1. 레거시 부동소수점 MBF
컴퓨터에서 쓰이는 2진법 기반의 부동소수점이라는 개념이야 컴공· 전산에서 기본 중의 기본에 속하는 내용이며 본인 역시 이에 대해서 거의 7년 전에 글을 한번 쓴 적이 있다.
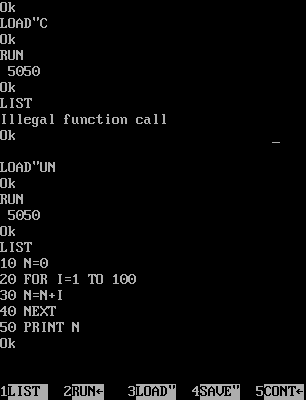
본인은 GWBASIC으로 프로그래밍에 처음 발을 내디딘 세대이다. 그런데 베이직이 PC와는 따로 노는 고유한 부동소수점 체계를 갖춘 언어였다는 사실을 30대 나이가 될 때까지 전혀 모르고 있었다.
쉽게 말해 같은 컴퓨터에서 실행한 다음 프로그램의 실행 결과가 GWBASIC과 QuickBasic이 서로 동일하지 않다는 것이다. 참고로 MKS$, MKI$는 해당 숫자들의 binary representation을 문자열 형태로 되돌리는 저수준 함수이다. C++라면 reinterpret_cast<char *>(&num) 한 방이면 끝났을 일이다.
10 INPUT A!
20 IF ABS(A!)<.01 THEN END
30 C$ = MKS$(A!)
40 FOR I = 1 TO 4: PRINT ASC(MID$(C$, I, 1)): NEXT
50 GOTO 10
하긴, 옛날에 베이직은 DEFINT A-Z 같은 걸 하지 않으면 변수의 기본 자료형이 정수가 아니라 실수였다. 언어를 설계할 때 성능보다 인간적인 면모를 더 추구해서 그렇다. (5/3을 구하면 매정하게 1이 아니라 알아서 1.6666..이 나오게..) 그러니 구조적으로 실수를 지원하는 건 필수였다.
때는 무려 1975년, 빌 게이츠가 폴 앨런과 함께 알테어 베이직을 개발하던 시절에 동료들과 함께 뚝딱 해서 2진법 기반의 부동소수점 표기 방식을 만든 게 Microsoft Binary Format, 일명 MBF라는 스펙이 됐다. 32비트와 64비트 두 형태로 말이다.
이 부동소수점은 알테어뿐만 아니라 BASICA, GWBASIC 등 온갖 플랫폼에서 돌아가는 베이직 인터프리터에 두루 쓰이기 시작했다. 지금도 인터넷에 굴러다니는 GWBASIC은 IEEE754가 아닌 MBF 고유 방식으로 부동소수점을 처리한다.
그랬는데 훗날 1984년경에 IEEE754라고 공신력이 더 높은 표준이 등장하면서 판도가 급격히 그쪽으로 기울었다. 게다가 PC에서는 인텔 80x87이라고 오늘날로 치면 하드웨어 가속에 해당하는 수치 연산 보조 프로세서(코프로세서)도 응당 IEEE754를 기반으로 만들어졌다.
마소는 일찍부터 자체적인 부동소수점 포맷을 먼저 제정해서 이를 퍼뜨려 왔지만 이런 시국에서는 자기도 대세를 거스를 수 없게 되었다. GWBASIC의 후신인 QuickBasic도 80년대 중반에 나왔던 1, 2까지는 MBF를 사용했지만 3.0부터는 IEEE 방식으로 갈아탔다. 그 대신 기존 MBF 방식은 별도의 옵션을 줬을 때에만 지원하게 동작이 바뀌었다. (/MBF) MBF 형태로 저장된 부동소수점을 읽어들이는 레거시 프로그램들과의 호환성도 중요하니까 말이다.
