<날개셋> 한글 입력기 8.2는 기념비적인 작품이었다. 내부적으로 이것저것 개선 사항이 많았으며, Windows 10 지원에다 후보 변환 프로토콜 관련 작업은 아주 뜻깊은 결실이기 때문이다.
8.2는 한글 조합과 관련된 쪽보다는 키보드 입력을 인식하는 쪽에서 이례적으로 새로운 기능이 많이 추가되었다. 오른쪽 alt/ctrl을 지원하는 것에 대해서 몇 번 건의를 받긴 했지만 지금까지 별 생각을 안 하고 지냈다. 그랬는데 이것을 키보드 드라이버 보정이라는 새로운 기능으로 통합하면 되겠다는 생각이 들자, 결국 예정에 없던 신규 기능으로 들어가게 됐다.
여기에다가 키보드/키패드 구분과 scroll lock 인식 같은 것도 아주 신선한 기능이다.
그 뒤, 8.2의 다음 버전은 8.4로 설정되어 있으며, 이번엔 다시 입력기 내부의 아키텍처를 개편하는 어려운 작업이 한창이다. 내년 2월 말쯤에 내는 것을 목표로 하고 있다.
1. 최종 변환 규칙의 개편
가장 먼저 수술대에 오른 기능은, 지난 3.0 이래로 거의 변화 없이 형태가 동일하게 유지돼 왔던 편집기 계층의 '최종 변환 규칙'이다. 최종 변환 규칙은 수식값을 만족하는 번호에 해당하는 입력 항목에 대해서 아스키 문자의 전/반각을 바꾼다거나 한글 자모를 호환용 자모로 바꾸는 것 같은 간단한 변환을 수행한다.
다음 버전에서는 최종 변환 규칙이 적용되는 조건과 방식이 더 깔끔하게 바뀔 예정이다.
첫째, 수식이 없어진다. A<=2 (첫 세 개의 글자판만), A&1 (짝수 번째 글자판만) 이런 식으로 적용 대상을 지정하는 게 강력하긴 하지만 실제로 쓰이는 경우가 거의 없다고 판단되어서이다. 또한 이런 번호가 붙어 있지 않고 보조 입력 도구가 제공하는 입력 항목에 대해서는 최종 변환 규칙을 적용할지 의문이 생기기도 한다.
그래서 이제는 최종 변환 규칙을 지정하면 모든 입력 항목에 일괄적으로 그 규칙이 적용된다. 수식 같은 거 생각할 필요가 없다. 그 대신, 각각의 입력 항목에서 '기본 입력기' 이상 등급부터는 최종 변환 규칙의 적용을 원하지 않는 경우 옵션을 지정할 수 있다. No라고 옵션이 지정되지 않은 모든 문자 생성기들은 기본적으로 최종 변환 규칙을 적용 받으며, 특히 '빈 입력기'는 그런 옵션도 없기 때문에 규칙이 무조건 적용되게 된다(입력 스키마조차 '빈 스키마'인 경우는 물론 제외. 문자 생성기가 아예 동작하지 않는 상황이므로).
둘째, 조건이 완화된 대신, 적용 범위는 더 좁아진다. 최종 변환 규칙은 (1) '일반 문자' 타입의 날개셋문자, 또는 (2) 한글의 경우 두벌/세벌/종성 두벌식 등등 무엇이건 상관은 없지만 초중종 낱자가 단 하나만 있는 경우에만 한해서 적용된다. '다중 문자' 타입에는 적용되지 않으며, 날개셋문자가 아닌 방식으로 생성된 raw 문자열에도 적용되지 않는다. raw 문자열이란 후보 변환 내지 '고급 입력기'의 '사용자 정의 조합' 같은 걸 말한다.
애초에 반각/전각 변환이나 한글 자모 종류 변환 같은 간단하지만 보편적이고 전역적(global)인 변환만을 의도했던 것이기 때문에 이렇게 범위를 좁히는 게 최종 변환 규칙의 취지를 살리는 데 더 도움이 될 것으로 보인다. 가령, 더 복잡한 형태의 한글을 다른 형태의 문자로 바꾸려면 아예 '고급 입력기'의 '한글 출력 치환'을 사용하면 될 테니 말이다.
