2018년도 벌써 끝이 얼마 남지 않았다.
그 사이에 날개셋 한글 입력기는 파이널 버전인 9.5가 나온 지 70일 남짓 지났고, 본인의 근황에도 여러 변화가 생겼다. 내 인생에 한글 입력기 TODO list가 비어 있는 나날도 이렇게 오는구나 싶다.
뭐, 정말로 TODO가 전혀 없는 것은 아니다.
생각 같아서는 이미 여러 번 얘기했듯이 입력 설정 파일 포맷을 뜯어고치고 싶고 엔진 구조를 다시 설계하고 싶고, 도움말을 몽땅 영작도 하고 싶다. 허나, 그런 것들은 지금 도저히 추진 가능하지 않을 정도로 너무 거창한 것들이고 비용 대비 효과가 미미하기 때문에, 굳이 지금 같은 학생 신분에서 졸업을 더 늦추면서까지 욕심을 내지는 않는 것이다. 9.5를 넘어 10.0이라는 대망의 버전 번호는 그 날을 위해 비워 두는 것일 수도 있다.
그래도 거창한 것 말고 GUI, 보조 기능, 데이터 쪽에 아주 자잘하게 바뀐 것은 있다. 이것들을 일단 9.6 정도로 정리하고자 한다.
1. 필기 인식!
날개셋 한글 입력기는 지난 9.3 버전 이래로 총 10개의 입력 도구를 제공하고 있다. 그런데 9.6에서는 기존 도구들과는 성격이 매우 다른 물건이 하나 더 추가되어 11개가 되었다.
바로 필기 인식이다. 현재의 글쇠배열이나 날개셋 입력 설정과는 아무 관계 없이, 글자의 모양을 사용자가 마우스로 그리고 프로그램이 이를 인식하여 문자를 입력시킨다. 기술적으로는 '온라인 필기 인식'이다.
필기 인식은 MS IME에서는 아주 오래 전부터 갖추고 있지만 날개셋 한글 입력기에는 없는 기능 중 하나였다. 뭐, 애초에 내 프로그램의 존재 목적과 전문 분야는 세벌식 관련 특수 기능, 키보드 인식 관련 customization, 옛한글과 복합 낱자 처리.. 따위이지, 그런 AI 분야가 아니니까 말이다.
하지만 내가 필기 인식 엔진을 직접 구현까지는 하지 않더라도, 기존 API를 통해서라도 날개셋에서 필기 인식 기능을 제공할 수는 없으려나 하는 아쉬움이 있었다. 그래서 본인은 방법을 찾아 봤는데.. 다행히도 방법을 어렵지 않게 발견할 수 있었다.
과거에는 Windows CE 내지 XP 태블릿 에디션 같은 일부 제품군에만 그런 API가 있었다고 한다. 하지만 이제는 데스크톱용 Windows에도 필기 인식 기능을 다 사용할 수 있더라.
그리고 API 형태가 XP 시절과 Vista 이후가 서로 좀 달라졌다. 이 시점에서 굳이 legacy API를 지원할 필요는 없으니, 내 프로그램의 필기 인식 기능은 후자만 지원하는 형태로 개발되었다.
필기 인식 덕분에 날개셋 한글 입력기의 다음 버전이 9.51이 아니라 당당하게 9.6으로 매겨질 수 있게 됐다. 자체 기능이 아니라 운영체제의 API를 빌려서 동작하는 기능이 한자 단어 사전과 더불어 하나 더 추가됐다. 필기 인식이야말로 키보드 대신 포인팅 장비만으로 문자를 입력하는 기능의 백미 진수가 아닌가 싶다.
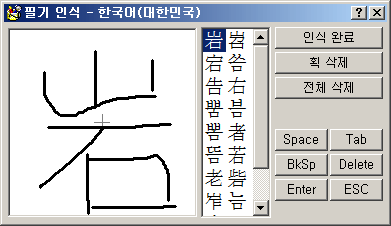
위의 스크린샷에서 보듯이 필기 인식 도구는 (1) 글자를 그리는 공간인 정사각형 입력란, (2) 인식된 글자 후보 목록, 그리고 (3) 주요 도구 명령(획 지움 등)과 (4) 자주 쓰이는 키보드 글쇠 버튼들로 평범하게 구성되어 있다.
