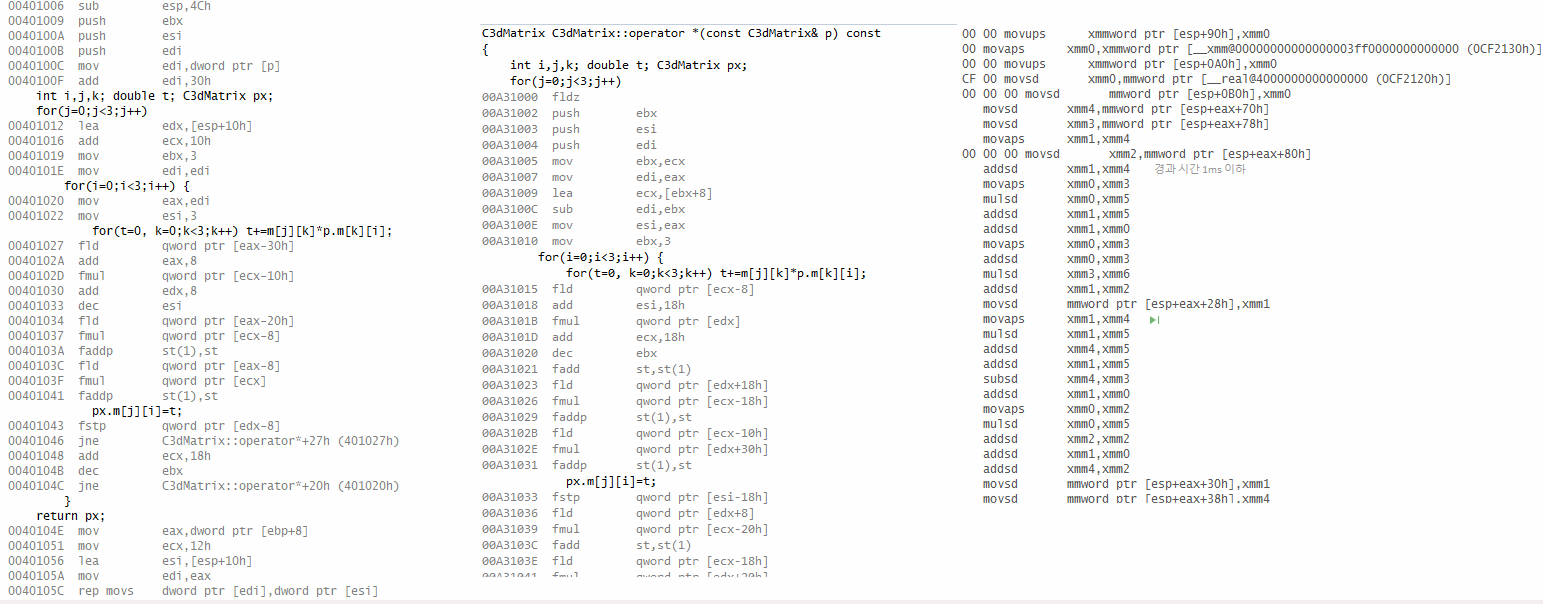
지금 올리는 이 글은 원래는 이전의 새 버전 소개 글과 같이 올라갔어야 했다.
하지만 이 내용까지 같이 저 때에 맞춰 넣어서 글을 완성할 여유가 도저히 없어서 부득이하게 글을 둘로 나누게 됐다. ㄲㄲㄲㄲ
뭐, 글을 쓰고 보니 분량이 워낙 길어진지라, 별도의 글로 분리한 게 다행히 더 좋은 모양새가 되긴 했다.
1. 타자연습: 히스토리 기능의 부재가 아쉬워
연습글별로 예전에 마지막으로 연습하던 위치를 기억하기, 그리고 제일 최근에 열어서 연습했던 연습글을 기억하기.
이건 지금까지 여러 사용자들께서 건의했으며 본인도 지원의 필요를 느끼고 있었고, 이번에 어지간해서는 같이 구현하려 했다. 어떤 형태로 구현할지에 대해서도 얼추 구상을 마쳤다.
하지만 이건 아쉽게도, 죄송하게도 이번 4.0에서 실현되지 못했다. 또 다음 버전을 기약해야 하게 됐다.
일단 지금 형태 있는 그대로라도 '64비트화'라는 거대한 0순위 과업이 생겼다 보니.. 신규 기능은 우선순위에서 밀렸다.
