C/C++은 성능을 위해 컴파일러나 언어 런타임이 프로그래머의 편의를 위해 뭔가를 몰래 해 주는 것을 극도로 최소화한 언어이다. 꾸밈 없고 정제되지 않은 '날것 상태 raw state'에다가 고급 프로그래밍 언어의 패러다임과 문법만을 얹은 걸 추구하다 보니, '초기화되지 않은 쓰레기값'이라는 게 존재하는 거의 유일한 언어이기도 하다.
같은 프로그램이라도 이제 막 선언된 변수나 할당된 메모리 안에 무슨 값이 들어있을지는 컴퓨터 운영체제의 상태에 따라서 그때 그때 달라진다. 반드시 0일 거라는 보장은 전혀 없다. 오히려 0 초기화는 별도의 CPU 부담이 필요한 인위적인 작업이다. global/static에 속하는 메모리만이 무조건적인 0 초기화가 보장된다.
그렇다고 쓰레기값이라는 게 완벽하게 예측 불가이면서 통계적인 질서를 갖춘 난수인 것도 물론 아니다.
그리고 Visual C++에서 프로그램을 debug 세팅으로 빌드하면 쓰레기값이라는 게 크게 달라진다. C++ 개발자라면 이 사실을 이미 경험적으로 충분히 알고 있을 것이다.
1. 갓 할당된 메모리의 기본 쓰레기값: 0xCC(스택)와 0xCD(힙)
가장 먼저, 스택에 저장되는 지역변수들은 자신을 구성하는 바이트들이 0xCC로 초기화된다. 다시 말해 디버그 빌드에서는 int x,y라고만 쓴 변수는 int x=0xCCCCCCCC, y=0xCCCCCCCC와 얼추 같게 처리된다는 것이다. 디스어셈블리를 보면 의도적으로 0xCC를 대입하는 인스트럭션이 삽입돼 들어간다.
0은 너무 인위적이고 유의미하고 깔끔한(?) 값 그 자체이고, 그 근처에 있는 1, 2나 0xFF도 자주 쓰이는 편이다. 그에 비해 0xCC는 형태가 단순하면서도 현실에서 일부러 쓰일 확률이 매우 낮은 값이다. 그렇기 때문에 여기는 초기화되지 않은 쓰레기 영역이라는 것을 시각적으로 곧장 드러내 준다.
int a[10], x; a[x]=100; 같은 문장도 x가 0으로 깔끔하게 자동 초기화됐다면 그냥 넘어가지만, 기괴한 쓰레기값이라면 곧장 에러를 발생시킬 것이다.
또한, 복잡한 클래스의 생성자에서 값이 대입되어 초기화된 멤버와 그렇지 않은 멤버가 뒤섞여 있을 때, 0xCC 같은 magic number는 탁월한 변별력을 발휘한다.
타겟이 align을 꼼꼼하게 따지는 아키텍처라면, 쓰레기값을 0x99나 0xDD 같은 홀수로 지정하는 것만으로도 초기화되지 않은 포인터 실수를 잡아낼 수 있다. 32비트에서 포인터값의 최상위 비트가 커널/사용자 영역을 분간한다면, 최하위 비트는 align 단위를 분간할 테니 말이다. 뭐 0xCC는 짝수이다만..
0xCC라는 바이트는 x86 플랫폼에서는 int 3, 즉 breakpoint를 걸어서 디버기의 실행을 중단시키는 명령을 나타내기도 한다. 그래서 이 값은 실행 파일의 기계어 코드에서 align을 맞추기 위해 공간만 차지하는 잉여 padding 용도로 위해 듬성듬성 들어가기도 한다.
Visual C++ 6 시절엔 거기에 말 그대로 아무 일도 안 하는 nop를 나타내는 0x90이 쓰였지만 2000년대부터는 디버깅의 관점에서 좀 더 유의미한 작용을 하는 0xCC로 바뀐 듯하다. 정상적인 상황이라면 컴퓨터가 이 구역의 명령을 실행할 일이 없어야 할 테니까..
