본인은 박사 과정에 진학해서 수업을 다 듣고 종합 시험도 통과한 뒤, 지난 2년이 넘는 기간 동안 휴학을 했다. 그리고 그 기간 동안 날개셋 한글 입력기는 8.6에서 9.7까지 올라갔다.
입력기 연구의 연장선에다가 글꼴 연구도 새로 접목하는 것을 목표로 진학했었는데, 입력기 연구가 당초 계획보다 다소 오래 걸렸다.
이제 입력기는 파일 포맷과 엔진 구조를 다 뜯어고칠 정도로 너무 비현실적인 추상화(재설계나 리팩터링), 아니면 너무 이상적인 수준의 기능을 제외하고 어지간히 규칙 기반 한글 입력과 관련된 것들은 다 통달했으며 잘 실현됐다. 9.7도 특별히 심각한 문제 없이 아주 잘 만들어졌다.
다만, 날개셋은 TSF 기반의 한글 IME일 뿐만 아니라 반대로 타 IME들을 구동해 주는 텍스트 에디터이기도 하니.. 요즘은 편집기에서 타 IME를 구동하는 동작과 관련된 이슈들을 좀 살펴보고 있다.
1. 내 프로그램에서 9.7 이후로 개선된 사항
(1) 외부 모듈의 옛한글 조합을 여느 블록(selection)과 달리 취급
날개셋 편집기에서 입력 항목을 '빈 입력 스키마'로 고르면 앞서 언급한 바와 같이 자체 입력기가 아니라 다른 외부 IME들을 사용할 수 있다.
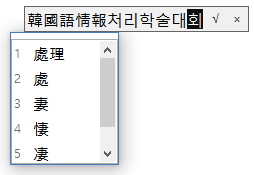
그런데 한글 IME로 현대 한글을 조합할 때는 깜빡이는 네모 cursor가 나타나는 반면, 옛한글을 조합할 때는 조합이 그냥 블록 형태로 잡힌다. 그래서 자체 입력기로 옛한글을 입력할 때와는 달리 이질적이고 아마추어스러운 느낌이 난다.
이건 일차적으로는 운영체제에서 옛한글처럼 내부적으로 2개 이상의 코드값으로 표시되는 한글에 대한 배려를 안 해서 그렇다. 조합 문자열이 한글로만 이뤄져 있을 때 응용 프로그램이 강제로 보정을 해서 깜빡이는 네모 cursor를 구현하라면 할 수도 있다.
내 프로그램에서는 그렇게까지는 안 하는 대신, 비록 블록처럼 보이더라도 진짜 블록이 잡힌 것처럼 복사/잘라내기 버튼이 켜지지도 않게 프로그램의 동작을 깨알같이 개선했다. 그건 블록이 아니라 조합을 표시하는 용도일 뿐이기 때문이다..
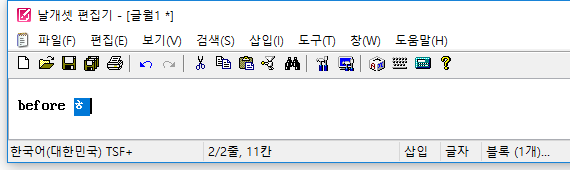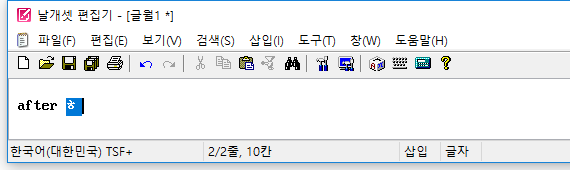
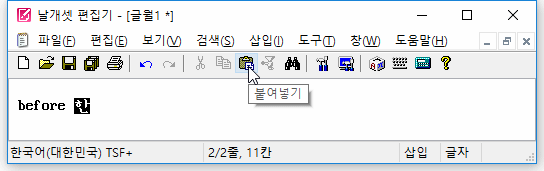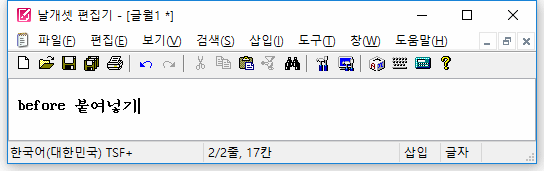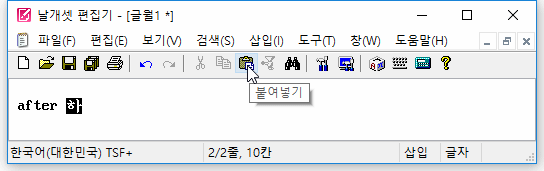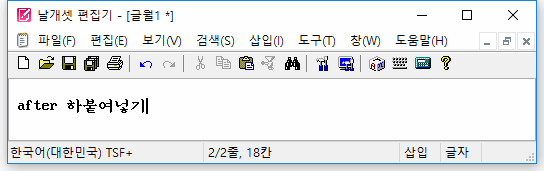
(2) 붙여넣기를 할 때 외부 모듈의 조합이 덧나지 않게
또한, 자체 입력기가 아닌 외부 IME로 한글을 조합하고 있던 중에 도구모음줄의 '붙여넣기' 버튼을 마우스로 누르면..