게다가 이건 아무래도 사용자의 계정에 새로운 데이터가 영구적으로 추가되는 '큰 기능'이다. 이걸 구현해 넣기에는 지금 프로그램의 로직, 계정 파일 포맷 등등이 마음에 안 들고 많이 구려서-_-;;;
이것부터 최적화하고 작업을 더 장기적인 안목을 보면서 하는 게 낫겠다는 결론을 내렸다.
지금 이 구조에서 저 기능만 간신히 넣는 건 너무 삽질스러워 보였다.;;
그래도 이번 4.0을 계기로 날개셋 타자연습도 오랜 겨울잠에서 깨어나고 먼지를 털어냈다.
이제 최신 개발 환경에서 신형 API나 최신 C++ 문법도 아무 제약 없이 쓰면서, 여건이 허락하는 한 프로그램을 계속해서 발전시켜 나갈 것이다.
2. 타자연습: 게임 음악 관련 불만
타자연습을 x64 환경으로 포팅하면서 알게 된 사실인데.. 마소는 64비트 Windows에서는 DirectMusic의 지원을 사실상 끊었다.
관련 인터페이스들을 다 싹 없앤 건 아니고 directmusic performance 계층만 없앴지만.. 이거 없앤 게 사실상 DMusic을 몽땅 없앤 거나 마찬가지이다.
도대체 왜??
아무리 waveform 음원이 대세이고 MIDI는 현업 게임들에서 도태됐다지만, 내 프로그램처럼 소규모 초저예산 게임에서는 미디 음악을 여전히 쓰기도 한다.
그럼 더 구닥다리인 MCI API로 돌아가리?
음악 음색도 안 좋고, 로딩 때 랙도 너무 심하고, 게다가 메모리에 로딩된 미디 데이터를 바로 재생하지 못하고 임시 파일을 써서 불러들였다가 도로 지우는 삽질.. 이건 도저히 쓸 게 못 되었다.
마소에서 미친 짓을 했으니, 나도 미친 짓을 하기로 했다.
음악만 별도의 32비트 호스트 exe로 따로 떼어내서 재생한 것.. 기능의 퀄리티 상으로 DirectMusic을 대체할 물건이 도저히 정말 전혀 없더라.
내가 프로그램을 이 따위로 비효율적으로 만들게 된 건 전적으로 마소 때문인 줄이나 알아라.
아울러, 내가 타자연습은 이 참에 ARM64용 빌드도 시험삼아 만들어 볼까 생각했으나.. 일단 보류했다.
사실상 x86 32비트에서밖에 못 쓰는 저 음악 문제도 있고, 그리고 Visual Studio의 설치 배포 프로젝트가 플랫폼을 여전히 x86, IA64, x64 셋 중 하나로밖에 지정을 못 하기 때문이다.
Windows on ARM 나온 지도 이미 수 년이 지나지 않았냐? 거기서는 msi를 도대체 어떻게 만드는지?
Visual Studio의 컴파일러 툴킷은 ARM64용이 있는데, 배포 프로젝트에는 저 플랫폼이 왜 없는 걸까?
이런 것도 마음에 안 든다. =_=;;
3. 입력기: 외부 모듈의 버그 신고
지금까지 마소 IME는 괜찮은데 내 프로그램만 한글 입력이 제대로 동작하지 않는다는 신고가 들어온 건 다음과 같다.
(1) LoL 게임=_=.. 신고 메일에 따르면 게임 중의 대화(?) 창에서는 한글 모드로 안 들어가고 영문만 입력되며.. 게임을 마치고 나온 대기 로비의 대화창에서는 한글 입력이 된다고 한다.
난 LoL을 전혀 하지 않고 프로그램 구조를 모르기 때문에 이에 대한 지원은 전혀 할 수 없다. 혹시 비슷한 현상을 겪는 분이 또 있으신지 제보를 기다린다. 스샷과 정확한 재연 방법도..
(2) 텔레그램 메신저, 그리고 AppFlowy라는 프로그램에서. 한글 입력이 덧난다거나, 한글 모드에서 입력하는 비한글 문자(세벌식 자판의 숫자, ※ 등)가 씹히고 제대로 입력되지 않는 현상이 있더라.
AppFlowy의 경우, 일반적인 입력란은 OK인데, 페이지를 하나 생성해서 제목 다음으로 본문을 입력하는 곳까지 갔을 때 오동작이 발생한다.