그럼 IEEE와 MBF는 어떤 차이가 있었는가? 몇 가지가 있다.
똑같은 32비트 또는 64비트 공간에다 지수와 유효숫자와 부호 비트를 어느 순서대로 어떻게 분배할지 문제는 한 마디로 그냥 정하기 나름이고 대동소이하다. 마치 철도 궤간을 정하는 문제와 비슷하다.
수 전체의 부호 1비트는 IEEE나 MBF든 공통일 수밖에 없고, 32비트의 경우는 지수 8비트, 유효숫자(mantissa) 23비트라는 비율 역시 동일했다. 다만,
(1) IEEE는 2의 보수 기반인 정수의 관행을 존중해서 부호 비트가 수 전체의 최상위 비트에 있는 반면, MBF는 지수와 유효숫자 사이에 존재했다. 다시 말해 mantissa의 최상위 비트에 있는 셈이다. 이렇게 배치를 함으로써 MBF는 IEEE와는 달리 지수와 유효숫자가 딱 8비트와 24비트로 byte padding이 맞춰지게 했다.
(2) 64비트 실수의 경우 이 비율도 달라진다. IEEE는 지수의 공간도 딱 3비트 더 늘어서 11비트이지만, MBF는 여전히 8비트이다. 그래서 32비트 single 실수를 쓰다가 64비트 double 실수를 쓰면 정밀도는 왕창 심지어 IEEE보다도 더 올라가지만 수의 표현 가능 자리수가 늘어나지는 않는다. 그 대신 바이트 경계는 여전히 1:7 비율로 지켜진다.
(3) 다음으로, MBF는 IEEE처럼 denormal number나 NaN, 무한대/무한소 같은 개념도 없다. denormal이야 숫자 표현과 관련된 내부 디테일이니 그렇다 치더라도 베이직 언어로 수학 함수를 사용하면서 NaN이나 무한대/무한소 같은 걸 접한 경험은 없다. 그런 숫자가 생성될 상황이라면 그냥 "Illegal function call" 에러가 나고 말지.
어쩐지 이런 것들은 본인이 훗날 C/C++로 갈아타면서 처음으로 접했다. 이게 엄밀히 말하면 언어 차이가 아니라 이런 부동소수점 표현 방식 때문에 생긴 차이점이다.
세계적으로 문자들은 언어와 문화권마다 제각각이지만 아라비아 숫자만은 세계 공통이다. 컴퓨터 세계도 사정이 얼추 비슷했는데 그나마 유니코드라는 규격 덕분에 동일한 문자는 세계 어디서나 동일한 방식으로 통용 가능해졌다. 그에 반해 숫자가 부동소수점 한정으로 표현 방식이 파편화돼 있었다는 건 개인적으로 무척 흥미롭게 와 닿는다.
C, 파스칼 같은 언어 이름은 함수 호출 규약 명칭에 등장하는데 베이직은 MBF라는 레거시를 보유하고 있구나. IEEE754의 등장 이전에는 MBF 말고 다른 부동소수점 표현 방식은 존재하지 않았나 하는 의문이 남으며, 파스칼에만 있던 6바이트 실수가 규격이 어떠했는지도 다시 보게 된다. 스펙을 검색해 보니 파스칼도 지수부는 8비트이고 나머지가 부호부(1비트)와 가수부(39비트)이다.
2. MOTOR의 정체는?
이 블로그에서 GWBASIC에 대한 추억들 중에서 지금까지 이걸 거론한 적은 없었던 것 같다.
GWBASIC의 대화식 환경에는 코딩 중에 자주 사용하는 키워드들을 곧바로 입력하는 일종의 키매크로가 있었다. F1부터 F10까지 기능키에 배당된 매크로는 LIST, RUN, LOAD...의 순으로 화면 밑줄에 표시되었으며 KEY라는 키워드(?)를 이용해 사용자가 재정의도 할 수 있었다. 후대의 QuickBasic 계열에서는 없어지기도 할 법도 한 키워드인데 KEY에 그 기능만 있는 건 아니기 때문에 없어지지 않고 남아 있긴 하다.
