1. 플랫폼 공통 스크립트
(1) qt가 단일 소스로 Windows, 리눅스, 맥에서 모두 똑같이 돌아갈 수 있는 GUI 프레임워크라면..
cmake는 단일 스크립트로 Visual Studio 프로젝트, 유닉스 계열 makefile, 그리고 xcode 프로젝트를 모두 생성해 주는 메타빌드 시스템이다.
그렇다면 qt를 사용해서 프로그램을 개발하고, 프로젝트 파일을 cmake로 관리한다면 진정한 크로스플랫폼 프로젝트를 만들 수 있을 것 같다. ㄲㄲㄲ
(2) 다음으로, 단일 소스/스크립트 기반으로 세 운영체제에서 똑같이 돌아가는 설치· 배포 패키지 생성 유틸은 없는지 궁금하다.
cmake(메타빌드)와 nsis(설치· 배포)는 스크립트 언어가 완전히 같은 문법 기반은 아니지만 좀 비슷하고 공통 조상을 둔 게 있는 것 같다.
얘들은 전문적인 프로그래밍 언어가 아니기 때문에 복잡한 수식에 복잡한 객체 선언, 배배 꼬인 복잡한 조건 분기 반복을 구현할 수는 없다는 공통점이 있다. 그리고 변수는 $로 시작해서 선언하고, 문자열 리터럴 안에다가 변수값을 바로 집어넣을 수 있다는 것도 비슷하다.
시대에 좀 뒤떨어지는 설치 배포 패키지는 고해상도 DPI를 지원하지 않는 경우가 있어서 좀 안습하다. 125~150% 배율 화면에서 설치 프로그램부터가 강제 확대되는 바람에 창이 뿌옇게 표시되면.. 정작 프로그램 당사자가 고해상도 DPI를 지원한다 해도 그 프로그램의 첫 사용 경험이 좋게 시작될 수 없을 테니 말이다. 본인은 이런 사례를 몇 번 본 적이 있다.
2. C/C++ 컴파일러
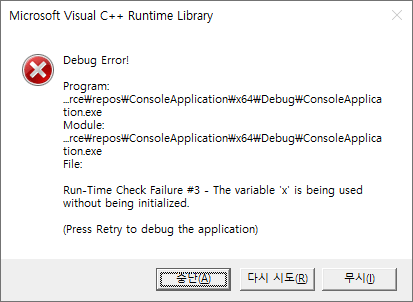
Windows용으로 쓸 만한 좀 가벼운 C/C++ 컴파일러가 없는지 좀 궁금하다.
- 용량은 그냥 수십 MB 수준이며, 단독으로는 그냥 표준 C/C++ 라이브러리만 들어있고 명령 프롬프트 프로그램만 만들 수 있다.
- MFC 같은 건 없어도 되고, 그냥 따로 설치한 플랫폼 SDK와 연계하면 Windows API 정도는 사용할 수 있다.
- 프로젝트 없이 간단한 소스 코드 하나만으로 exe를 바로 만들 수 있다.
- 특히 Visual Studio Code와 바로 연계해서 쓸 수 있다.
Visual C++은 정말 너무 무거워졌고.. Windows용 g++인지 뭔지는 런타임인 cygwin 깔고 이것저것 선행 작업이 많이 필요해서 무겁긴 마찬가지이다.
이렇게 딱 본질에만 충실한 개발 환경을 어디 구할 데 없을까? 개발툴이 무거워지는 건 인스턴트 메신저 프로그램들이 수익성 컨텐츠 집어넣느라 쓸데없이 너무 무거워지는 것과 비슷해 보인다.
요즘은 웹에서 어지간한 프로그래밍 언어들을 바로 코딩하고 돌려볼 수는 있다. 하지만 웹에서의 코딩 환경은 로컬 IDE와 같은 급으로 인텔리센스 자동 완성이 지원되지는 못하니 생산성이 떨어진다.
옛~~날에 요런 틈새시장 용으로 Dev C/C++라는 물건이 있었던 걸로 기억한다. IDE와 컴파일러 복합이었고, 개발사의 이름에 blood라는 단어가 있었는데=_=.. 그 뒤로 개발이 중단된 듯하다.
3. Visual Basic
Visual Basic 6은 사법시험 같고, Visual Basic .NET은 로스쿨 같다는 생각이 든다. 이렇게만 말하면 무슨 뜻인지 아시려나..?? 내가 보기엔 딱 그렇다. -_-;;
참고로, Visual Studio 툴 자체를 설치하지 않더라도, 닷넷용 언어들의 커맨드라인 컴파일러는 .NET 프레임워크를 설치하면 깔린다.
