우리는 학교에서 산수를 배우면서 덧셈을 가장 먼저 배우고, 그 뒤 이들을 묶은 형태인 곱셈을 배운다. 그리고 나중에는 곱셈을 묶은 거듭제곱이라는 걸 배운다. 그런데 덧셈이나 곱셈과는 달리, 거듭제곱은 같은 수를 곱하기를 반복한다는 직관적인 정의만 적용해서는 정수가 아닌 형태의 거듭제곱을 생각하기가 쉽지 않다.
지수법칙이 있으니 유리수 승까지는 그래도 괜찮다. 정수 승과 정수 제곱근으로 설명이 가능하기 때문이다. 하지만 이를 초월하여 2^sqrt(2)처럼 임의의 실수 승은 어떻게 해야 계산하고 표현할 수 있을까?
거듭제곱을 모든 실수 범위에서 정의함으로써 지수함수라 불리는 연속인 함수의 형태로 영역을 확장하는 데는, '연속'이라는 개념에서 알 수 있듯, 미분의 도입이 큰 기여를 했다. 자연상수 e가 발견되고 로그 함수라는 게 생기면서 지수함수는 로그의 역함수로서 정체성을 확립하게 되었다.
이 글에서 수학적으로 엄밀한 디테일을 다 말할 수는 없지만, e는 임의의 수에다 제곱근을 반복하면서 지수가 0에 가까워지고 원래 수가 1에 한없이 가까워질 때 그 수의 소숫점, 다시 말해 숫자에서 1을 뺀 값이 지수와 어떤 비례 관계가 있는지를 규명하는 과정에서 발견되었다. (1+1/n)^n에서 n의 무한대 극한이라는 원론적인 정의가 바로 거기서 유래되었으며, 사실, (1+x/n)^n라고 해 주면 그냥 exp(x)를 바로 구할 수 있다.
exp(x)는 0인 지점에서 기울기가 1이다. 그리고 미분해도 도함수가 자기 자신과 같다는 매우 중요한 특징이 있다. 즉, y=exp(x)에 있는 점 (x, y)의 기울기는 곧 y라는 뜻. 그럼 이놈의 역함수는 어떻게 될까? 본디 함수와 그 역함수는 y=x에 대해 대칭이므로, 점 (y, x)의 기울기는 곧 1/y여야 한다.
미분하면 1/x가 되는 함수를 찾아보니 다름아닌 ln x이다. 복잡한 거듭제곱을 곱셈으로, 곱셈은 덧셈으로 바꿀 수 있는 놀라운 함수 말이다. 그래서 exp는 로그의 역함수인 고로 그 정체가 e^x인 지수함수라는 결론이 도출되고, 그래서 로그와 지수의 함수 관계가 완성될 수 있었다.
a^b = e^(b ln a)이다. ln a^b는 b ln a이므로 양변에 자연로그를 씌우면 아주 자연스럽게 유도 가능하다.
또한 굳이 밑이 e가 아닌 임의의 a인 로그를 생각하더라도, log[a] b = ln b / ln a이다. 이것은 지수보다는 약간 연상이 쉽지 않을지 모르나, 이 경우를 생각해 보자. 로그의 정의상 당연히 a^(log[a] b) = b이다. 이 식 자체에다가 자연로그를 씌우면 log[a] b * ln a = ln b가 되고, 그 후의 논리 전개는 생략. ㄲㄲ
이건 굉장히 유용한 특징이다. 이 덕분에 exp와 ln만 있으면 우리는 임의의 지수의 값도 구할 수 있고, 임의의 로그의 값도 구할 수 있게 된다.
그럼 이 함수의 값을 실제로 컴퓨터로 어떻게 계산하면 좋을까?
이걸 연구하는 분야는 기호, 순수함, 추상성만을 좋아하는 전통적인 수학에서 벗어나 일면 '지저분한 이단아'처럼 보일 수도 있는 수치해석 쪽으로 가게 된다. 컴퓨터에서 exp, ln, cos, sin 같은 기초적인 초월함수의 값을 조금이라도 더 빠르고 정확하게 구하는 기법은 이미 천재 컴덕후, 수학자, 공학자들이 연구할 대로 다 연구해서 소프트웨어 정도가 아니라 아예 하드웨어에 회로에 다 코딩되어 있을 정도이다.
그러니 내가 거기에 뭔가를 더 기여할 게 있다고 여겨지지는 않는다. 단지 본인은 핵심적인 아이디어만 직접 짜 보고 넘어갈 생각이다.