"부수로 한자 입력"이나 "문자표" 같은 입력 도구들은 키보드에 없고 평소에 자주 쓰이지 않는 특수문자 몇 자를 입력하는 게 목적인 반면, "필기 인식"은 일상적으로 자주 쓰이는 linguistic한 문자들을 연달아 많이 입력하는 용도로 쓰인다.
그렇기 때문에 전자 문자표들은 리스트의 항목을 더블 클릭해야 글자가 입력되지만, "필기 인식"은 한 번 클릭하는 것만으로도 글자가 곧장 입력되게 했다.
그리고 이 입력 도구는 중요한 옵션이 두 종류 있다. 첫째, UI 모드이다.
위의 스크린샷처럼 입력란이 하나만 있고 글자 후보 선택을 수동으로 할 때는 타이머도 옵션으로 지정할 수 있다. 마지막 획을 긋고 나서 별다른 조치 없이 2초 정도 있으면 1순위 글자가 자동으로 본문으로 삽입된다. 매번 '인식 완료'를 누르거나 목록에서 글자를 찍을 필요가 없다. 아니면..
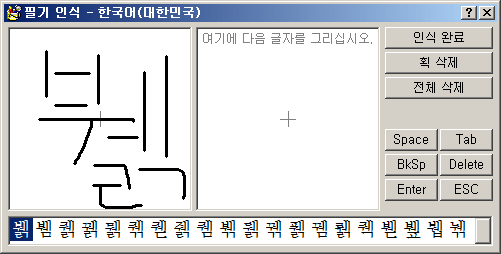
이렇게 입력란을 2개를 꺼내서 쓸 수도 있다. 왼쪽의 입력란에다가 글자를 그린 뒤에 곧장 오른쪽 입력란에다 글자를 그리기 시작하면 왼쪽에서 인식된 글자가 곧장 본문에 삽입되는 것이다. 창이 세로로 길쭉한 크기이면 두 입력란도 좌우로 가로가 아닌 상하로 세로로 자동으로 배열된다.
입력란이 2개 있을 때는 space나 엔터를 누르는 것도 먼저 인식 결과를 본문으로 보내고 난 뒤에 수행한다. 글자를 그리고 있고 후보 목록이 뜬 상태가 일종의 composition 상태라고 생각하면 된다.
둘째로, 사용할 필기 인식 엔진의 언어이다.
필기 인식 엔진이란 건 범언어 세계 공통 형태로 존재하는 게 아니라 각 언어별로 제각기 나뉘어 있다.
그래서 한글은 오로지 한국어 엔진에서만 인식 가능하며, 히라가나· 가타카나는 일본어 엔진에서만 인식된다. 중국에서만 쓰이는 간체 한자를 인식하려면 중국어 엔진을 사용해야 한다.
어느 언어에서나 동일하게 인식 가능한 문자는 숫자, 알파벳, 아스키 기호와 한중일이 완전히 동일하게 사용하는 공통 한자들뿐이다. 한글을 알아보지 못하는 중국 및 일본어 엔진에서는 '튽'을 입력하면 다들 長이 1순위로 제시되는 걸 볼 수 있다.
이 입력 도구는 기본적으로 한국어 엔진을 사용하지만, 컴퓨터에 한중일에 속하는 언어가 2개 이상 설치되어 있다면 원하는 언어의 엔진을 우클릭 메뉴에서 선택할 수도 있다. 프로그램 제목 표시줄에도 현재 사용 중인 언어가 나타나 있다.
Windows 10 기준으로 설정 - 언어 옵션에 들어가면, 각 언어별로 언어 팩이나 IME와는 별개로 필기/음성 데이터를 받는 버튼이 있다. 거기서 한중일 언어의 필기 데이터를 받으면 그 기능을 내 프로그램에서 활용할 수 있게 된다.