자체 입력기를 사용할 때와 마찬가지로 조합이 종료된 뒤에 클립보드 내용이 삽입되는게 정상이다.
하지만 지금까지는 그렇지 않았다. 조합이 중단되고 그 문자열이 사라지고서 클립보드 내용이 삽입되었다. 이 버그를 발견하여 고쳤다.
이 두 가지 사항은 언제쯤 다음 버전에 반영되어 나올지 모르겠다.
2. 내 프로그램과 무관한 운영체제의 버그
(1) IME 도구모음줄이 두 종류 모두 표시됨
Windows 10 1803 버전 기준으로..
IME의 구형 재래식 도구모음줄과 Windows 8 스타일의 간소화 도구모음줄이 다같이 동시에 뜨는 경우가 있다. 정확한 재연 조건은 잘 모르겠지만 컴퓨터를 절전 상태로 껐다가 다시 켰을 때 가끔, 그러나 확실하게 이런 현상이 발생한다.

"고급 키보드 설정"에서 "사용 가능한 경우 바탕 화면 입력 도구 모음 사용" 옵션을 건드려 주면 다시 둘 중 하나만 나타나게 개선되긴 한다. 하지만 이건 운영체제의 버그이니 나중에 업데이트를 통해 해결되어야 할 것이다. Windows 8은 물론이고 10도 초창기에는 이런 현상이 발생한 적이 없었다.
(2) 일본어 IME의 조합 관리 버그
날개셋 편집기 또는 IE/Edge 브라우저의 텍스트 입력 폼에서 Microsoft 일본어 IME를 구동하고, 히라가나 모드에서 일본어를 몇 자 입력한다.
space를 눌러서 그 일본어 문자를 변환은 하지 말고, 좌우 화살표 키를 눌러서 조합 영역을 빠져나간다. 그러면 조합을 나타내는 밑줄이 일시적으로 사라진다.
그 뒤에 caret이 기존 조합 영역으로 돌아오면 기존 조합이 다시 생겨야 되는데 그리 되지 않는다.
그 상태에서 다른 곳에서 Shift+화살표를 눌러서 블록을 만들어 보면 아까 조합하던 일본어 문자가 덧나서 잘못 삽입된다.
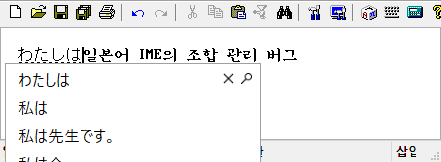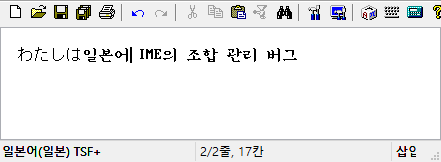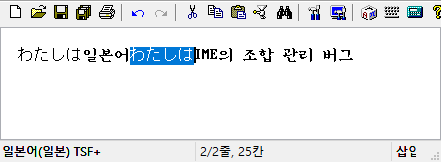
이 버그는 Windows 10의 16xx대 이전 버전에서는 발생하지 않다가 후대 버전에서 나타났다. 1803의 후대 버전에서는 어찌 되었나 모르겠다. 날개셋 편집기뿐만 아니라 MS에서 만든 TSF A급 웹브라우저에서 모두 동일하게 발생하니 내 프로그램만의 문제도 아니다.
단, 워드패드에서는 동일 운영체제와 동일 IME에서 저런 오동작이 발생하지 않는다. 서식을 지원하기도 하니 에디팅 엔진 차원에서 무슨 차이가 있어서 그런 것 같다.