이런 이유로 인해 이제는 최종 변환 규칙을 통해 반각을 전각으로 바꾸는 설정을 넣었다 하더라도 '일반 문자' 날개셋문자 외에 다른 방식으로 입력하는 문자/문자열에 대해서는 그런 변환이 일어나지 않는다. 그것들은 언제나 있는 그대로만 입력될 것이다.
2. 오토마타에 T 변수 추가
글쇠배열 수식에서는 잘 알다시피 T라는 변수가 오토마타 상태 번호를 나타낸다. 그런데 이제는 오토마타에도 O에 이어 T라는 변수가 추가되었다. 이것은 한글 조합을 더 계속할 수 없어졌을 때 왜 더 계속할 수 없는지에 대한 추가 정보를 담고 있다.
잘 알다시피 오토마타는 입력된 글쇠의 초중성 정보가 A~C라는 변수에 담겨 있고, 지금 상태에서 무슨 상태로 분기할지를 그 변수 값으로부터 결정하는 수식의 집합이다.
그런데 오토마타상으로는 결합이 계속 가능함에도 불구하고 결합이 가능하지 않은 경우가 크게 두 가지가 있다.
첫째는 말 그대로 낱자 결합 규칙이 더 존재하지 않을 때이다. 가령, ㅋ 다음에 ㅁ을 누른다거나 하면 일단은 답이 없다. 그리고 둘째는 흔한 경우는 아니지만 '허용 한글 제약'에 걸렸을 때이다. KS 완성형 2350자만 조합 가능하게 해 놓은 상태에서 "또" 다음에 받침 ㅁ을 시도한다면 더 진행을 할 수 없다.
이럴 때는 한글 입력기는 A~C에 모두 0을 넣어서 동일 오토마타 수식의 값을 다시 구한다. 이때 수식은 반드시 양수가 아니라 0 이하의 값을 되돌려야 한다. 10여 개의 0 이하 코드값들은 "다음 글자로 자연스럽게 넘어가기", "이 입력을 무시", "무한 낱자 수정" 등 여러 용도로 의미가 예약돼 있다.
A~C 중 적어도 한 성분에 nonzero가 있는 정상적인 상황일 때는 T는 0임이 보장된다. 그러나 오토마타 이외의 사유로 조합을 할 수 없어서 A~C가 0인 상태로 수식이 다시 계산될 때는, T는 1(낱자 결합 불가) 또는 2(허용 한글 제약)가 들어온다.
즉, A|B|C와 T==0은 동치이기 때문에 A~C 낱자 값을 일일이 살펴보기 전에 지금이 정상/비정상 중 어느 상황인지부터 판단하고 싶으면 T 값을 먼저 살펴보면 된다.
T 값을 판단해 보면, '똔' 다음에 '똔ㅁ(받침ㅁ. ㄴ+ㅁ 결합은 없음)으로 가는 것은 허용하지만(0. 다음 글자로) '똠'은 입력되지 않고 ㅁ이 아예 무시되게(-1. 이 입력 무시) 할 수 있다. 두 상황을 구분해서 인식할 수가 있게 되는 것이다. '허용 한글 제약' 기능을 좀 더 창의적으로 활용할 수 있을 것이다.
참고로 진짜로 세 성분 중 단 하나도 nonzero가 없는 빈 한글 날개셋문자는 오토마타에 전달되지 않는다. 새로운 조합을 만들거나 지금 조합을 종료시키지도 않음이 보장된다.
3. 서로 다른 문자의 개수 계산
<날개셋> 편집기에는 블록으로 잡은 텍스트에 대한 간단한 분량 통계를 내는 기능이 도구 메뉴에 존재한다.
줄 수와 UTF16 기준 글자 수는 쉽고 직관적인 통계이고 거기에다 ANSI 인코딩으로(UTF-8도 포함) 변환했을 때의 바이트를 출력해 주는데, 이번에는 텍스트 내부에 존재하는 서로 다른 문자의 수도 추가했다. 즉, "ABCADE"는 글자 수는 6이지만 서로 다른 문자의 수는 5이다.