그리고 매크로가 거기에만 있는 게 아니라 Alt+알파벳에도 있었다. A부터 Z 중 J, Q, Y, Z를 제외한 나머지 22개 알파벳에는 AUTO, BSAVE, COLOR ... WIDTH, XOR까지.. 키워드가 즉시 입력되었다. 이 키워드들은 딱히 재정의 가능하지 않았다. RUN과 SCREEN은 Alt에도 있고 F 기능키에도 있었다. (후자는 엔터까지 자동으로 입력된다는 차이가 있음)
그런데 본인이 주목한 것은 M 자리에 배당되어 있던 MOTOR라는 단어였다. 이거 도대체 뭘까? 경험상 숫자 인자를 하나 받는 것 같던데 도대체 하는 일이 뭘까? 두툼한 GWBASIC 매뉴얼/키워드 레퍼런스를 뒤져봐도 의외로 딱히 제대로 설명돼 있지 않았다. 그러니 궁금증은 더욱 커질 수밖에 없었다.
이 역시 전세계에 존재하거나 존재했던 모든 것들에 대한 정보가 손끝 하나로 검색되는 세상이 온 뒤에야 그게 그런 용도였다는 것을 뒤늦게 알 수 있었다.
MOTOR는 카세트 테이프 장치의 헤더를 올리거나 내리는 명령문이었다. 0부터 255 사이의 숫자를 인자로 받긴 하는데 실질적인 의미는 그냥 zero냐 non-zero냐, 쉽게 말해 그냥 bool이었다. 카세트 테이프가 퇴출된 16비트 이상의 IBM-PC급용 베이직에서는 이 명령은 구현되지 않고 아무 동작도 안 하는 레거시 잉여가 되었다.
옛날에 카세트 테이프에다 소스 코드 저장을 SAVE"FILE" 한 뒤 '녹음' 버튼을 눌러서 쭈루룩 하고, 불러오려면 저장되었던 위치로 정확하게 되감기를 하고 LOAD"FILE"한 뒤, '재생' 버튼을 눌러서 했다던데.. MOTOR는 그런 호랑이 담배 피우던 시절에나 유의미한 기능을 했다는 뜻 되겠다.
그런데 왜 이런 잉여가 한때에는 그 시절에는 자주 쓰이기라도 했는지 Alt+M 매크로에 떡 등재돼 있었다. 현실에서는 모터 따위보다는 MOD 연산자 또는 부분문자열을 구하는 MID$ 함수가 훨씬 더 자주 쓰일 텐데 말이다. 그러고 보니 실제로 Alt+M에 MOTOR 대신 쿨하게 MID$가 배당돼 있던 GWBASIC 구현체가 있기도 했던 것 같다. 베이직은 바리에이션 구현체가 워낙 많으니.. 아니면 그건 그냥 내 기억력의 한계로 인한 착각이었는지는 모르겠다.
※ 기타
(1)
이 외에도 GWBASIC은 그러고 보니 소스 코드의 저장도 고유 방식으로 했고 심지어 후대의 QuickBasic에도 비슷한 관행이 있었다(디폴트 옵션). 베이직 언어들은 그 옛날에도 일종의 가상 기계나 독자적인 개발 환경까지 다 짬뽕으로 추구했던 것 같다.
비주얼 베이직의 중후반대(4정도?) 넘어가서 COM 기반의 BSTR 방식으로 갈아타기 전에는 베이직은 문자열도 자기만의 독자적인 이중 포인터 참조 방식으로 구현돼 있었다. 일단 null-terminate 방식이 아니기 때문에 C와는 다름. 이것도 아마 MBF만큼이나 역사가 왕창 오래 된 독자적인 관행이 아닐까 싶다. (문자열에 대해서도 옛날에 한번 글을 쓴 적이 있다.)