개인적으로는 응용 프로그램을 어떻게 만들어야 저런 오동작을 재연할 수 있는지 참 궁금하다만;;
아마 금방 쉽게 해결 가능한 문제는 아니어 보인다. 아마 해결된다면 저런 프로그램만을 위한 보정 동작이 추가될 가능성이 높다. 특히 (2) 같은 유형의 오동작 말이다.
(1)은 현재로서는 보안 프로그램으로 인한 통째로 차단이 의심된다.
아무쪼록 버그 신고를 한다면 날개셋 개발자는 그 프로그램에 대해 전~혀 모른다고 생각하고,
오동작이 일어나는 지점까지 모든 과정을 차근차근 알려주셔야 한다. 아무 입력란에서나 문제를 쉽게 재연할 수 있는 게 아니라면 말이다.
그 프로그램을 사용하기 위해서 무슨 가입, 계정 생성, 로그인 같은 게 필요한지도 안내가 필요하다.
4. Windows 최신 동향: IME 쪽
(1) 지난 몇 년 동안 Windows 동네에서는 한글 IME와 관련된 동작이 생각보다 많이 바뀌었다.
우와~~ composition의 모양이 검은 사각형이 아니라 밑줄로 바뀌었으며, capslock 같은 걸 눌러도 조합이 풀리지 않고 유지된다. 게다가 한글 조합 중에 ctrl+bksp를 눌러도 드디어 단어를 모두 지울 수 있다. (날개셋은 이전부터 이미 가능했음)
이런 건 긍정적인 변화인 것 같다. 여러 정황상 한글 IME의 동작을 중국· 일본어 IME의 동작에 맞춰 일치시킨 듯하다.
(2) Windows Terminal과 Google chrome 브라우저는 오랫동안, 지난 수 년 동안 내 프로그램 기준으로는 '보정'이 필요한 특이한 프로그램이었다.
그랬는데 지금 보니까 언제 고쳐졌는지 그 보정을 안 해도 별다른 오동작 없이 동작하도록 버그가 수정된 듯하다.
이제 그 보정 옵션은 특정 앱에 종속적인 다른 편의 기능을 제공하는 용도로 활용해도 될 것 같다.
(3) 전통적으로 한글 조합이 끝났을 때는 WM_IME_END_COMPOSITION이 오고 그 다음에 WM_IME_COMPOSITION이 뜬금없이 왔었다.
이거 30년 전 Windows 95 시절부터 변함없는 동작이었는데 이제는 후자 다음에 진짜 마지막으로 전자 END_COMPOSITION으로.. 논리적으로 맞게 바뀌었다.
이것도 긍정적인 변화이긴 하지만.. 일부 저 잘못된 동작에 딱 맞춰 동작하는 소수의 프로그램에서 오동작을 일으키는 건 어쩔 수 없다.
조합 모양과 저런 자잘한 동작들을.. 날개셋도 옵션 형태로 조만간 수용하고 업데이트 해야 할 것으로 보인다.
5. Windows 최신 동향: 나머지
(1) 언제부턴가 날개셋 한글 입력기에서 제공되는 필기 인식 기능이 동작하지 않고 있다.
Windows 10/11의 어느 빌드에서부터 내 프로그램이 지원하는 방식인 필기 인식 라이브러리를 빼 버렸다. 그건 구버전 레거시로 치부하고 자기들은 또 다른 새로운 인터페이스로 갈아탄 것 같다. 나름 이것도 Windows Vista 때부터 있던 인터페이스인데..
어휴~ 이건 또 어찌 대응 가능할지 모르겠다. 금방 되기는 어려울 듯..
(2) 그리고 win 10/11 초창기에 비해 현재는 이모지의 렌더링 속도가 엄청나게 느려졌다. 내 프로그램에서 이모지 문자표를 꺼내 보면 창이 뜨고 목록이 스크롤되는 게 무진장 굼뜨는 걸 알 수 있다.
운영체제에서 제공하는 컬러 이모지 폰트가 더 정교해지고 복잡해져서 그런 것 같은데.. 내 프로그램에서 이모지를 실시간으로 점진적으로 표기하고, 한번 표시한 이모지의 비트맵을 캐싱하는 식으로 UI와 성능을 개선해야 할 듯하다.
(3) 지난 Windows 11 2022년쯤 버전부터 운영체제의 인쇄 대화상자가 새끈하게, 혹은 이상하게 바뀌었다. 이게 싫다면서 다시 익숙한 옛날 클래식 대화상자로 되돌려 달라는 청원도 많으나, 마소에서는 들을 생각이 없는 듯하다.