그래픽 에디터에 이 selection 내부에 존재하는 서로 다른 RGB 색상수가 몇인지 출력하는 기능이 있는 것에 착안하여 저 기능을 구현해 넣었다.
특정 문자 집합으로만 구성되거나 중복되는 문자가 없어야 하는 데이터 테이블을 검증할 때, 혹은 이 문서에 쓰인 서로 다른 한글이나 한자가 총 몇 자인지 궁금할 때 이 기능을 활용하면 된다. 생각보다 요긴할 것이다.
계산 기준은 surrogate까지 감안하여 철저하게 유니코드 코드 포인트이다. 그렇기 때문에 옛한글은 글자 단위가 아니라 낱자 단위로 종류가 계산된다.
4. 정렬 기능의 대소문자 비교 방식 개선
지금으로부터 거의 4년 전에 나온 6.5버전에서는 대소문자 구분이 없이 텍스트를 정렬할 때 문자열을 비교하는 알고리즘을 개선한 바 있다. 동일하게 간주되는 텍스트끼리라도 걔네들 사이에서는 대소문자 기준으로 서열을 둬서 ABCabc가 아니면 AaBbCc가 보장되게 했다. 대소문자 구분을 안 한다고 해서 aABbcC 이렇게 뒤섞이지 않게 했다는 뜻이다.
그런데 그때 작성한 알고리즘에는 좀 문제가 있었다. 그건 같은 문자열들 중에서는 AB Ab ab라고 순서를 딱 보장해 줬지만, AD와 ab를 비교할 때는 여전히 AD를 앞으로 보냈다. 왜냐하면 첫 글자 A와 a 중에서 A가 먼저 처리되기 때문이다.
난 "AB, Ab, ab, AD"를 기대했고 당연히 그렇게 나올 줄 알았는데 실제로 나오는 결과는 "AB, Ab, AD, ab"였다.
왜 이런 문제가 이제야 발견됐는지, 내가 왜 그때 그런 실수를 했는지를 통탄하면서 어쨌든 문제를 고쳤다. 문자열 비교에도 생각보다 교묘한 곳에 복병이 있다.
5. 외부 모듈의 우클릭 메뉴 형태 변경
Windows 8 이래로 외부 모듈은 이제 우클릭 메뉴를 이용해서 입력 항목(입력 모드, 글자판..)을 전환할 일이 많아질 텐데..
입력 항목이 10개보다 적을 때는 입력 항목을 우클릭 메뉴 첫 단계에서 바로 고를 수 있게 했다. 아래 그림에서 왼쪽을 오른쪽으로 바꿨다는 뜻이다. 이렇게 하니까 시각적으로 내지 심리적으로 훨씬 더 좋아 보인다.
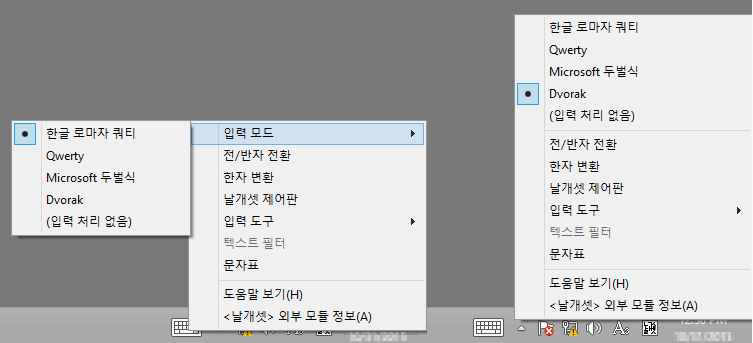
'입력 패드'는 키보드 입력도 이제 가능하긴 하지만 그래도 입력 도구가 여전히 더 중요하다 보니, 입력 도구를 우클릭 메뉴의 첫 단계에서 바로 고를 수 있고 글자판은 하위 메뉴에서 고른다.
