1. 그레이스케일
이건 이미지를 흑백 형태로 바꾸는 것이 핵심이다. 색을 구성하는 정보량의 차원이 줄어들고(3차원 → 1차원으로) 결과적으로 전체 색깔수가 줄어들기는 하지만(수천~수십만 종류의 색상 → 256단계의 회색), 그래도 아예 B&W 단색으로 바꾸는 건 아니다.
각 픽셀들은 색상과 채도가 제거되고 명도만 남아서 흑부터 백 사이에 다양한 명도의 회색으로 기계적으로 바뀐다. 같은 색의 픽셀이 인접 픽셀이 무엇이냐에 따라서 다르게 바뀐다거나 하지는 않는다.
그런데 그레이스케일 공식이 딱 하나만 존재하는 게 아니다. RGB 세 성분의 산술평균을 주면 될 것 같지만, 그렇게 그레이스케일을 하면 그림이 굉장히 칙칙하고 탁하게 보이게 된다.
똑같이 최대값 255를 주더라도 빨강(255,0,0), 초록(0,255,0), 파랑(0,0,255) 각 색별로 사람이 인지하는 명도는 서로 일치하지 않는다. VGA 16색 팔레트를 다뤄 본 사람이라면, 밝은 빨강이나 밝은 파랑을 바탕으로는 흰 글자가 어울리지만, 밝은 초록은 그 자체가 너무 밝아서 흰 글자가 어울리지 않는다는 것을 알 것이다.

그러니 공평하게 33, 33, 33씩 가중치를 주는 게 아니라 거의 30, 60, 10에 가깝게.. 초록에 가중치를 제일 많이 부여하고 파랑에는 가중치를 아주 짜게 주는 것이 자연스럽다고 한다.
이런 공식은 누가 언제 고안했으며 무슨 물리 상수처럼 측정 가능한 과학적인 근거가 있는지 궁금하다. 옛날에 흑백 사진을 찍으면 색깔이 딱 저 공식에 근거한 밝기의 grayscale로 바뀌었던가?
본인은 저 그레이스케일 공식을 태어나서 처음으로 접한 곳이 아마 QBasic 내지 QuickBasic의 컬러/팔레트 관련 명령어의 도움말이었지 싶다.
2. 디더링
이건 그레이스케일과 달리, 색깔수를 확 줄이는 것이 핵심이다. 그 대신 반드시 단색 흑백이어야 할 필요가 없다. 가령, 트루컬러를 16색으로 줄이는 것이라면 RGB 원색이 살아 있는 컬러라 할지라도 디더링의 범주에 든다. 이런 것처럼 말이다.
디더링에서는 어떤 원색을 직통으로 표현할 수 없을 때 근처의 비슷한 여러 색들을 고르게 흩뿌려서 원색과 비슷한 색감을 나타낸다. 팔레트까지 임의로 지정이 가능하다면 256색 정도만 돼도 생각보다 그럴싸하게 원래 이미지를 재현할 수 있다. 그런 게 아니라 그냥 흑백 단색 디더링이라면 아까 그레이스케일처럼 어떤 공식에 근거해서 명도를 추출할지를 먼저 결정해야 할 것이다.
0부터 1까지 가중치별로 점을 골고루 균등하게 뿌리는 공식은 이미 다 만들어져 있다. 이건 Ordered dither이라고 불리며, 보통 8*8 크기의 64단계 격자가 쓰이는 편이다. 그 구체적인 방식에 대해서는 수 년 전에 이 블로그에서 이미 다룬 적이 있다.
그레이스케일은 RGB(0.4,0.2,0.6)라는 색을 0.3이라는 명도로 바꾸는 것에 해당하는 기술이고, 단색 디더링은 이 색이 0.3, 0.3, 0.3 … 이렇게 쭉 이어지는 것을 1, 0, 0, 1, 0, 0 이런 식으로 이산적으로 표현하는 것과 같다.