그런데 정확하게는 모르겠지만 내 경험상, Microsoft의 한중일 기본 IME가 제공하는 필기 인식이랑, 저 official한 필기 인식은 따로 노는 별개의 기능인 것 같다. 마소의 일본어/중국어 IME는 '확장 입력기 애플릿'을 통해 자체적으로 필기 인식 기능을 제공하지만, 내 프로그램에서는 여전히 일본어/중국어 필기 인식 엔진이 존재하지 않는 것으로 인지하는 경우도 있다.
의외로 Windows Vista는 CD 대신 DVD로 출시되고 전세계 다국어가 기본 내장되기 시작한 첫 버전이어서 그런지..
중국어· 일본어 IME를 끄집어낸 적 없고 Office조차 설치하지 않은 한국어판에도 중국어와 일본어 필기 인식 엔진이 다 기본 내장돼 있는 듯했다. 그것도 Ultimate 말고 Home premium급이 말이다. 아무튼..
한중일 언어의 필기 인식은 이렇게 정사각형 격자에서 글자를 하나씩 인식하는 방식으로, 마치 학창 시절의 칸 공책처럼 동작한다. 하지만 라틴 알파벳은 길쭉한 4선지에다가 단어를 한붓그리기 하듯이 필기체로 날려 쓰는 형태로 동작한다. 즉, 프로그램의 UI 자체가 서로 다르다.
요즘 Windows 10급 컴퓨터에 영어 필기 인식 엔진은 기본으로 다 깔려 있고 이 기능을 활용할 수도 있지만.. 내 프로그램에서는 그건 보류하고 일단은 형태가 더 간단한 한중일 위주로만 구현을 했다.
이런 식으로 필기 인식뿐만 아니라 음성 인식(받아쓰기)도 보조 입력 도구로 구현됐으면 좋겠는데.. 기존 API를 공부하는 것만 해도 필기 인식보다는 훨씬 더 어려울 것 같다. 동아시아 언어는 지원이 아직까지 훨씬 미비하기도 하고 말이다.
2. 글꼴 본뜨기/본뜬 글꼴 삭제 기능
날개셋 한글 입력기는 내부적으로 전용 비트맵 글꼴을 사용하는 부분이 있다. 그렇다고 유니코드의 모든 문자의 글립을 직접 내장해서 제공하지는 않으며, 그럴 수 없고 그럴 필요도 없다.
한자 같은 글자는 그냥 사용자의 컴퓨터에 들어있는 운영체제 글꼴로부터 비트맵을 추출하라고 글꼴 본뜨기라는 기능이 있다. 유니코드 영역별로 여기는 무슨 글꼴을 이용해서 추출하라는 간단한 절차 스크립트 파일도 있다.
날개셋 제어판의 '시스템 계층'으로 가 보면 글꼴 본뜨기를 하고, 필요하다면 절차 스크립트를 편집하고, 본떴던 글꼴 파일을 삭제하는 기능이 있는데.. 이번 9.6에서는 이 글꼴 본뜨기 관련 기능들이 크게 개선되었다. 다음과 같은 변화가 생겼다.
(1) 예전에는 글꼴 본뜨기 버튼을 누르면 그냥 무조건 모든 본뜨기 작업을 처음부터 새로 했다. 하지만 이제는 이미 본뜨기가 돼 있는 파일은 또 건드리지 않고 넘어가며, 변화가 생긴 항목에 대해서만 본뜬다.
만약 모든 항목이 본뜨기가 돼 있어서 파일이 생성된 게 하나도 없으면 "모든 항목이 본뜨기가 돼 있습니다. 혹시 이것들을 무시하고 본뜨기를 처음부터 다시 하시겠습니까?"라고 확인 질문이 나오며, 여기서 사용자가 '예'를 누르면 이전처럼 본뜨기를 처음부터 새로 하게 된다.

