 관계 있는 더 어려운 개념이어서 나중에 다뤄지는데.. 행렬식이 아니라 행렬의 거듭제곱을 단순한 형태로 표현하게 해 주는 아주 강력한 도구이다.
(a+b) 기호의 다항식을 n승 하면 항이 더덕더덕 늘어나는데, 이는 행렬도 마찬가지이다. 그런데 주대각성분에만 값이 붙어 있는 대각행렬은 n승 해도 항이 늘어나지 않고 마치 스칼라값처럼 자기 자신의 지수만 늘어난다.
PD(P^-1)은 행렬을 대각행렬 D를 포함한 형태로 분해하는 기법이다. 이에 대해서는 나중에 추가로 글로 정리하도록 하겠다.
(3) 임의의 a,b,c...꼴의 원소에 대해서 행렬의 곱셈뿐만 아니라 행렬식이나 역행렬을 구하는 일반적인 공식도 유도할 수는 있다. 그러나 행렬식 하나만 생각해 보면, n 크기 정사각행렬의 행렬식은 계수가 n인 항이 2n이나 n^2, 심지어 2^n개도 아니고 n!개씩 달라붙는다.;; 아시다시피 그 행렬식은 이전 n-1크기 행렬식들을 n개만치 더하고 쪼개는 걸 반복하는 형태로 재귀적으로 정의되기 때문이다.
그렇기 때문에 큰 행렬을 다룰 때 실무에서는 일반적인 공식은 사실상 의미를 갖지 않는다. 그냥 행렬에다 기본연산을 열나 적용한 뒤에 주대각 성분을 곱하고 말지. 이러면 O(n^3) 정도의 복잡도가 나온다. 얘들은 중간 계산 결과들이 저 복잡한 항의 개수를 줄여 주는 거나 마찬가지이다.
FM대로 재귀적으로 행렬식을 구하더라도 다이나믹 기법으로 이전 계산 결과를 적절히 저장하면 시간 복잡도를 팩토리얼에서 다항함수로 바꿀 수는 있을 것이다.
하지만 이건 쪼개진 sub행렬을 기술하는 게 생각보다 빡세고 쉽지 않다.;;; (직접 생각해 보면 이게 무슨 말인지 알 거임. ㄲㄲㄲㄲㄲ) 크기가 다양한 행렬들의 곱셈 횟수를 최소화하는 문제와는 상황이 좀 다르다. 그러니 이러나 저러나 FM은 실용성이 떨어진다는 건 어쩔 수 없어 보인다.
Posted by 사무엘