다만, 힙도 아니고 스택 지역변수의 내용이 데이터가 아닌 코드로 인식되어 실행될 일이란 현실에서 전혀에 가깝게 없을 테니, 0xCC는 딱히 x86 기계어 코드를 의식해서 정해진 값은 아닐 것으로 보인다.
Visual C++의 경우, 스택 말고 malloc이나 new로 할당하는 힙(동적) 메모리는 디버그 버전에서는 내용 전체를 0xCD로 채워서 준다. 0xCC보다 딱 1 더 크다. 아하~! 이 값도 평소에 디버그 하면서 많이 보신 적이 있을 것이다.
힙의 관리는 컴파일러 내장이 아니라 CRT 라이브러리의 관할로 넘어기도 하니, 0xCD라는 값은 라이브러리의 소스인 dbgheap.c에서도 _bCleanLandFill이라는 상수명으로 확인할 수 있다.
2. 초기화되지 않은 스택 메모리의 사용 감지
C/C++ 언어는 지역변수의 값 초기화를 필수가 아닌 선택으로 남겨 놓았다. 그러니 해당 언어의 컴파일러 및 개발툴에서는 프로그래머가 초기화되지 않은 변수값을 사용하는 것을 방지하기 위해, 디버그용 빌드 한정으로라도 여러 안전장치들을 마련해 놓았다.
그걸 방지하지 않고 '방치'하면 같은 프로그램의 실행 결과가 debug/release별로 달라지는 것을 포함해 온갖 골치아픈 문제들이 발생해서 프로그래머를 괴롭히게 되기 때문이다.
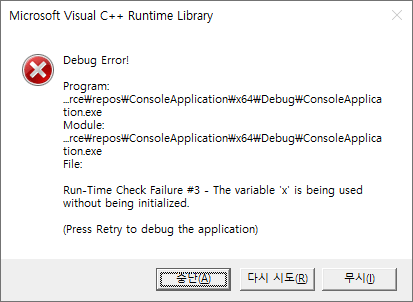
int x; printf("%d", x);
이런 무식한 짓을 대놓고 하면 30년 전의 도스용 Turbo C에서도 컴파일러가 경고를 띄워 줬다. Visual C++의 에러 코드는 C4700. 그랬는데 한 Visual C++ 2010쯤부터는 이게 경고가 아니라 에러로 바뀌었다.
그리고 그 뿐만이 아니다.
int x;
if( some_condition_met(...)) x=0;
printf("%d", x);
이렇게 문장을 약간만 꼬아 놓으면 초기화를 전혀 안 하는 건 아니기 때문에 컴파일 과정에서의 C4700을 회피할 수 있다. 하지만 보다시피 if문의 조건이 충족되지 않으면 x가 여전히 초기화되지 않은 채 쓰일 수 있다. 이건 정적 분석 정도는 돌려야 감지 가능하다.
(그런데, 글쎄.. 함수의 리턴이 저런 식으로 조건부로 불완전하게 돼 있으면 컴파일만으로도 C4715 not all control paths return value 경고가 뜰 텐데.. 비초기화 변수 접근 체크는 그 정도로 꼼꼼하지 않은가 보다.)
Visual C++은 /RTC라고 디버그용 빌드에다가 run-time check라는 간단한 검사 기능을 추가하는 옵션을 제공한다. 함수 실행이 끝날 때 스택 프레임 주변을 점검해서 버퍼 오버런을 감지하는 /RTCs, 그리고 지역변수를 초기화하지 않고 사용한 것을 감지하는 /RTCu.