그러니 Windows에서는 리눅스처럼 gcc g++은 없지만, Windows\Microsoft .NET\아무 버전.. 디렉터리 가 보면
vbc (비베), csc (C#) 컴파일러는 어느 컴에나 다 있다.
그런데 C/C++ 컴파일러는 없으니 아쉽다. 비베는.. 6이건 .NET이건 실무 용도가 있기는 한지 개인적으로 궁금하다.
4. git
이놈의 git은 그냥 commit이나 push를 하기 전에 미리 "지금 원격 저장소에는 또 최신 작업 내역이 있는데요. pull부터 먼저 하시겠습니까?" 이렇게 말이다.
커밋할 때부터 지금 중앙 저장소의 상태가 최신이 아니니까 미리 니 쪽에서 pull부터 하고 나서 커밋 하는게 좋겠다고 좀 알려줬으면 좋겠다.
맨날 push할 때 충돌 난다고 뒤늦게 징징대서 사람 귀찮게 하지 말고 말이다. 이러면 commit 그래프도 일직선이 아니라 더 지저분한 모양이 된다. 이건 시스템이 좀 개선돼야 할 것 같다.
5. Visual Studio Code
오~ 써 보니 사용자 경험이 좋고 꽤 괜찮다!!
빌드 가능할 정도로 정교하게 프로젝트/makefile을 세팅할 필요 없이 디렉터리만 지정해 주면, 거기 있는 소스와 헤더 파일을 알아서 '적당히' 파싱 해서 심벌과 파일명 검색, 명칭 자동 완성이 가능한 범언어적 에디터.
요런 틈새시장 제품이 Source Insight밖에 없는 줄 알았는데 말이다. 쟤도 그 틈새를 멋지게 잘 공략했다.
외형 껍데기가 깔끔 모던하고, 파일 내용 변경한 게 find in files 결과창 같은 데에 실시간으로 쓱쓱 반영되는 것도 좋다.
마구 마구 아이디어가 샘솟고 코딩을 하고 싶어진다.
걍 Visual Studio IDE만 쓰면 되지 에디터가 굳이 따로 필요하나 소신이었는데, 이 정도 에디터면 프로그래밍 생산성에도 긍정적인 영향을 줄 것 같다.
Source Insight는 유료인 반면, 쟤는 무료이기까지 하다. Source Insight 측에서 분발해야 할 듯.
6. 궁금한 것: 공유 라이브러리 디렉터리
Windows에는 프로그램의 빌드 때만 쓰이는 정적 라이브러리인 lib, 그리고 프로그램이 실행될 때 매번 쓰이는 동적 라이브러리 dll이 있다. dll을 찾는 순서로는 현 디렉터리, 실행 파일이 있는 디렉터리, Windows 시스템 디렉터리, PATH에 등록된 디렉터리 등.. 여러 복잡한 절차가 존재한다.
시스템 디렉터리의 포화를 막고 DLL hell 현상도 해소하려고 20년도 더 전에 side-by-side assembly라는 기법이 도입되긴 했다. 하지만 사용이 너무 까다로워서 그런지 이건 마소 자기들끼리만 쓰고 제3자 개발자들은 잘 쓰지 않는 것 같다.
그리고 COM이야.. 파일 이름이나 디렉터리 같은 저수준 방식이 아니라 객체의 클래스ID로 DLL을 식별하는 거나 마찬가지이다. 깔끔하기는 하지만 레지스트리를 건드려야 하고 다른 방식으로 사용이 너무 까다롭고 복잡하다.
이미 COM을 기반으로 만들어진 DirectX, OLE 같은 특정 분야의 API를 사용할 때나 이걸 쓰지, 얘 방식으로 뭔가 새로운 컴포넌트를 만드는 일은 잘 없다. =_=;;
자, Windows 동네는 상황이 이렇고, 유닉스 계열에서는 이와 비슷한 개념으로 정적 라이브러리 a와 동적 라이브러리 so가 있는 걸로 안다. 그리고 내가 알기로, 거기도 so를 특정 사용자용 bin, 공용 bin 등으로 구분해서 수용하며, so 파일을 찾는 정형화된 절차가 있다. 구체적인 내역은 모르지만 말이다.
macOS는 거기에다가 dylib인지 framework인지 하는 개념도 있다. 이건 Windows의 side-by-side assembly나 COM처럼 자신들만의 컴포넌트 규격인 걸까? 이것들의 관계는 무엇인지 잘 모르겠다.