그런데 원색을 기계적으로 이런 격자로 치환하기만 하면 보기가 생각보다 굉장히 좋지 않다.
원래 0.3을 표현해야 하는데 지금 지점에서 부득이하게 1을 찍어 버렸다면 0.7이라는 오차의 여파를 인접 픽셀에다가 떠넘겨서 거기서 계속해서 감당하게 해야 한다. 즉, 그레이스케일은 그냥 인접 픽셀을 신경 쓰지 않고 픽셀 대 픽셀 변환만 했지만 디더링은 그렇지 않다. ordered dither 내지 더 단순무식한 nearest color 찍기 신공이 아니라면.. 이전 픽셀에서 발생한 오차를 수습하는 error diffusion을 동원해야 부드러운 결과물이 나온다.
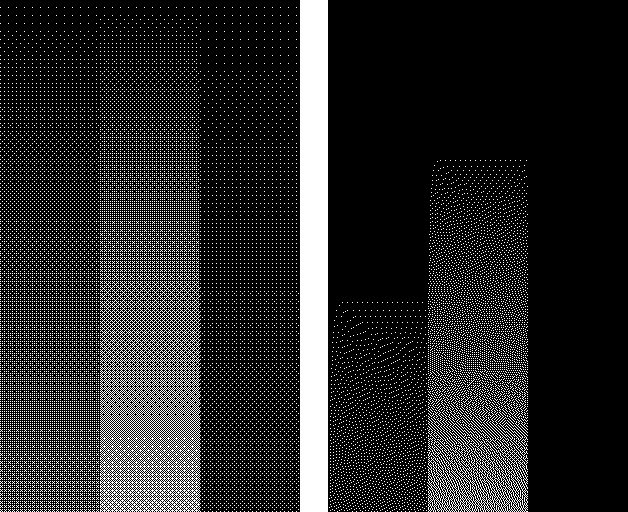
그런 지능적인(?) 디더링 알고리즘은 196~70년대에 컴퓨터그래픽이라는 분야가 등장한 초창기부터 연구되어 왔으며, 고안자의 이름을 따서 Floyd-Steinberg, Burks, Stucki 같은 알고리즘이 있다. 이미지를 다루는 사람이라면 포토샵 같은 그래픽 편집 프로그램에서 저런 명칭들을 본 적이 있을 것이다.
이런 알고리즘들은 ordered dither와 달리, 점들이 일정 간격으로 산술· 기계적으로 단순 투박하게 찍힌 게 아니라 뭔가 한땀 한땀 손으로 입력된 것 같고 부드러운 느낌이 든다. 그리고 무엇보다 색깔이 크게 바뀌는 경계 영역이 훨씬 더 선명하다.
3. 하프톤 (망점)
그레이스케일이 색깔 표현에 제약이 없는 아날로그 영상물(특히 흑백 필름 사진) 같은 느낌이 나고, 디더링은 초기에 해상도와 색상이 부족했던 디지털 영상과 관계가 있다면.. 하프톤은 색상이 부족한 대신 해상도가 높은 '인쇄물'과 관계가 깊은 기법이다.

하프톤은.. 일정 간격으로 망점을 두두두둑.. 찍고, 그 망점의 크기/굵기만으로 명도를 조절한다. 깨알같은 점들의 양과 배치 방식을 고민하는 통상적인 디더링과는 문제 접근 방식이 약간 다르다.
출력물의 해상도가 영 시원찮은 데서 하프톤을 동원하면 망점이 너무 커서 눈에 거슬릴 수 있다. 회색을 만들려고 했는데 하양과 검정이 그대로 눈에 띄게 된다는 것이다.
그러나 아무 인쇄물에서나 흑백이든 컬러든 문자 말고 음영(색깔 배경)이나 사진을 하나 보시기 바란다. 전부 촘촘한 점들로 구성돼 있다.