(2) 글꼴 본뜨기를 한 뒤, 절차 스크립트에 명시된 영역과 겹치는 파일이 남아 있으면 그건 자동으로 제거하게 했다.
예를 들어 스크립트에 0~300, 500~800이 명시돼 있었고 이렇게 본뜨기를 했다고 치자. 나중에 500~800을 400~800이나 500~900으로 바꿔서 본뜨기를 하게 됐다면.. 이 영역과 충돌하는 이전의 05000800.16/8 같은 파일은 이 프로그램이 알아서 제거해 준다는 것이다. 충돌이 발생하지 않게 해 준다.
(3) 본뜬 글꼴 삭제 기능은 스크립트에 명시돼 있는 파일을 삭제하는 것과 스크립트에 명시되지 않은 잔상을 삭제하는 것을 취사 선택 가능하게 했다. 물론 둘 다 싹 다 없애는 것도 가능하다.

(4) 또한, 글꼴을 본뜨거나 삭제하기 전에, 이미 날개셋 한글 입력기 프로그램이 로딩해서 열어 버린 글꼴 파일들이라도 모두 닫게 했다. 그래서 정상적으로 덮어쓰거나 삭제할 수 있다.
이제는 본뜬 글꼴을 삭제해 버리면 한자 글꼴이 존재하다가도 다시 한자가 표시되지 않는 상태로 되돌아가는 게 가능해졌다. 이전 버전에서는 그게 가능하지 않았었다.
(5) 끝으로, 본뜨기 스크립트의 내부 구조도 개편했다.
SYMBOL, HANGUL, LATIN이라고 섹션을 구분하여 SYMBOL 영역에서는 예전과 동일하게 본뜰 문자 영역을 명시하면 된다.
HANGUL과 LATIN에서는 예전처럼 번거롭게 AC00~AC00, 00~FF을 써 줄 필요 없이, 이미 선언된 글꼴 ID만 써 주거나.. 아니면 새로운 글꼴을 선언만 하면 자동으로 완성형 한글이나 영문 글꼴을 본뜨도록 했다.
스크립트에서 글꼴 ID도 예전에는 고정된 배열을 기반으로 5~63 사이만 지정할 수 있었으나, 이제는 쿨하게 아무 숫자로나 지정 가능하게 했다(32767 이내). 그리고 완성형 한글이나 영문에서 재사용 없이 글꼴을 일회용으로만 선언할 때는 번호를 지정할 필요조차 없이 그냥 0만 줘도 된다.
한글 입력 엔진과는 무관한 그냥 UI 기능인데, 뭔가 프로그램의 완성도를 향상시키는 여러 작업들이 한데 행해졌다.
3. 이모지(emoji) 입력
2010년대부터 유니코드의 확장 평면에는 한자뿐만 아니라 이모지(Emoji)라고 불리는.. 이모티콘이 아니라고는 하지만 웹과 모바일에서 실질적으로 이모티콘처럼 쓰이는 온갖 그림문자들이 추가되고 있다.
유니코드 위원회는 출처와 근거가 명확하지 않은 임의의 문자를 제멋대로 넙죽 받아들이고 추가해 주는 곳이 절대 아니다. 그럼에도 불구하고, 일본에서 임의로 이런 그림문자들을 오랫동안 많이 사용해 온 덕분에 이들도 전세계에서 통용되는 유일한 코드 번호가 주어지게 되었다.
BMP를 벗어나 확장 평면이라는 제2군, 2루에 추가되는 문자들은 일상생활에서 쓸 일이 없는 듣보잡 벽자 한자나 고대 문자, 악보 기호 등이 고작이었는데.. 웬일로 채팅에서 활발히 쓰이는 그림문자가 이 영역에 대거 추가되었다.
그래서 유니코드의 버전이 10에 도달한 무려 2010년대까지도 모든 글자가 16비트 코드 포인트 하나로 감당 가능하다고 안일하게 생각하고 UTF-16의 대비가 제대로 돼 있지 않던... 구닥다리 글꼴 엔진이나 텍스트 에디터들이 이제야 부랴부랴 수정되어야 했다고 한다. 뭐, 출처를 알 수 없는 카더라 통신이다.