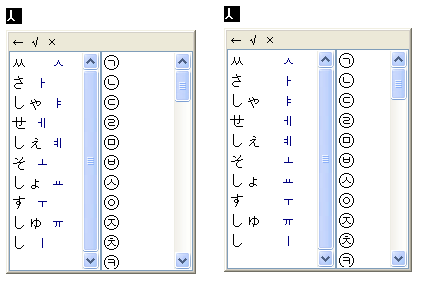
(3) 옛한글 IME의 조합 영역 처리 버그
이건 Windows 8 이래로 계속 동일한 것 같은데..
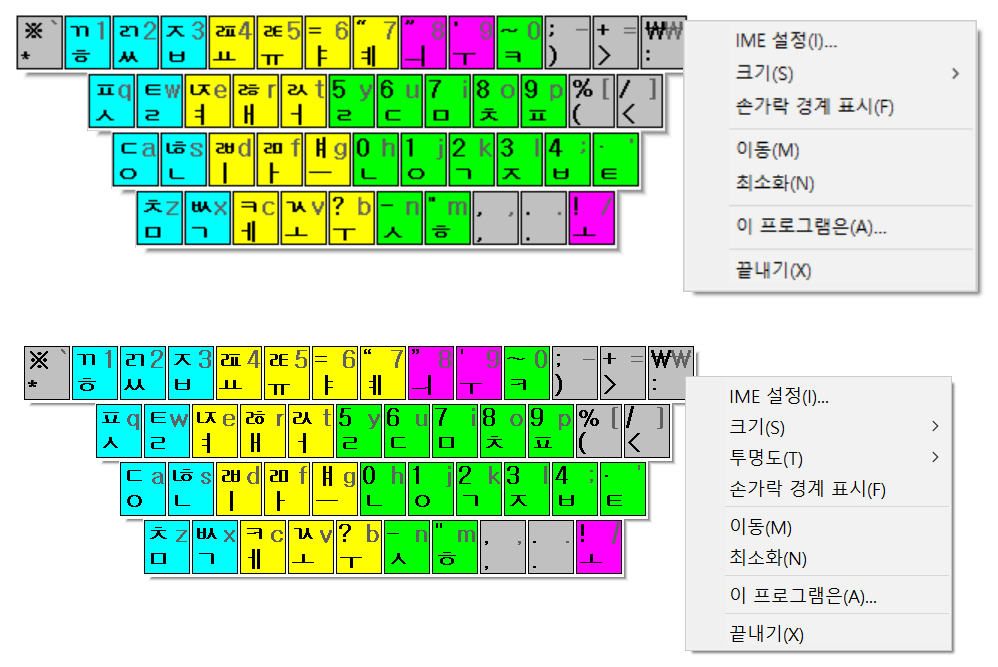
마소에서 제공하는 옛한글 입력기는 초성이나 중성에 옛한글이 들어간 상태에서 종성의 첫 타를 입력하면.. caret 위치가 좀 이상하게 찍힌다. 내부적으로 표현되는 글자 수가 3자가 되었으니 0~3까지 모두 조합 영역으로 설정해야 하는데 종성이 입력되기 전처럼 0~2까지만 설정한다.
그래서 날개셋 편집기에서는 화면이 일시적으로 이렇게 표시된다. 종성 둘째 타 이후부터는 다시 괜찮아진다.
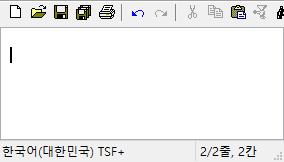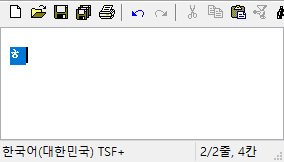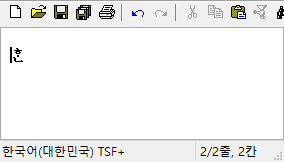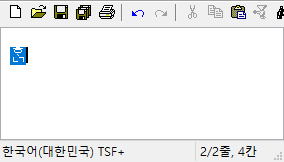
시각적으로 좀 이상한 것 말고 다른 오동작은 없다. 하지만 날개셋, 한컴 입력기 등 옛한글 입력을 지원하는 다른 모든 IME에는 이런 현상이 없고 MS IME만 저러니.. 이건 저 프로그램만이 단독으로 해결해야 할 문제로 보인다.
3. 단순 차이점 -- 옛한글 filler 글쇠
두벌식 옛한글 글자판에는 중성이 빠진 미완성 한글 내지 종성 단독 낱자를 입력하기 위해서 일명 filler라는 글쇠가 있다. 위치는 관례적으로 Shift+J로, 날개셋, 아래아한글, MS 옛한글 입력기가 모두 동일하다.