저 코드를 Visual C++에서 디버그 모드로 빌드해서 실행해서 if문이 충족되지 않으면 run-time check failure가 발생해서 프로그램이 정지한다. 다만, 이 메모리는 초기화만 되지 않았을 뿐 접근에 법적으로 아무 문제가 없는 스택 메모리이다. 할당되지 않은 메모리에 접근해서 access violation이 난 게 아니다. 심각한 시스템/물리적인 오류가 아니라 그저 의미· 논리적인 오류이며, 쓰기를 먼저 하지 않은 메모리에다가 읽기를 시도한 게 문제일 뿐이다.
그러니 이 버그는 해당 메모리 자체에다가 시스템 차원의 특수한 표식을 해서 잡아낸 게 아니며, 논리적으로 매우 허술하다. (0xCC이기만 하면 무조건 스톱.. 이럴 수도 없는 노릇이고!)
문제의 코드에 대한 디스어셈블리를 보면 if문이 만족되지 않으면 printf으로 가지 않고 그냥 곧장 RTC failure 핸들러를 실행하게 돼 있다.
void do_nothing(int& x) {}
int x; do_nothing(x); printf("%d", x);
그렇기 때문에 요렇게만 해 줘도 RTC를 회피하고 x의 쓰레기값을 얻는 게 가능하다. 글쎄, 정교한 정적 분석은 이것도 지적해 줄 수 있겠지만, 포인터가 등장하는 순간부터 메모리 난이도와 복잡도는 그냥 하늘로 치솟는다고 봐야 할 것이다.
하물며 처음부터 포인터로만 접근하는 힙 메모리는 RTC고 뭐고 아무 안전 장치가 없다. int *p에다가 new건 malloc이건 값이 하나 들어간 것만으로도 초기화가 된 것이거늘, 그 주소가 가리키는 p[0], p[1] 따위에 쓰레기값(0xCD)이 있건 0이 있건 알 게 무엇이겠는가????
나도 지금까지 혼동하고 있었는데, 이런 run-time check failure는 run-time error와는 다른 개념이다. 순수 가상 함수 호출 같은 건 C/C++에 존재하는 얼마 안 되는 run-time error의 일종이고 release 빌드에도 포함돼 들어간다. 하지만 RTC는 debug 빌드 전용 검사이다.
그러니 버퍼 오버런을 감지하는 보안 옵션이 /RTC만으로는 충분하지 않고 /GS가 따로 있는 것이지 싶다. /GS는 release 빌드에도 포함돼 있으며, 마소에서는 보안을 위해 모든 프로그램들이 이 옵션을 사용하여 빌드할 것을 권하고 있다.
3. 해제된 힙 메모리: 0xDD(CRT)와 0xFEEE(???)
일반적인 프로그래머라면 동적으로 할당받은 힙 메모리를 free로 해제했을 때, 거기를 가리키는 메모리 영역이 실제로 어떻게 바뀌는지에 대해 생각을 별로 하지 않는다. 사실, 할 필요가 없는 게 정상이기도 하다.
우리 프로그램은 free를 해 준 주소는 신속하게 영원히 잊어버리고, 그 주소를 보관하던 포인터는 NULL로 바꿔 버리기만 하면 된다. free 해 버린 주소를 또 엿보다가는 곧바로 메모리 에러라는 천벌을 받게 될 것이다.
그런데 실제로는, 특히 디버그 모드로 빌드 후 프로그램을 디버깅 중일 때는 free를 한 뒤에도 해당 메모리 주소가 가리키는 값을 여전히 들여다볼 수 있다. 들여다볼 수 있다는 말은 *ptr을 했을 때 access violation이 발생하지 않고 값이 나온다는 것을 의미한다.
이 공간은 나중에 새로운 메모리 할당을 위해 재사용될 수야 있다. 하지만 사용자가 디버깅의 편의를 위해 원한다면 옵션을 바꿔서 재사용되지 않게 할 수도 있다. (_CrtSetDbgFlag(_CRTDBG_DELAY_FREE_MEM_DF) 호출)
뭐, 메모리를 당장 해제하지 않는다고 해서 free 하기 전의 메모리의 원래 값까지 그대로 남아 있지는 않는다. Visual C++의 디버그용 free/delete 함수는 그 메모리 블록의 값을 일부러 0xDD (_bDeadLandFill)로 몽땅 채워 넣는다. 여기는 할당되었다가 해제된 영역임을 이런 식으로 알린다는 것이다.