컴퓨터용 프린터나 전문 출판물 인쇄기들이 무슨 수십~수백 종에 달하는 물감을 갖고 있지는 않다. 잉크는 3원색에다가 검정 이렇게 4개만 갖고 있고, 나머지 색은 전부 얘들을 적절한 배율로 섞은 망점의 조합만으로 표현한다.
컴퓨터에서 보는 사진 이미지를 프린터로 출력하기 위해서는 가산 혼합 기반인 RGB 방식의 색을 감산 혼합 CMYK 방식으로 변환하고, 색 축별 망점 배합을 계산해야 할 것이다. 이건 디더링과는 다른 영역이다. 프린터 드라이버가 하는 일 중의 하나가 이것이며, 전문적인 사진이나 출판 프로그램 역시 색 축별로 인쇄 형태의 저수준 데이터를 export하는 기능을 제공한다.
그래도 요즘은 사진조차 필름 현상이 아니라 디지털 카메라로 찍은 뒤에 포샵질을 하고 고급 인화지에다 '인쇄'해서 만들어 내는 세상이니.. 컬러 인쇄 기술도 예전보다 굉장히 많이 좋아지고 저렴해졌다. 1990년대까지만 해도 가정용으로 컬러 레이저 프린터라는 걸 생각이나 할 수 있었겠는가?
유니코드 문자 중에 U+2591 ~ U+2593은 단계별 음영을 나타낸다.
굴림· 바탕 같은 통상적인 Windows 글꼴은 이를 하프톤 형태로 표현한 반면, 함초롬바탕은 디더링 형태로 표현했음을 알 수 있다.
윤곽선 글꼴의 래스터라이즈 방식의 특성상 디더링보다는 하프톤이 부담이 덜하기도 하다. 윤곽선 글꼴은 뭔가 덩어리· 군더더기가 늘어날수록 출력 성능이 급격히 떨어지기 때문이다. 그래서 매끄러운 곡선 말고 오돌토돌, 쥐 파먹은 효과 같은 걸 표현한 글꼴은 크기도 크고 처리하기 버거운 편이다.

이상이다. 이 사이트에도 그레이스케일, ordered 디더링, 기타 휴리스틱-_- 디더링, 그리고 하프톤까지 다양한 사례가 소개되어 있으니 관심 있는 분은 참고하시기 바란다.
우리가 사는 공간이 3차원일 뿐만 아니라, 시각 정보의 기본 단위인 색깔이라는 것도 어떤 방식으로 분류하든지 결국 3개의 독립된 축으로 귀착된다는 게 신기하지 않은가? 신학에서는 이게 하나님의 속성인 삼위일체와 관계가 있다고도 말하는데, 그건 뭐 결과론적인 해석이며 물증이라기보다는 심증 수준에서 만족해야 하지 싶다.
음악에서는 음계, 음정, 화성학 같은 이론이 수학과 연결되어 오래 전부터 연구돼 왔다.
그럼 일명 color theory라고 불리는 분야는 언제부터 누구에 의해 연구돼 왔을까? RGB, CMY, HSL 사이를 변환하는 공식 같은 것 말이다. 더디링은 컴퓨터그래픽 영역이겠지만 순수하게 색에 대한 수학적인 분석은 미술과 전산학 어디에도 딱 떨어지지 않아 보인다. 내가 알기로는 전파로 영상을 주고 받는 텔레비전 기술이 개발된 20세기 초쯤에야 이런 분야가 개척됐다.
본인이 색과 관련하여 감이 오지 않고 아직도 좀 알쏭달쏭한 걸 얘기하면서 글을 맺도록 하겠다.
모니터 화면 같은 건 그 본질이 빛이며, 빛은 색을 태생적으로 지니고 있다. 그러나 다른 세상 만물들, 특히 인쇄물은 색만 있지 빛은 지니고 있지 않다. 조명을 받아야만 자기 색을 비춰 보일 수 있다.