초월함수들의 근사값을 계산하는 아이디어도 미분에서 유래되었다. 단순히 1차함수 접선을 구하는 것을 넘어서 곡선과 가장 가까운 n차 근사 다항식을 구하는 것으로 생각을 확장하면 '테일러 근사 다항식'이라는 걸 구할 수 있고, 무한히 미분 가능한 함수에 대해서는 무한합인 그 이름도 유명한 테일러 급수라는 걸 유도할 수 있다.
* 이말년 씨리즈와 Taylor series는 서로 느껴지는 포스가 확 다르다. 흠.;;;
exp(x)는 예전에도 글로 썼듯이, 원론적인 정의를 이용해서 값을 구할 리는 절대 없고, 테일러 급수를 쓴다. 아래의 코드는 16항 정도까지 계산했다.
double pseudo_exp(double x)
{
double v=1.0, p=x,q=1.0;
for(int i=1; i<=16; i++, v+=p/q, p*=x, q*=i);
return v;
}
단, 이 급수는 x=0인 지점을 기준으로 구한 것이기 때문에 x가 8~9 정도만 넘어가도 오차가 상당히 커진다. 하지만 컴퓨터 부동소숫점에도 한계가 있으니 항을 한없이 많이 계산할 수도 없는 노릇이고, 큰 수에 대해서는 다른 방법으로 보정이 필요할 듯하다.
한편, 로그는 어떻게 구할까?
자연로그도 다음과 같은 직관적인 형태의 테일러 급수가 있긴 하다.
ln (1+x) = x (+-) x^n/n (n이 짝수일 때는 빼기, 홀수일 때는 더하기)
그런데 이 급수는 x가 -1 초과 1 미만일 때만 유효하고, 따라서 0과 2 사이의 로그값만 구할 수 있다. 나머지 범위는 항을 제아무리 많이 계산해 줘도 아예 원천적으로 원함수와 전혀 일치하지 않게 된다. 테일러 급수가 모든 범위에 대해서 무조건 만능은 아님을 알 수 있다.
하지만 지수함수와는 달리 로그는 ln ab = ln a + ln b라고 큰 숫자를 한없이 쪼개는 마법과 같은 공식이 있다. 그러므로 저것만 있어도 아무 수의 로그라도 구할 수 있다.
즉, ln 2의 값을 미리 갖고 있다가 임의의 수에 대해서 2보다 작아질 때까지 ln 2를 따로 더하면서 계속 2로 나누면 된다. 2는 잘 알다시피 2진법을 쓰는 컴퓨터가 좋아하는 수이기도 하고 말이다. 그래서 주어진 수가 2 이하의 범위에 들어오면 그때 급수를 써서 최종적으로 구한 로그값을 또 더하면 된다.
double pseudo_ln(double x)
{
#define LN_2 0.693147180559945
double v=0;
while(x>2.0) x/=2.0, v+=LN_2;
double x_min1 = x-1, xm = x_min1;
for(int i=1; i<=16; i++, xm*=x_min1)
if(i&1) v+=xm/i; else v-=xm/i;
return v;
}
단, 이 급수의 아쉬운 점은 x가 0이나 2라는 양 극단에 가까워질 때 정확도가 꽤 크게 떨어진다는 점이다. 이는 계산하는 항의 수를 충분히 크게 잡아도 쉽게 극복되지 않는다.
그래서 성능면에서 실용적인 가치는 별로-_- 없지만, ln이 exp의 역함수라는 점을 이용하여, 기존 exp 함수로부터 방정식 근 찾기 기법을 이용하여 로그를 구하는 방법도 이 기회에 실습하게 되었다. 그게 없으면 무엇보다도 초기에 정확하게 값이 구해진 채 공급되어야 하는 LN_2 내장값은 또 어떻게 구하겠는가?
일변수 방정식의 근을 찾는 기법은 수치해석 교재에서 가장 먼저 다뤄지는 기초 주제이다.
exp(x)는 기복이 없으며 그래프 모양이 워낙 예쁘고 원천적이기-_- 때문에, 근이 존재하는 초기 구간만 잡아 주면, 어떤 근 찾기 알고리즘을 쓰더라도 근을 구할 수는 있다. 단지 얼마나 빨리 수렴하여 구해 내느냐가 문제일 뿐이다. 애초에 지수 함수 정도면 범용적인 방정식 근 찾기 알고리즘이 과분하게 느껴질 정도로 특징이 너무 분명하기도 하고 말이다.