실제로, free된 메모리가 곧장 흔적도 없이 사라져서 애초에 존재하지도 않았던 것처럼 접근 불가 ?? 로 표시되는 것보다는 0xDD라고 디버거의 메모리 창에 뜨는 게 dangling pointer 디버깅에 약간이나마 더 도움이 될 것이다. 이 포인터가 처음부터 그냥 쓰레기값을 가리키고 있었는지, 아니면 원래는 valid하다가 지칭 대상이 해제되어 버린 것인지를 분간할 수 있으니 말이다.
그런데 본인은 여기서 개인적으로 의문이 들었다.
본인은 지난 20여 년에 달하는 Visual C++ 프로그래밍과 메모리 문제 디버깅 경험을 떠올려 봐도.. 갓 할당된 쓰레기값인 0xCC와 0xCD에 비해, 0xDD를 본 적은 전혀 없는 건 아니지만 매우 드물었다.
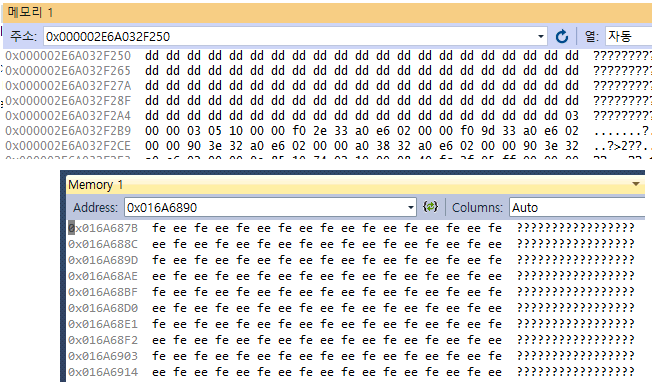
dangling pointer가 가리키는 메모리의 값은 0xD?보다는 0xF?였던 적이 훨씬 더 많았다. 더 구체적으로는 2바이트 간격으로 0xFEEE (0xEE, 0xFE)이다.
인터넷 검색을 해 보니.. 이건 놀랍게도 CRT 라이브러리가 채워 넣는 값이 아니었다. free/delete가 궁극적으로 호출하는 Windows API 함수인 HeapFree가 메모리를 정리하면서 영역을 저렇게 바꿔 놓았었다. 더구나 CRT에서 0xDD로 먼저 채워 넣었던 영역을 또 덮어쓴 것이다.
이 동작에 대해서 놀라운 점은 저게 전부가 아니다.
(1) 0xFEEE 채우기는 프로그램을 Visual C++ 디버거를 붙여서(F5) 실행했을 때만 발생한다. debug 빌드라도 디버거를 붙이지 않고 그냥 Ctrl+F5로 실행하면 0xFEEE가 생기지 않는다. 그리고 release 빌드라도 디버거를 붙여서 실행하면 0xFEEE를 볼 수 있다.
(2) 더 놀라운 점은.. 내가 집과 직장 컴퓨터를 통틀어서 확인한 바로는 저 현상을 볼 수 있는 건 Visual C++ 2013 정도까지이다. 2015부터는 debug 빌드를 디버거로 붙여서 돌리더라도 0xFEEE 채움이 발생하지 않고 곧이곧대로 0xDD만 나타난다~!
운영체제가 정확하게 어떤 조건 하에서 0xFEEE를 채워 주는지 모르겠다. 인터넷 검색을 해 봐도 정확한 정보가 나오는 게 의외로 없다.
하필 Visual C++ 2015부터 저런다는 것은 CRT 라이브러리가 Universal CRT니 VCRuntime이니 하면서 구조가 크게 개편된 것과 관계가 있지 않으려나 막연히 추측만 해 볼 뿐이다.
