Windows 운영체제가 인식하는 실행 파일은 구조적으로 편의성의 상징인 GUI 프로그램과, 강력한 자동화의 상징인 콘솔(명령 프롬프트) 프로그램이라는 두 갈래로 나뉘어 있다. 이것은 SUBSYSTEM이라는 링커 옵션으로 지정 가능하다.
이 옵션이 콘솔로 되어 있으면 빌드 과정에서 링커는 C 라이브러리에서 main 함수를 찾아 호출하는 startup 코드를 연결하며, GUI로 지정되어 있으면 잘 알다시피 WinMain 을 호출하는 startup 코드를 연결한다. 해당 함수들은 물론 프로그래머가 따로 구현해 놓아야 한다.
어차피 GUI든 콘솔이든 EXE 파일이 제일 먼저 실행되는 지점은 실행 파일의 entry point에 지정된 주소이며 원래는 운영체제로부터 아무 인자도 전달되지 않는다. 그 대신, C 라이브러리가 GetModuleHandle, GetStartupInfo, GetCommandLine 등의 여러 기초적인 함수들을 먼저 호출하여 리턴값들을 WinMain에다가 전달해 줄 뿐이다.
콘솔 버전인 main도 마찬가지이다. 명령 옵션을 API 함수로 얻어 온 뒤, 그걸 C 라이브러리가 파싱하여 main에다가 argc와 argv의 형태로 전해 준다.
빌드 관점이 아닌 실제 실행의 관점에서 봐도, Windows는 콘솔 프로그램과 GUI 프로그램을 서로 약간 다른 방식으로 실행해 준다. 콘솔 프로그램의 경우 이미 명령창 같은 콘솔에서 실행되었다면 기존 콘솔을 자동으로 연결시키고, 프로그램이 탐색기 같은 GUI 환경에서 실행되어 콘솔이 없는 경우 “콘솔을 언제나 자동으로 생성”한다. 그 반면, GUI 프로그램에는 그런 조치를 취하지 않는다.
다만, 콘솔 프로그램이라고 해서 GUI 윈도우를 만들거나 메시지 loop을 돌지 말라는 법은 전혀 없으며, 반대로 GUI 프로그램도 추후에 자기만의 콘솔을 얼마든지 따로 생성해서 쓸 수 있다. 콘솔과 GUI를 적절한 혼용하면 유용한 경우가 의외로 매우 많다.
GUI 프로그램의 경우 디버깅 메시지를 찍기 위해 별도의 콘솔을 이용하는 것은 매우 흔한 테크닉이다. DOSBox가 대표적인 경우이다. 그리고 반대로 평소에는 명령창으로 문자열만을 취급하더라도, 가끔 그래프 같은 시각화된 결과물을 보여 줄 필요가 있을 때 제한적으로 GUI 윈도우를 생성하는 프로그램도 생각할 수 있다.
결국 GUI와 콘솔이 완벽하게 혼합된 프로그램이라면 이런 것도 가능해야 할 것이다.
프로그램을 아무 인자 없이 실행하거나, 또는 콘솔이 아닌 GUI 환경에서 실행하면 GUI가 나타난다. 반대로 콘솔에서 실행하거나 /? 같은 명령 옵션을 줘서 실행하면 콘솔로 메시지가 나타나고, 이미 콘솔이 있는 경우 그 콘솔을 사용한다. 압축 유틸리티 같은 게 이런 식으로 개발되어 있으면 아주 편리하지 않겠는가?
그런데 문제는 이 정도로 유연한 GUI/콘솔 하이브리드 프로그램을 만들기는 대단히 어려우며, 운영체제가 구조적으로 그런 것까지 고려하여 만들어지지는 않았다는 점이다. GUI와 콘솔 모두 2% 부족한 면모가 있다.
(1) 프로그램을 콘솔 방식으로 빌드하면, GUI 형태로 실행되어야 할 때에도 언제나 빈 콘솔창이 생겨 버린다. 프로그램이 실행되자마자 곧바로 API 함수를 호출하여 이 콘솔을 죽일 수는 있지만, 콘솔 창 같은 게 깜빡인 것이 사용자에게 그대로 드러나 보이기 때문에 이런 방식은 용납될 수 없다.
(2) 반대로 프로그램을 GUI 방식으로 빌드하면, 콘솔 환경에서 콘솔 형태로 실행되었을 때 기존 콘솔을 연결하는 방법이 없다. 콘솔 프로그램과는 달리 GUI 프로그램에서는 운영체제가 이것을 자동으로 해 주지 않는다. 콘솔에다 메시지를 찍는 것은 새로운 콘솔에다가만 가능하다. 기존 콘솔을 연결하는 AttachConsole이라는 함수가 차후에 추가되기는 했지만 방법이 완전하지 않다.
결국, 어느 방식을 선택하더라도 문제가 완전히 없을 수가 없다. 콘솔창을 필요할 때만 생성하면서 콘솔이 이미 존재하는 경우 기존 콘솔과 자동으로 연결이 되는 프로그램을 만들 수는 없는 것일까?
Visual Studio IDE인 devenv 프로그램은 이 문제를 해결한 듯해 보인다.
