사람의 정치 성향 스펙트럼이라고 해서 백지에다 4개의 구획을 만든 뒤, 좌우로는 말 그대로 좌파와 우파, 상하로는 권위주의와 자유주의(혹은 전체주의와 개인주의) 이렇게 두 축을 표시해 놓은 그림이 있다.
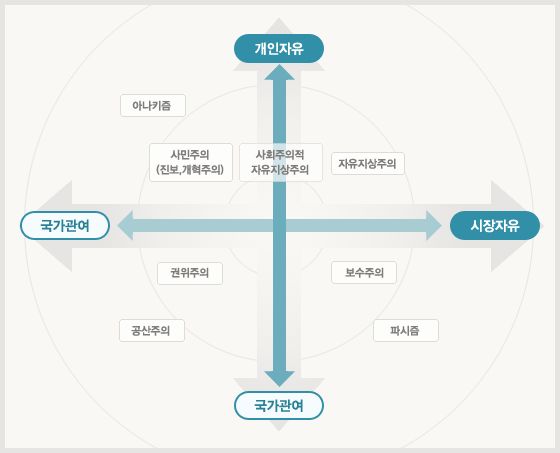
보다시피 둘은 서로 독립적인 변수이다. 좌파라고 해서 다 빨갱이가 아니며 그냥 무정부주의에 가까운 좌파도 있다. 우파 역시 맹목적인 자유뽕에 가까운 성향이 있는가 하면 ‘국익을 위해 멸사봉공’ 이러는 노선도 있다.
두 축에 대해서 하나는 개인에 대한 자유도(상하)이고, 다른 하나는 시장에 대한 자유도(좌우)라고 생각하면 딱 이해가 될 것 같다.
무슨 MBTI 검사하듯이 수십 가지 질문으로 설문 조사를 한 뒤, 자신의 정치 성향을 저 평면 위에다가 찍어 주는 웹 서비스가 많이 있다.
극좌와 극우에 대해서 "극과 극은 통한다" 같은 소리가 종종 나오는 건, 좌우 말고 상하 축이 '전체주의' 쪽으로 일치하기 때문일 가능성이 높다. 그건 좌와 우의 전체 입장을 대변하는 진술은 아닐 것이다.
그런데 사람의 이념뿐만 아니라 프로그래밍 언어의 설계 이념도 이런 식으로 분류 가능하다. 대표적으로 type을 취급하는 방식이다.
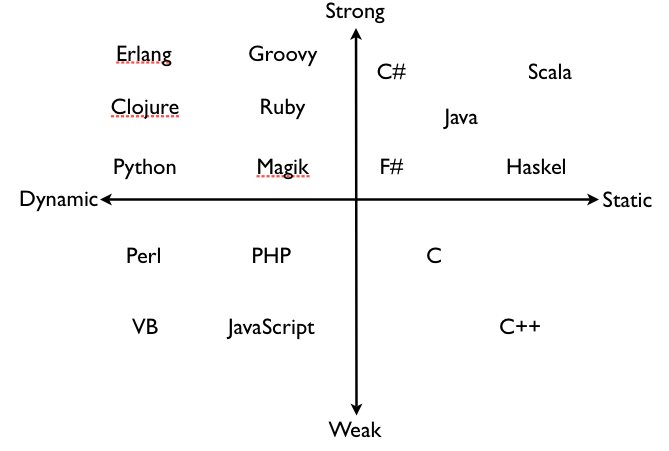
먼저 좌우로 static이냐 dynamic이냐 하는 속성이 있다.
변수의 type이 소스 코드에 미리 명시되어서 빌드 때 완전히 붙박이로 고정되는 건 static이다. 정수에는 정수만 집어넣을 수 있고, 문자열에는 문자열만 집어넣을 수 있다.
int a;
string b;
a = 100;
b = "Hello world!!";
그 반면, dynamic은 한번 변수를 선언했으면 거기에 아무 형태의 값이나 집어넣을 수 있다.
var a;
a = 100;
a = "Hello world!!";
우리가 접하는 '가벼운, 인터프리터' 성향의 프로그래밍 언어들은 dynamic type이다. 그러나 exe/dll 따위를 생성할 때 쓰이는 기계어 직통 컴파일 성향의 '무거운' 언어들은 대체로 static type인 편이다.
dynamic은 사람의 입장에서 입문과 코딩이 용이하다. 그러나 코드의 실행 성능은 타입을 꼼꼼히 지정해 주고 이 범위를 벗어나지 않는 static이 훨씬 더 뛰어나다. 코드의 양이 수백, 수천만 줄을 넘어갈 때의 유지보수 난이도과 총체적인 생산성도 static이 더 낫다.
둘의 차이는 똑같이 표 형태의 데이터를 입력하는데 엑셀(스프레드시트)과 전문 데이터베이스의 차이와 비슷하다.
엑셀은 아무 셀에나 아무 값을(숫자, 문자열, 날짜 시간 등..) 아주 자유롭고 편하게 입력할 수 있는 반면, DB는 각 셀별로 들어갈 수 있는 자료형과 크기를 정말 딱딱하게 미리 정해 놓고 그걸 지켜야 한다.
그러나 그 상태로 데이터의 개수가 수백· 수천만 개에 달하면? 데이터를 원하는 대로 검색하고 정렬하고 한꺼번에 변형하는 성능은 스프레드시트가 DB를 절대로 범접할 수 없을 것이다. 유도리, 자유도 같은 건 성능하고는 아무래도 상극이고 등가교환 관계일 수밖에 없다.
하지만 static 언어라 해도 타입이 뻔한 문맥에서 타입 명칭을 일일이 써 주는 건 귀찮고 번거롭다. 특히 변수를 선언과 함께 초기화할 때 말이다. 대입하려는 우변의 값에 타입을 암시하는 정보가 어지간해서는 이미 포함돼 있기 때문이다.