여담이지만 HeapAlloc, GlobalAlloc, LocalAlloc은 연달아 호출했을 때 돌아오는 주소의 영역이 그리 큰 차이가 나지 않으며, 내부 동작 방식이 모두 비슷해진 것 같다. 물론 뒤의 global/local은 fixed 메모리 할당 기준으로 말이다.
4. 힙 메모리 영역 경계 표시용: 0xFD와 0xBD
0xCD, 0xDD, (0xFEEE) 말고 heap 메모리 주변에서 볼 수 있는 디버그 빌드용 magic number 바이트로는 0xFD _bNoMansLandFill와 0xBD _bAlignLandFill가 더 있다.
얘들은 사용자가 요청한 메모리.. 즉, 0xCD로 채워지는 그 메모리의 앞과 뒤에 추가로 고정된 크기만큼 채워진다. Visual C++ CRT 소스를 보면 크기가 NoMansLandSize인데, 값은 4바이트이다. 사용자가 요청한 메모리 크기에 비례해서 채워지는 0xCD와 0xDD에 비하면 노출 빈도가 아주 작은 셈이다. 특히 0xBD는 0xFD보다도 더욱 듣보잡인 듯..
애초에 얘는 사용자가 건드릴 수 있거나 건드렸던 공간이 아니며 그 반대이다. 사용자는 0xCD로 채워진 공간에다가만 값을 집어넣어야지, 앞뒤 경계를 나타내는 0xFD를 건드려서는 안 된다.
CRT 라이브러리의 디버그용 free/delete 함수는.. 힙을 해제할 때 이 0xFD로 표시해 놨던 영역이 값이 바뀌어 있으면 곧장 에러를 출력하게 돼 있다.
그리고 예전에 메모리를 해제해서 몽땅 0xDD로 채워 놨던 영역도 변조된 게 감지되면 _CrtCheckMemory 같은 디버깅 함수에서 곧장 에러를 찍어 준다. 그러니 0xDD, 0xFD, 0xBD는 모두 오류 검출이라는 용도가 있는 셈이다. 0xCC와 0xCD 같은 쓰레기값 영역은 쓰지도 않고 곧장 읽어들이는 게 문제이지만, 나머지 magic number들은 건드리는 것 자체가 문제이다.
그리고 얘들은 heap 메모리를 대상으로 행해지는 점검 작업이다. 이런 것 말고 스택 프레임에다가 특정 magic number를 둬서 지역변수 배열의 overflow나 복귀 주소 변조를 감지하는 것은 별도의 컴파일러 옵션을 통해 지원되는 기능이다. 요것들은 힙 디버그 기능과는 별개이며, 보안 강화를 위해 release 빌드에도 포함되는 게 요즘 추세이다.
이상이다.
파일 포맷 식별자 말고 메모리에도 디버깅을 수월하게 하기 위해 쓰레기값을 가장한 이런 특수한 magic number들이 쓰인다는 게 흥미롭다. Windows의 Visual C++ 외의 다른 개발 환경에서는 디버깅을 위해 어떤 convention이 존재하는지 궁금해진다.
사실, 16진수 표기용인 A~F에도 모음이 2개나 포함돼 있고 생각보다 다양한 영단어를 표현할 수 있다. 거기에다 0을 편의상 O로 전용하면 모음이 3개나 되며, DEAD, FOOD, BAD, FADE, C0DE 정도는 거뜬히 만들어 낸다. 거기에다 FEE, FACE, FEED, BEEF 같은 단어도.. 유의미한 magic number나 signature를 고안하는 창의력을 발산하는 데 쓰일 수 있다.
그러고 보니 아까 0xFEEE도 원래 free를 의도했는데 16진수 digit에 R은 없다 보니 불가피하게 0xFEEE로 대충 때운 건지 모르겠다.
Posted by 사무엘