가장 먼저 나오는 것은 이분법(bisect)이다. 이게 자료구조에서는 이분법이라고 하면 이분 검색처럼 log n 시간 만에 문제를 푸는 효율적인 알고리즘이라고 불리는 반면, 수치해석에서는 정수 개의 discrete한 데이터가 아니라 사실상 연속인 구간을 다룬다. 그렇기 때문에 통상적인 이분법조차도 수렴이 느린 비효율적인 방법으로 간주된다.
double solve_bisect( double (*pfn)(double), double v )
{
double f=-10.0, t=10.0; int nt=0;
while(1) {
double d = (f+t)/2.0;
double p = pfn(d) - v;
if(fabs(p) < 0.000001) break;
if(p > 0) t=d; else f=d; nt++;
}
return f; //nt는 계산 횟수 counter
}
double pseudo_ln2(double x)
{
return solve_bisect(pseudo_exp, x);
}
근 찾기 알고리즘 중에서는 뉴턴-랩슨(혹은 그냥 뉴턴) 법이 수렴이 매우 빠른 알고리즘으로 여겨지고 있다. 이 방법은 이분법과는 달리 시작점과 끝점이라는 구간을 잡고 시작하는 게 아니라 시작점에서 해당 방정식의 접선을 그은 뒤, 접선과 x축이 만나는(y=0) 지점을 다음 점으로 잡는다. 이 작업을 방정식의 값이 근인 0과 충분히 가까워질 때까지 반복한다.
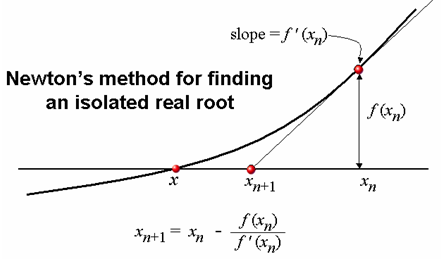
방정식 f(x) 위의 점 (x_0, f(x_0))을 지나는 접선의 방정식은 기울기가 f'(x_0)일 테니 y=f'(x_0)*x + f(x_0) -f'(x_0)*x_0이 된다. 그래야 x에다가 x_0을 집어넣었을 때 f'(x_0) 나부랭이는 소거되고 함수값으로 f(x_0)만 남기 때문이다.
이 접선이 y=0을 만족시키는 다음 점 x_1을 방정식으로 풀면 x_1=x_0 - f(x_0)/f'(x_0)이라는 생각보다 깔끔한 식이 나온다. 이를 코딩하면,
double solve_newton( double (*pfn)(double), double (*pfn_prime)(double), double v )
{
double d = 0.0; int nt=0;
while(1) {
double p = pfn(d) - v;
if(fabs(p) < 0.000001) break;
d = d - p / pfn_prime(d); nt++;
}
return d;
}
double pseudo_ln3(double x)
{
return solve_newton(pseudo_exp, pseudo_exp, x);
}
뉴턴 법 함수는 도함수의 포인터를 별도로 받는데, exp는 어차피 도함수가 자신과 동일하므로 자신을 한번 더 넘겨주면 된다는 점도 특징이다.
프로그램을 실제로 돌려 보면 알겠지만, 동일 오차 범위를 줬을 때 뉴턴 법은 이분법보다 통상 2~5배나 더 빨리 수렴하는 걸 볼 수 있다. 마치 퀵 정렬이 pivot을 기준으로 자료가 그럭저럭 이미 정렬돼 있을수록 더욱 빨리 동작하고 자료의 상태에 민감하듯, 뉴턴 법은 접선과 가까운 형태의 부드러운 곡선일수록 수렴이 더욱 빨라진다.
자, 지금까지 공대 학부 수준의 아주 허접한 수학 덕질을 감각 유지 차원에서 잠시 복습해 보았다. 각종 공식들이 유도되는 원리를 좀 더 깊이 생각해 보고 싶으나 시간과 여유가 부족하다.
아, 수학에서는 거듭제곱뿐만이 아니라 팩토리얼까지도 자연수가 아닌 실수, 그리고 복소수 범위에까지 정의하고 그 증가폭을 측정하는 방법에 대해 연구가 진행돼 있다. 그 일환으로 ln n!이 n log n - n과 얼추 비슷하다는 스털링의 공식이 있고, 그보다 더 괴랄한 감마 함수라는 것도 있어서 z! = Γ(z+1)이다. 머리 좋은 똘똘이들의 수학 덕질의 끝은 도대체 어디까지인지를 다시 생각하게 된다.
Posted by 사무엘