(2)
난 C/C++ 파스칼 같은 타 언어로는 도스에서 텍스트 모드에서 색깔을 바꾸고 표준 VGA 그래픽, 특히 mode 13h를 바꾸는 코드를 작성해 본 적이 없다. 베이직에서는 COLOR 내지 SCREEN으로 곧장 됐을 일이 타 언어에서는 표준 라이브러리에서 지원해 주지 않았기 때문이다.
GWBASIC에서 Q(uick)Basic 계열로 바뀌면서 정말 좋은 것 중 하나가 본격적인 VGA 그래픽이 지원된다는 것이었는데, 16진수를 10진수로 바꿔 버릴 생각을 어째 했나 모르겠다. 실제로는 0x13인데 그걸 그냥 13만 써도 되게..;; 그것까지 초보자를 배려한 것이었나 궁금해진다. 그 초보자가 숙련자로 등급이 바뀌는 순간부터 문화 충격을 경험할지도 모르는데..
(3)
베이직이라는 언어 자체는 다트머스 대학의 컴공 교수가 고안한 것이지만, 저런 구현체는 빌 게이츠 같은 괴짜가 아니면 생각해 낼 사람이 별로 없을 물건이다.마소에서는 처음에는 다양한 8/16비트 컴퓨터를 대상으로 베이직 인터프리터를 개발했지만, 사실 IBM PC용으로는 베이직 컴파일러도 DOS 1980년대부터 만들어 오고 있었다.
그래서 Quick이라는 브랜드를 붙여서 QuickBasic 1.0을 1985년에 내놓았다. 이때 퀵베이직은 지원하는 문법은 GWBASIC과 별 차이가 없지만 대화식 환경이 아닌 명령줄에서 컴파일 + EXE 생성만 가능한 베이직일 뿐이었다.
그러다가 1년 주기로 버전 2와 3을 내놓으면서 기존의 구닥다리 행번호 위주가 아닌 구조화 문법이 차근차근 도입되었다. 베이직이라는 언어가 이때(1980년대 중반) 1차로 마개조된 셈이다. 그리고 4.0에 와서야 비로소 함수의 재귀호출이 가능해지고, 즉석 문법 체크와 실행이 지원되는 IDE가 추가되었다. 사실, IDE 자체는 2에서부터 도입됐고 그때 이미 퀵라이브러리도 도입됐다고 하지만, 그때는 지금과 같은 IDE가 아니었다.
그 뒤 1988년 가을에 출시된 QB 4.5가 장수만세 안정판이 되었다. 퀵베이직은 1990년에 어쩐 일인지 버전 5와 6을 건너뛰고 QuickBasic Extended 내지 MS Basic PDS (전문 개발 시스템)이라는 이름으로 7과 7.1 버전까지 개발된 뒤, Visual이라는 브랜드로 바뀌었으며 이때부터 플랫폼도 Window로 바뀌었다. 5, 6을 건너뛴 이유는 퀵베보다 먼저 개발되어 온 그 전신 컴파일러의 버전 번호를 맞췄기 때문이다. (참고로 Visual C++도 IDE의 버전보다 컴파일러의 버전이 더 높음. 전신인 MS C 의 버전을 계승하기 때문이다.)
이 와중에 1991년에 출시된 MS-DOS 5.0에서는 QuickBasic에서 컴파일 기능을 떼어낸 QBasic이라는 물건을 만들고, 이 엔진으로 MS-DOS 4.0까지 내장하고 있던 GWBASIC과, EDLIN 텍스트 에디터를 동시에 대체했다. 무척 흥미로운 점이다. MS-DOS가 전체 화면 형태로 제공하던 유틸리티는 4.0에서 도입됐던 DOS Shell 이후로 이게 둘째가 아닌가 싶다.
Posted by 사무엘