날개셋과 아래아한글에서는 이 filler라는 게 언제나 '중성 filler'를 의미한다. 이것만 있어도 초성이나 종성이 없는 글자는 입력 가능하기 때문이다.
하지만 MS의 경우, filler도 뭔가 두벌식스럽게 글자를 완전 처음 입력할 때는 빈 자리에다가 '초성 filler'를 흉내 내어 주는 것 같다. 굳이 그럴 필요가 없지만 말이다.
그래서 초기 상태에서 종성을 단독으로 입력하려면 filler를 한 번이 아닌 두 번 눌러야 한다. 본인은 처음엔 이런 차이를 몰라서 마소 옛한글 입력기로는 종성 단독 입력이 불가능한 줄 알았다.
초성 filler도 지원해 주는 게 사람에 따라서는 더 직관적으로 보일 수도 있다. 하지만 한글을 연속으로 입력하기 시작하면 filler는 어차피 사실상 중성으로만 동작해야 하기 때문에 굳이 저럴 예외를 둘 필요가 있나 싶다.
중요한 건 이런 동작조차도 표준으로 딱 정해진 게 없어서 프로그램마다 차이가 있을 수 있다는 점이다. 날개셋에서는 글쇠배열의 수식을 바꿔 주면 지금 동작(중성 고정)뿐만 아니라 MS IME의 동작도 물론 구현할 수 있다.
4. 원인을 알 수 없는 문제
다음은 본인의 개발 환경에서 아주 드물게 발생하는 것을 확인하긴 했지만 재연 조건을 전혀 몰라서 좀 난감한 지경에 있는 버그 아이템들이다. 이것들이 문제의 원인이 전적으로 내 프로그램의 귀책사유로 판명되어 해결된다면.. 위의 1번의 개선 사항까지 포함해서 다음 버전인 9.71이 지금이라도 당장 나오게 된다.
(1) 여전히 발생하는 랙
이번 9.7에서는 안 그래도 편집기의 에디팅 엔진과 관련된 몇몇 버그들이 잡히고 내부 동작 방식이 최적화 됐다. 그런데 편집기를 한번 띄워 놓고 며칠 이상 오래--특히 중간에 컴의 절전 모드와 복귀를 수차례 반복할 정도로-- 쓰다 보면, 어느 샌가 글자가 화면에 나타나는 속도가 내 타자 속도를 못 따라갈 정도로 랙이 걸리는 경우가 여전히 발생한다.
게다가 이게 참 악랄한 게.. 랙의 발생하던 당시에 발생 조건이 다음과 같이 가변적이었다는 것이다.
- 오로지 날개셋 외부 모듈로 한글을 입력할 때만 느려짐 (MS IME, 자체 입력기 등등은 괜찮음)
- 외부 모듈로 한글을 입력할 때만 느려짐 (날개셋, MS IME에서 랙. 자체 입력기는 괜찮음)
- 아무 방식으로나 글자를 입력할 때 몽땅 느려짐
마지막으로 이 문제가 발생했을 때엔.. 처음엔 외부 모듈에서만 발생하는 것 같더니 이내 상황이 최악으로 바뀌었다.
특정 문서의 맨 마지막 줄에서 글자를 입력할 때만 극심한 랙이 걸리고, 그렇지 않을 때는 괜찮았다(타 문서 or 다른 줄). 심지어 그 문서에서 편집하고 있던 텍스트를 몽땅 지우고 새로 입력을 시작해도 랙이 사라지지 않았다.
이 랙이 발생하는 동안 내 프로그램의 내부에서는 무슨 일이 벌어지고 있고 도대체 어느 계층에서 뺑뺑이를 도는 건지 도무지 알 길이 없다. 그냥 평범하게 프로그램을 띄워서는 절대로 발생하지 않는다. 그나마 유력한 단서가 될 만한 현상은.. 이때 날개셋 편집기가 다음과 같이 memory leak이 발생해 있었다는 것이다.
(2) MS IME를 사용할 때 발생하는 괴이한 memory leak
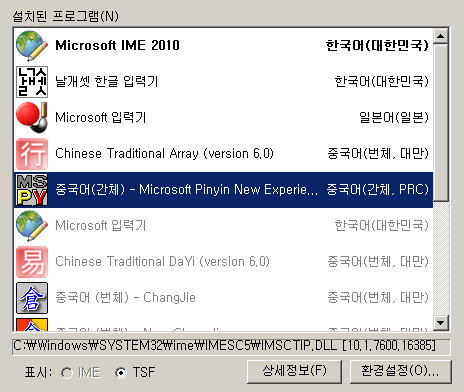
날개셋 편집기와 작업 관리자를 같이 실행한다. 다음으로, 편집기에서 TSF 지원 옵션을 켠 상태에서 '빈 입력 스키마'를 고른다.