빛은 원색이 RGB라고 여겨지며, 섞일수록 더 밝아져서 최종적으로 white에 도달하는 ‘가산 혼합’을 한다. 그러나 빛이 없는 나머지 사물의 색들은 섞일수록 더 어두워져서 최종적으로 black에 도달하는 ‘감산 혼합’을 한다. 이 정도는 이미 초등학교 미술 시간에 배운다.
다만, 빛의 3축과 색의 3축은 노랑/초록 말고 빨강/파랑 부분도 서로 미묘하게 차이가 난다는 것부터는 고등교육 이상의 영역으로 보인다. 본인도 그걸 대학 이후에나 접했기 때문이다.
왜 그런 차이가 나는지에 대해서는 논외로 하더라도, 빛이건 색이건 두 색상을 물리적으로 섞지는 말고 디더링 하듯이 오밀조밀 가까이 배치시켜 놓으면 멀리서 볼 때 정확하게 어떤 혼색이 나타날까? 이걸 잘 모르겠다.
이건 빛이든 인쇄된 색이든 차이가 없어야 하지 않을까? 그리고 만약 차이가 없다면 그 결과는 감산 혼합이나 가산 혼합 중 어느 것과도 정확하게 일치하지 않을 것이다. 그 관계가 무엇일까? 마치 산술/기하/조화 평균처럼 서로 비슷하면서도 미묘하게 다른 결과가 나오지 않을까 싶다.
이해를 돕기 위해 아래 그림을 살펴보자. 반드시 확대/축소 왜곡되지 않은 원래 크기 형태로 볼 것!! (화면 확대 배율도 96DPI/100%로 맞춰야 함)
왼쪽은 그냥 RGB(0,0,0) 검정과 RGB(255,255,255) 하양을 1:1로 섞은 것이고, 오른쪽은 RGB(0,0,255) 파랑과 RGB(0,255,0) 초록을 섞어서 청록을 만든 것이다. 여기서 섞었다는 것은 픽셀 디더링을 말한다. 그리고 우측 하단에는 본인이 보기에 이들과 가장 비슷하다고 생각하는 순색(solid color)을 칠해 보았다.
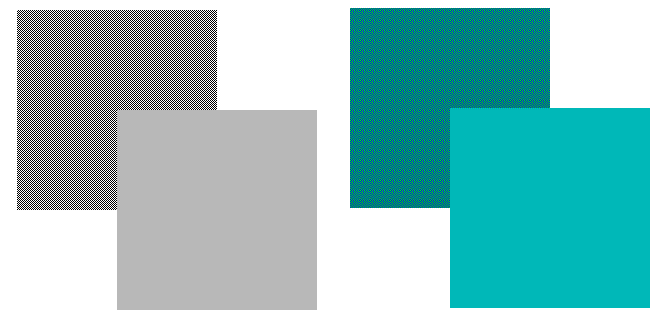
255짜리 순색 파랑 255짜리 순색 초록을 섞어서 가산 혼합이 됐다면 RGB(0,255,255) 밝은 cyan 청록이 나타나야 하겠지만 실제로는 전혀 그렇게 되지 않았다. 그런데 그렇다고 해서 평균인 128짜리의 훨씬 어두운 색이 된 것도 아니다.
본인이 보기에 가장 비슷한 순색의 명도는 대략 180~184 정도이다. 생각보다 제법 밝다. 아.. 그래서 옛날에 VGA 팔레트도 어두운 색을 무식하게 128로 지정하지 않고 170 정도의 값을 줬는가 싶은 생각이 든다. 다른 색과 섞었을 때 재현 가능한 색이 나오라고 말이다.
이런 현상을 설명하기 위해 감마 보정 등 다른 어려운 이론들도 나온 게 아닌지 추측해 본다. 디더링 알고리즘이란 게 내가 생각했던 것보다 여러 단계로 나뉘고 더 어렵고 복잡할 수도 있겠다는 생각이 든다. 적절한 명도 추출하기, 적절히 대체색으로 분비하기, 오차 보정하기 등..;; 시각 디자인의 세계는 오묘하다.
Posted by 사무엘