개인적으로 C/C++을 처음 공부하던 시절에도 모듈과 번역 단위 개념이 나올 때부터 생소하고 어려웠다. 무엇이든 범위가 여러 소스 파일, 여러 파일 수준이 되면 어려워지는 것 같다.
7. 콘솔(터미널): 화면을 모두 지우는 명령 등
Windows의 명령 프롬프트에서 CLS는 그야말로 현재 콘솔 버퍼에 있는 모든 출력 내용들을 싹 다 날리는 명령이다. 명령 프롬프트의 강화 버전인 PowerShell이나 Windows Terminal에서도 동일하게 사용 가능하다.
그러나 맥과 putty 터미널에서 clear는 기존 표시된 내용들을 다 위쪽으로 밀어내서 지금 보이는 겉보기 화면만 싹 정리된 듯이 보이게 한다. 화면을 위로 스크롤 시키면 기존 내용들을 여전히 다 확인할 수 있다.
난 개인적으로 이 동작이 굉장히 성가시고 불편했다. 빌드를 돌리고 나서 에러를 확인한 뒤, 에러를 고치고 clear 후 다시 빌드를 돌리는데 이전 빌드의 에러가 자꾸 검색되면 좋을 게 없기 때문이다.
화면을 CLS처럼 완전히 싹 지우는 기능은 '스크롤백 날리기'라고 보통 메뉴에서 별도의 명령으로 존재하는 편이더라. 차라리 clear이나 CLS 명령의 옵션으로 둘 다(전체 vs 한 화면만) 제공하면 어떨까 싶지만, 또 그렇지는 않더라.
개인적인 생각은 다른 터미널들에서도 모든 출력을 싹 날리는 게 더 쉽게 가능했으면 좋겠다.
도스의 배치 파일에도 if errorlevel goto 같은 아주 간단한 제어문이 지원되긴 했지만, 유닉스 계열의 셸 스크립트는 말할 것도 없고 GWBASIC하고도 비교가 민망한 허접한 기능밖에 없었다.;;
탐색기에서 자기 컴퓨터뿐만 아니라 LAN/FTP 상의 다른 컴퓨터까지 바로 들어갈 수 있으면 좋다.
그것처럼 한 터미널에서 내 컴뿐만 아니라 원격 컴퓨터의 터미널에도 바로 들어갈 수 있으면 좋을 것 같다.
마소에서도 이에 대한 필요성을 느끼고 마냥 도스 기반이 아니라 더 전문화된 터미널 앱을 제공하는 것이지 싶다. 너무 늙은 putty조차 대체할 수 있게 말이다.
putty는 문자열 찾는 기능과 특정 문자열이 나타났을 때 highlight 표시하는 기능이 좀 있었으면 좋겠다.
8. 앱들의 개발 형태의 변화
어제 오늘 일은 당연히 아니지만.. 개인용 컴퓨터라는 게 인터넷 단말기나 게임기로 바뀌어 가니.. 단순 정보 조회 프로그램도 이제는 다 PC가 아니라 웹 기반으로 바뀌어 간다. 예전 같았으면 RAD 툴이라도 썼을 법한 프로그램도 이제는 어지간해서는 웹인 듯..
사용자가 직접 다루는 키오스크 앱은..? 테이블마다 태블릿을 갖다놓고 웹이나 앱으로도 만드는 것 같다. 매출관리 프로그램은 직원만 다루니 키오스크처럼 비주얼 UI를 신경 쓸 필요는 없겠지만.. 얘도 바뀌어 간다.
Delphi나 Visual Basic 같은 통상적인 RAD 툴에 대한 수요도 20년 전에 비해 확실히 줄어들었지 싶다.
단순 사전류 프로그램은 한컴사전밖에 안 남았고.. 도움말/문서는 빼박 다 웹이다. 로컬에다 제공하지 않는다.
Windows는 help 디렉터리에 두툼한 도움말 파일들이 사라졌고, Visual Studio의 몇 기가짜리 MSDN도 없어졌다. 2015쯤부터 말이다.
에구~~ 개인적으로는 오프라인 문서가 아예 없어져 버리면 심리적으로 좀 불편한데 말이다. 뭔가 붕 뜬 느낌이다.
종이책이 컴퓨터 viewer 기반으로 바뀌었을 때 약간 떴고, 컨텐츠가 이젠 내 하드에 저장조차 되지 않고 늘 인터넷 연결이 필요하다면.. 더 붕 뜬다. 이게 피할 수 없는 대세이긴 하지만..
이런 시국에 종이책이라든가, PC용 프로그램이 담당해야 할 영역이 무엇인가 하는 생각을 진지하게 하게 된다.
Posted by 사무엘