폰트는 근본적으로 흑백 벡터 이미지밖에 표현을 못 하니, 인쇄를 염두에 둔 워드 프로세서에서는 이런 이모지들이 그냥 U+26??대의 그림문자와 별 다를 바 없는 외형으로 찍힌다. 하지만 전문적인 채팅 앱이나 스마트폰의 텍스트 입력란에서는 이것들이 컬러 그림으로 표시된다. 이 정도면 마치 한자만큼이나 글자와 그림의 경계가 모호해지는 것이나 마찬가지로 보인다. 서식(글꼴, 글자색, 크기 변경 등) 없는 텍스트 입력란 하나만 만드는데도 온갖 유니코드 문자 처리뿐만 아니라 이제는 사실상 그림 출력까지 감당해야 할 듯하다.;;
2010년대에 나온 최신 중국어· 일본어 IME를 보면 이런 이모티콘을 입력하는 전용 문자표나 입력 모드가 꼭 존재하더라. 이런 거 입력도 뭔가 피할 수 없는 대세가 되어 가는 듯한 느낌이다.
하지만, 내 프로그램은 모든 유니코드 문자를 고르는 범용적인 문자표 외에, 분야별 전용 문자표 같은 것은 딱히 고려 대상이 아니다. 현재로서는 말이다.
또한 편집기도 일반 문자들조차 흑백 비트맵 나부랭이로 출력하는 주제에 이모지를 컬러 이미지로 출력해야 할 이유는 없다.
날개셋 한글 입력기가 이모지의 지원과 관련하여 할 만한 최소한의 조치는 글꼴 본뜨기 스크립트에다가 이 영역을 반영해 주는 것이다. Windows의 경우 Segoe UI Symbol이라는 글꼴이 이모지 출력용으로 쓰이고 있어서 이걸로 U+1F300부터 U+1F6FF 정도를 전각으로 본뜨면 된다. 문자표의 영역명에는 이 영역도 이미 등록돼 있다.
이건 아주 간단한 조치이니 지난 9.5에도 반영돼 들어갔으면 좋았겠지만..;; 인제 생각이 나 버렸으니 뭐 어쩔 수 없다. 이제 9.6을 설치한 뒤 글꼴 본뜨기를 다시 해 주면 편집기에서 이모지 글꼴들을 볼 수 있다.
4. '조합 안에 조합 생성' 입력 도구의 개선
'조합 안에 조합 생성' 입력 도구는 지난 9.3과 9.5 버전 시절에 도입되었던 핵심 기능들 중 하나이다. 이제 더 고칠 게 없을 거라 여겨졌지만 미세한 개선 사항과 버그들이 더 발견되어서 9.6에서 다들 고쳤다.
- numlock 키패드로도 후보를 선택할 수 있게 했다. 안 그래도 세벌식 자판은 키보드의 1~0은 문자가 배당돼 있는데 Ctrl+숫자뿐만 아니라 numlock 키패드도 지원된다면 아무래도 더 도움이 될 것이다.
- 한글을 조합하는 중에 capslock 또는 이에 준하는 조합 종료 글쇠를 누르면 원래는 아무 반응이 없어야 정상이다. 그런데 외부 모듈은 지금 조합이 덧나면서 조합이 종료되는 문제가 있었다. 편집기, 외부 모듈, 입력 패드에서 모두 아무 반응이 없게 일관되게 조치를 취했다.
- 편집기와 입력 패드는 입력 도구를 꺼내는 과정에서 대화상자를 꺼내고 창 포커스가 바뀌기 때문에 이런 일이 원천적으로 발생할 수 없는데 외부 모듈은 현재 조합을 그대로 유지하면서 입력 도구를 열거나 닫을 수 있다. 이미 조합이 있는 상태에서 저 도구를 꺼내거나 닫으면 여러가지 문제가 발생할 수 있던 것을 다 해결했다.
Posted by 사무엘