새 대화상자는 아시다시피 인쇄 미리보기가 한데 통합도 돼 있다. 이걸 지원하려면 응용 프로그램이 Windows 11의 새로운 인터페이스를 구현해 줘야 하는데..
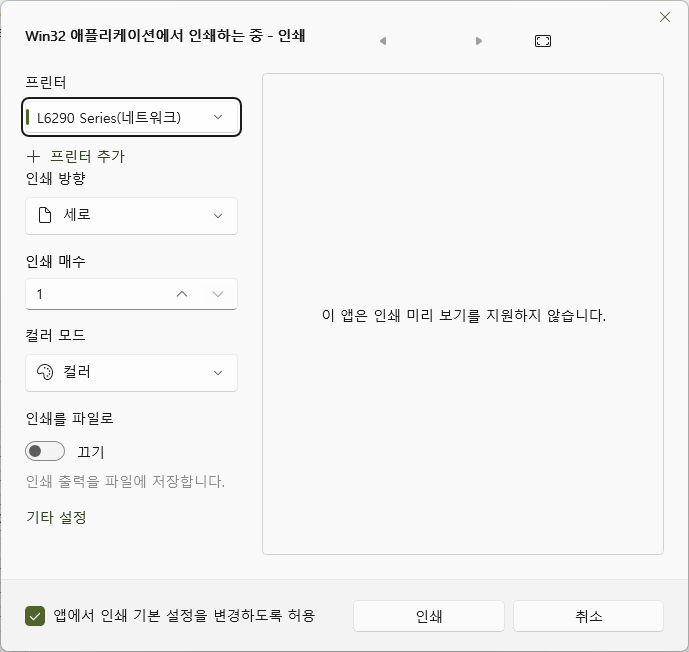
문제는 본인은 저걸 지원하는 프로그램, 인쇄 미리보기가 나오는 프로그램을 지금까지 단 하나도 못 봤다. 심지어 메모장이나 그림판처럼 마소 자기들이 만든 프로그램조차도 저걸 지원하지 않으니 도대체 뭐 어쩌라는 건지 궁금해진다.;;;
아마 날개셋 편집기도 이 대화상자를 미리보기까지 정식 지원하는 건 하루아침에 금방 될 것 같지 않다. 개발 우선순위가 아주 낮다. ㄲㄲㄲㄲㄲ
(4) 영문 Qwerty 글쇠배열의 대안으로 드보락이 오랫동안 유명했다. 그러나 2010년대쯤부터는 콜맥이 드보락의 지위를 위협하는 지경에 도달한 것 같다. 본인은 날개셋에서 세벌식과 콜맥을 같이 사용 중이라는 사용자 피드백을 지금까지 굉장히 많이 받았다.
콜맥이 얼마나 유명해졌으면 Windows 11 언제부턴가 콜맥 키보드 드라이버도 내장되어서 정식으로 지원되기 시작했다.
콜맥은 숫자· 기호가 기존 쿼티와 일치하고 이질감도 덜하다는 게 장점인 것 같다. 쿼티와는 완전히 다른 드보락과 다른 점이다.
(5) 이 와중에 요즘 Windows에서는 워드패드가 퇴출돼 버렸다.
mac의 TextEdit나 리눅스의 gedit는 서식 있는 텍스트(간편 워드 프로세서)와 plain text를 동시에 취급할 수 있다. Windows 메모장은 그렇지 않은데 왜 워드패드를 없앴는지.. 이것도 참 이해할 수 없는 일이다. 마소 Word의 축소판 같은 대안이 있는 것도 아닌데 말이다.
RTF는 원래 규격이 그렇게 정의돼 있는지 모르겠다만, 그닥 유니코드 친화적이지 않다. 한중일 2바이트 문자는 몽땅 다 \' 라는 탈출문자와 함께 16진수 바이트 시퀀스 형태로 바꿔서 표시하게 돼 있다.;; 이 때문에 한글· 한자가 들어간 rtf는 실제 용량보다 덩치가 굉장히 커진다.
'코드 번호로 변환' 텍스트 필터에는 C언어 정수 및 문자 리터럴, URL 등 여러 known prefix를 제공하고 있는데, 다음 버전에서는 RTF의 저 prefix도 추가할 예정이다. Windows에서 워드패드가 사라진 와중에 RTF 파일을 읽는 데 도움이 되라고 말이다.
Posted by 사무엘