Microsoft 기본 한글 IME로, "세벌식 390/최종"(두벌식 말고)으로 "ㅇ.ㅇ.ㅇ.ㅇ." 처럼.. 한글 + 비한글 문자를 수십 회 쭈룩쭈룩 교대로 입력해 보라.
그러면 초기에 2~3MB대 안팎이던 프로세스 메모리 사용량이 계속해서 증가하는 게 관찰된다. 명백하게 memory leak이다.
COM 오브젝트 간의 reference count 같은 게 꼬인 것 같은데.. 이건 도대체 누구 잘못이라고 봐야 할까?
당연히, 디버그 빌드에서 단순 memory leak detector로는 문제가 전혀 감지되지 않는다. 내 프로그램은 10수 년에 달하는 짬밥을 자랑하며 얼마나 오랫동안 안정화가 돼 왔는데.. 소스 코드 상으로 무식한 결함이 있지는 않다.
더구나 날개셋, 한컴 입력기 등 "타 IME에서는 이런 현상이 없다." MS IME도 세벌식을 쓰고 있을 때만 저렇고 두벌식일 때는 문제 없다.
그리고 Windows Vista, 7, 10에서 이 현상을 확인했다. 구닥다리 XP에서는 MS IME+세벌식에서도 문제가 없다.
그럼 내 과실 0, 마소 과실 100을 입증하려면 날개셋 편집기 말고 다른 프로그램에서도 MS IME + 세벌식으로 저렇게 쳤을 때 동일한 memory leak이 발생한다는 걸 입증해야 하는데 그건 또 그렇지 않아 보인다~! 워드패드, MS Word, IE, Edge 등 TSF를 지원하는 프로그램들은 또 희한하게도 저런 현상이 발생하지 않는다.
다음으로 지푸라기를 잡는 심정으로 날개셋 구버전까지도 구해서 써 봤다.
날개셋 8.0까지는 이 문제가 없고, 8.4부터 leak이 발생하더라. 8.2는 불명.. 그러니 이 버그는 대략 2016년부터 있어 왔다는 것이다.
이때 도대체 어떤 변화가 있었는지.. 본인은 프로그램 소스를 자주 백업하는 편이지만, 컴퓨터가 바뀌는 과정에서 지금으로부터 3년이 넘게 너무 오래된 소스는 갖고 있지 않아서 이 방법으로도 문제의 원인을 파악할 수 없었다. ㅠㅠ
난 Windows용 IME라는 물건을 개발하느라 지난 10여 년 동안 온갖 희한한 버그 신고들을 받고 기상천외한 지저분한 환경에서 디버깅을 했다. 그러면서 마치 교통사고 과실 비율 따지는 것 같은 현상들을 많이 경험했었다.
둘 다 스펙대로 100% 무결하게 구현된 건 아니었고(혹은 스펙 자체가 모호해서..) 둘 다 조금만 조심하면 됐는데 둘 다 무데뽀로 동작해서 운 나쁘게 문제가 발생하는 것.. 말이다. Windows용 IME라는 바닥은 무척 "구리다."
아무튼 현재로서는 저 memory leak의 원인과 해결 방법이 오리무중이다. 해결만 된다면 9.7 다음으로 9.71이 당장 나와야 할 것이다.
(3) 제어판 닫았을 때 프로그램 뻗나?
정말 민망하고 황당한 버그인데.. 올해 들어 두세 번인가 겪었다.
날개셋 편집기에서 제어판을 꺼내서 설정을 바꾼 뒤, 확인을 눌러서 닫았더니 편집기 프로그램이 그냥 대짜로 뻗어 버렸다.
한 번 발생했을 때는 그냥 재수없는 우연인가 싶었는데, 몇 주 전에 마지막으로 동일 문제를 겪었을 때는 '미저장 확인'을 누른 것만으로도 뻗었다.
물론 그 뒤로는 편집기에서 날개셋 외부 모듈을 또 얹고, 제어판에서 온갖 설정을 바꾸고 빠른설정을 띄우면서 지지고 볶아 봐도.. 동일 문제가 다시는 재발하지 않고 있다. 위의 랙도 몹시 드물게 발생하지만 이 crash는 그것보다 더 드물게 발생했다. 그래서 난감하다.
Posted by 사무엘