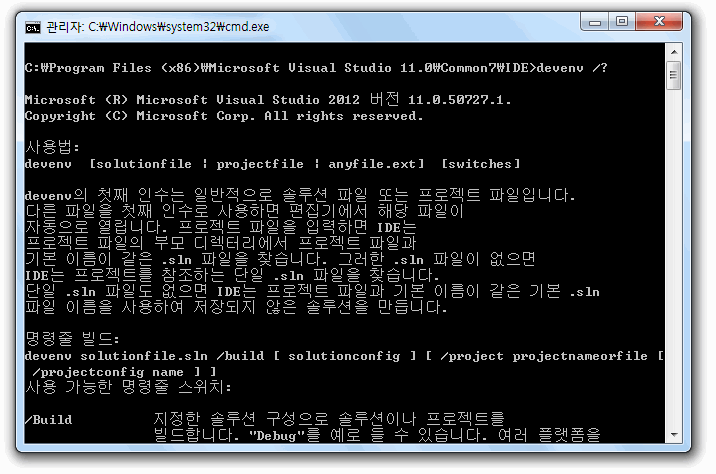
아무 인자를 안 주고 실행하면 잘 알다시피 커다란 IDE 창이 생긴다.
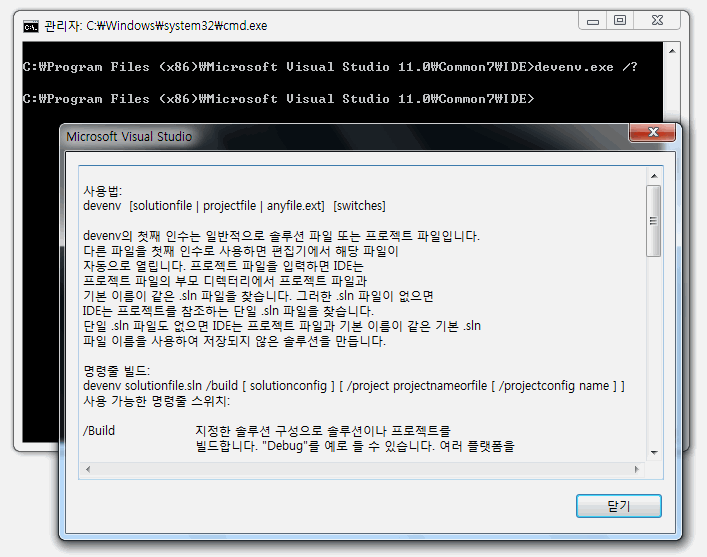
그러나 /? 를 주고 실행하면 각종 명령 옵션 사용법이 기존의 콘솔에다가 깔끔하게 찍힌다. 그냥 대충 도움말 창 하나 띄우고 끝인 게 아니다.
마소에서는 이것을 어떻게 구현하였을까?
그 비결은 너무 허무할 지경이다.
IDE 실행 파일이 있는 디렉터리를 가 보면, devenv 프로그램은 .exe도 있고 .com도 있어서 두 종류가 있다.
Windows는 도스 시절의 전통을 물려받았기 때문에 명령 프롬프트에서 사용자가 확장자 없이 실행 파일을 지정하면 EXE보다 COM을 먼저 실행한다. 그래서 COM은 /? 옵션 같은 걸 받아들이는 콘솔 프로그램으로 만들고, EXE를 GUI 프로그램으로 드는 꼼수를 쓴 것이다! devenv /?가 아니라 devenv.exe /? 라고 확장자를 강제 지정하면 명령 옵션 리스트가 역시나 대화상자 GUI 형태로 출력되는 걸 볼 수 있다. ^^
 |  |
요즘이야 COM이나 EXE나 모두 동일한 실행 파일이다. 오히려 COM 확장자를 사칭하여, 사용자가 의도한 프로그램 대신 악성 코드를 먼저 실행시키는 보안 위험이 문제되고 있는 지경이다. 마치 autorun 기능을 막듯이 COM의 실행을 막아 버리면 속 시원할지 모르나, 과거 프로그램과의 호환성 차원에서 그게 속 시원하게 가능할지는 모르겠다. 그래도 64비트 Windows는 아예 16비트 프로그램을 실행하는 기능 자체가 없어진 지 오래인데..
어쨌든, 실행 파일의 확장자로 콘솔용과 GUI용 프로그램을 구분시킨 건 Windows에서 배치 파일을 이용하여 자기 자신을 제거하는 프로그램을 만드는 것만큼이나 참 기발한 꼼수인 것 같다. 세상에 그런 방법을 쓸 줄은 몰랐다.
※ 추가 설명
1. Windows용 qt 라이브러리를 사용한 프로그램은 GUI 프로그램임에도 불구하고 main 함수에서 실행이 시작된다. 이것은 물론 qt 라이브러리의 내부에 WinMain 함수가 있어서 그게 사용자의 main 함수를 또 호출하기 때문일 것이다. MFC 라이브러리도 자체적인 WinMain 함수가 내부에 존재한다는 점을 감안하면 이는 충분히 수긍이 가는 디자인이다.
더구나 Windows를 제외한 다른 운영체제들은 실행 파일의 성격을 Windows처럼 GUI 아니면 콘솔 형태로 이분화하지 않으며 똑같이 main 함수를 쓴다. 그렇기 때문에, 크로스 플랫폼을 지향하는 qt는 응당 Windows에서의 프로그래밍 방식도 main을 기준으로 맞췄다고 볼 수 있다.
2. 과거의 16비트 Windows 시절에는 말 그대로 도스 프롬프트만이 있었을 뿐 콘솔이라는 게 없었다. 이것만으로도 그때 Windows는 구조적으로 기능이 굉장히 빈약했음을 알 수 있다.
Posted by 사무엘