'외부 모듈'은 반대로 글자판을 첫 단계에서 바로 고르고, 입력 도구는 하위 메뉴에서 고른다. 이런 관계가 딱 정립되었다.
6. 단축글쇠 리스트에서 이동뿐만 아니라 복사도 지원
날개셋 제어판의 설정 중에는 단축글쇠를 관리하는 기능이 편집기 계층에 있고 기본 입력 스키마의 추가 옵션에도 있다. 여기에 등록한 단축글쇠는 딱히 정렬 기준이 있거나 중복 등록 체크를 하지 않으며, 지난 7.7 버전부터는 마우스 드래그로 항목을 이동할 수도 있게 했다. 복수 개의 아이템을 선택해서 끌면 그 아이템들이 한꺼번에 위나 아래로 이동한다.
그에 이어 이번 버전에는 Ctrl+드래그로 복사도 되게 했다.
이미 왼쪽의 입력 항목 트리는 이동과 복사가 모두 지원되고 있었는데 그게 단축글쇠 리스트로까지 범위가 확대된 것이다. 글쇠나 수식이 비슷한 단축글쇠를 여럿 등록할 일이 있을 때 복사를 한 뒤에 다른 부분만 고치는 식으로 편집하면 단축글쇠를 지금보다 더 편리하게 등록할 수 있을 것이다.
이 외에도,
(1) "빈 입력 스키마와 호환되게" 옵션을 지금까지는 '기본 입력 스키마'에서만 지정할 수 있고 '고급 입력 스키마'에는 지정할 수 없었는데, 그 제약이 없어졌다.
(2) 편집기에서 '자동 줄바꿈' 옵션을 끈 상태로 임의의 파일을 열거나, 혹은 스크롤 바가 생기지 않을 정도로 아주 짧은 파일을 연 경우 초기에 문서의 전체 줄 수가 실제 줄 수가 아니라 1로 잠시 잘못 표시되던 버그를 잡았다. 이것 말고도 자체 에디트 컨트롤의 코드를 전반적으로 좀 최적화를 했다.
(3) 지난 7.9 버전부터는 조합 중인 두벌식 한글을 도깨비불 현상이 미리 적용된 형태로 표시하는 옵션이 '고급 입력기'의 '한글 출력 옵션'에 추가되었다. 그래서 일명 '초성 지향 도깨비불'이라는 걸 구현 가능해졌는데, 문제는 "가ㅁ" 상태일 때는 '감'에 해당하는 한자 변환을 할 수 없었다. 지금까지는 그게 가능하지 않다가 이제 다음 버전부터는 글자 단위와 단어 단위로 모두 한자 변환이 가능해졌다.
저 상황에서 예외를 둬서 저것만 가능하게 하는 것은 어렵지 않지만, 더 탄탄한 이론적 근간을 마련해서 문제를 완전히 해결하는 게 쉽지 않아서 지금까지 문제 해결을 보류하고 있었다.
(4) 고급 입력기의 사용자 정의 조합을 이용하여 비한글 외국어 문자를 입력하는 예제로 지금까지 제공된 건 히라가나/가타카나라는 일본어 자료가 거의 유일했는데, 이번에는 일명 'Qwerty Extension'이라는 걸 추가했다.
일본어 자료는 조합 로직 자체가 유의미한 반면, 얘는 후보 데이터들이 본좌이다. 알파벳, 숫자, 기호 등 거의 모든 문자가 곧장 입력되는 게 아니라 조합 형태로 입력되며, a를 조합하는 상태에서 한자 키를 누르면 a에 그야말로 상상할 수 있는 온갖 액센트/변형 부호가 붙은 것들을 선택할 수 있다. -에 대해서는 N-dash, M-dash, 하이픈 등 온갖 바리에이션이 들어있는 식이다.
생각보다 무척 유용하며 예제 입력 데이터로서의 의미도 큰데, 왜 지금까지 이런 게 없었는지 궁금하다. 정 재민 님께서 제공해 주셨다. 설명문 때문에 파일이 생각보다 덩치가 크다.
Posted by 사무엘