그렇기 때문에 C++에서는 auto라는 파격적인 키워드가 도입돼서 변수 자체의 타입은 static하게 결정되더라도 최소한 int, string 같은 타입명을 번거롭게 쓸 필요는 없게 하고 있다.
또, 템플릿 메타프로그래밍이니 제네릭이니 하는 것을 도입해서 static type 언어이더라도 한 코드를 다양한 type에 대해서 범용적으로 활용 가능하게 해 놓았다. dynamic type 언어라면 저런 물건이 태생적으로 존재할 필요가 전혀 없을 것이다.
함수를 호출할 때는 보통은 값을 인자로 넘기고 값을 리턴값으로 받는다. 그런데 저런 패러다임 하에서는 함수를 호출하거나 클래스의 인스턴스를 선언하면서 타입까지도 인자로 넘기게 된다. 물론 이건 여느 함수 인자와는 성격이 많이 다르기 때문에 통상적인 괄호가 아닌 < >로 감싸고 전달하는 위치도 따로 구분돼 있다.
부등호로만 쓰이던 이항 연산자 < >가 여닫는 괄호처럼 쓰이니 이건 굉장한 발상의 전환이다. 이제는 소스 코드의 파싱도 마냥 단순무식이 아니라 주변 문맥을 의식하면서 해야 하게 됐다.
외형은 비슷해 보여도 C++의 템플릿은 C#/Java 같은 언어들의 제네릭과는 성격이 완전히 극과 극으로 다른 물건이라는 것이 주지의 사실이다. C++ 템플릿이 제네릭보다 자유도가 더 높고 화끈=_=하기는 하지만.. 이건 템플릿의 소스를 몽땅 까고, 서로 다른 템플릿 인자에 대해서 컴파일과 코드 생성이 매번 다시 행해지는 무식한 댓가를 치르는 덕분에 제공되는 장점이다.;;;
참고로 값과 타입에 이어서 { }로 감싸는 함수 몸체 자체까지 함수의 인자와 리턴값으로 마구 주고받을 수 있는 건 그 이름도 유명한 함수형 패러다임이 된다. 이게 제일 나중에 도입돼 있다.
자, static과 dynamic 타입에 대한 소개는 이 정도로 된 듯하고, 다음으로 상하 세로축을 살펴보자.
strong이냐 weak냐 하는 속성은 type safety에 관한 것이다.
서로 관련이 없는 타입의 값끼리 형변환을 알아서 쓰윽 해 주고 위험한 형변환도 별 탈 없이 허용하는 편이면 type safety가 weak인 것이다.
그렇지 않고 뭐 하나 하려면 깐깐하게 형변환 함수를 수동으로 매번 호출해야 한다면, 타입 관련 오류는 대부분 컴파일 때 다 걸러지고 런타임 때 딱히 문제가 발생할 일이 없다면 그런 언어는 strong이다. 단적인 예로,
a = 200 + "abc";
이런 구문을 알아서 "200abc"라고 접수해 주면 weak이고, 숫자와 문자열을 한데 섞을 수 없다고 까칠하게 에러를 내뱉으면 strong인 편이다.
그러면 static인 언어가 strong인 편이고 dynamic인 언어가 weak가 아니겠냐고 편견을 가질 수 있지만.. 실제로는 꼭 그렇지 않다.
같은 dynamic type 언어 중에서도 Visual Basic, JavaScript, 문자열의 유연한 조작에 특화된 Pearl, 그리고 PHP..;; 같은 언어들은 weak로 분류된다.
그 반면, 파이썬은 dynamic type 언어이지만 strong이라고 여겨진다. 둘은 아까 정치 성향과 마찬가지로 서로 별개의 개념이다.
특히 C/C++은 static이면서 weak인 매우 이례적인 언어이다. 이 범주에 드는 언어 자체가 사실상 얘들밖에 없다.
타입 시스템이 static인 것이야 의심의 여지가 없는데, C는 그에 덧붙여 type safety가 굉장히 개판이고 안전 장치가 빈약하기 때문이다.
숫자에서는 enum과 int를 제멋대로 섞어 써도 아무 문제가 없는 것, 0이 포인터와 정수에서 모두 통용되는 것, bool과 숫자의 구분도 없는 것, 관련 없는 타입의 포인터끼리의 대입이 굉장히 관대한 것, 타입의 통제 따위는 전혀 받지 않는 무식한 memcpy와 malloc이라든가 매크로 함수..;; 그리고 부동소수점 숫자의 내부 구조까지 뜯어볼 수 있는 공용체와 비트필드는 C/C++ 말고 도대체 어느 언어에서 찾아볼 수 있을까???
그나마 C++에 와서 무질서도가 눈꼽만치 개선됐다. explicit와 enum class도 도입되고 true/false 상수라든가 nullptr도 도입되면서 type safety를 강화하려고 애쓰는 중이다. 하지만 C++의 type safety는 Java나 C#에 비할 바는 못 된다고 여겨진다.
현대의 언어들은 static/dynamic이야 언어의 취향과 용도에 따라 달라지지만 type safety에 대해서는 strong을 추구하는 쪽으로 바뀌는 추세이다. weak인 언어는 당장 표현은 간결하게 할 수 있고 자유도가 더 높지만.. 안전하다는 보장이 없기 때문이다. 방대한 코드에서 갑자기 버그· 오류가 발생했을 때 지뢰가 어디에 숨어 있는지를 알기가 너무 어려워진다.
따지고 보면 제네릭이 도입된 것도 무식한 void*나 Object 떡칠만 하는 것보다 더 안전하게 코드를 작성하기 위해서이다.
Posted by 사무엘