날개셋 한글 입력기 8.8이 나온 지도 두 달 남짓한 시간 만에.. 새 버전을 공개하게 되었다.
원래 내 계획은 새 기능 추가에만 계속 전념하다가 올해 6월 말쯤에 깔끔하게 9.0을 공개하는 것이었다. 그러나 지금까지 발견되고 수정된 버그들만 해도 꽤 중요하고 만만찮은 것들이 잔뜩 쌓이면서.. 결국 원래 구현하려던 주요 기능 하나만 작업을 마친 뒤에 8.9를 한번 더 거쳐 가기로 결정을 내렸다. 그 긴 시간 동안 심혈을 기울여 완성했던 8.8마저도 완벽한 물건이 아니었다.
원래 이 글도 새 버전 소개가 아니라 그냥 다음 버전 개발 근황 정도를 소개하는 글이 됐을 예정었으나, 글의 성격이 바뀌었다. 분량이 매우 긴 관계로, 이번 상편에서는 버그 수정과 작은 기능 얘기부터 먼저 하고, 중요한 기능 추가분은 다음 시간에 소개하겠다.
1. 오랜 버그: 스크롤 막대 딜레마 문제
이번 새 버전에서는 <날개셋> 한글 입력기의 전용 에디트 컨트롤에 존재하던 "아주 오랜 지병"이 하나 극적으로 치료되었다. 그 지병은 바로 스크롤 막대와 관계가 있다.
이건 편집기에 '자동 줄바꿈'이라는 기본 옵션이 제공된 이래로.. 3도 아닌 자그마치 2.x 시절부터 지금까지 근 15년 가까이 전혀 고쳐지지 않고 고스란히 남아 있던 문제였다. 가끔 이런 문제가 발생한다는 것이 경험적으로 알려져 있긴 했지만 그 빈도가 매우 낮으며 정확한 재연 조건을 알 수 없었다.
가끔 재연되는 케이스를 발견했을 때에도 스크롤 막대 관련 코드를 대충 건드려 보는 것만으로는 원인과 해결책을 알 수 없었다. 그래서 더 추가적인 작업 없이 프로그램은 이런 버그가 잔류한 채로 2.x에서 무려 9 직전까지 버전이 올랐다.
문제가 뭐냐 하면, "자동 줄바꿈 + 스크롤 막대"를 켜 놓고 새 문서를 텅 빈 상태에서 차근차근 작성해 보면 된다. 문서가 차지하는 영역이 가로와 세로로 적당히 한 화면의 크기를 초과할 즈음이 되면 스크롤 막대가 생긴다.
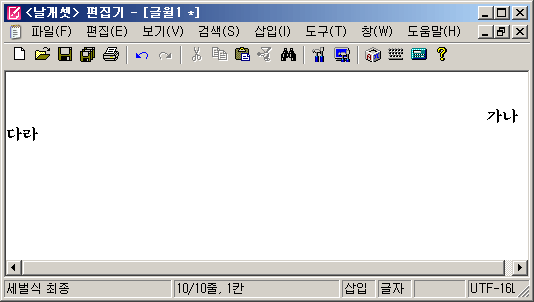
위의 그림처럼 '가나 다라'를 중간의 공백이 줄 사이에 걸치게 입력한다. 그러면 공백 때문에 가로 스크롤 막대가 생기는데, 그 상태에서 엔터를 계속 눌러서 줄 수가 늘어나서 세로 스크롤 막대가 생기게 해 볼 것. 그러면 뜻밖에도 편집창 화면의 테두리가 갑자기 저렇게 깨진다. 기술 용어를 동원하자면, non-client 영역의 표시가 맛이 간다.
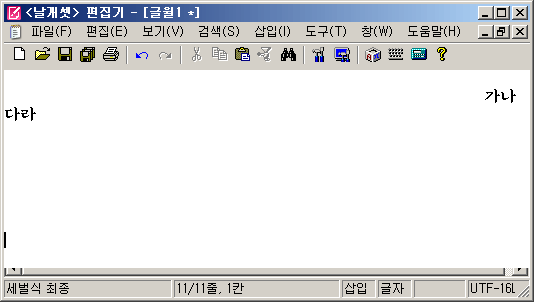
이 현상은 계속 엔터를 눌러서 줄수가 늘어나면 없어지긴 한다. 하지만 도대체 저 현상이 왜 발생하는지 근본적인 원인을 알 길이 없었다. 한때는 참 당돌하게도 이건 가로· 세로 스크롤 막대 설정이 미묘하게 꼬였을 때 발생하는 운영체제의 버그이려니 하고 안일하게 생각하고 넘기기도 했다. NT 계열이 아닌 Windows 9x에서는 이때 프로그램이 아예 통째로 뻗기까지 했는데도 말이다.
이 문제의 원인은 내가 '스크롤 막대 딜레마'라고 이름을 붙인 아주 기묘한 현상 때문이었다.
처음에는 가로 스크롤 막대만 있는데, 줄 수도 늘어서 세로 스크롤 막대가 추가되었다. 그러면 세로 스크롤 막대가 차지하는 공간 때문에 편집창도 폭이(클라이언트 영역의 가로 크기) 감소한다. 자동 줄바꿈 옵션이 켜져 있다면 새로운 폭을 기준으로 텍스트의 문단 정렬이 다시 행해진다.
이제 스크롤 막대가 가로와 세로에 모두 생겼다. 그런데 편집창의 폭이 감소하면서 지금까지 가로로 한 칸 툭 튀어나오던 공백이 다음 줄로 완전히 이동했다. 가로 스크롤 막대가 필요 없어진 것이다. 그래서 최종적으로는 세로 막대만 남는 것 같은데...
이것도 끝이 아니다. 가로 스크롤 막대가 없어지니까 편집창의 높이가 증가했다. 그 결과 텍스트의 모든 줄이 한 화면에 표시가 가능해지고 세로 스크롤 막대조차 필요 없어진다. 그러니 모든 상황은 스크롤 막대가 전혀 없던 원점으로 돌아오는데...
세로 스크롤 막대가 없어지고 편집창의 폭이 원래대로 돌아오자 아까처럼 공백이 다시 줄 경계에 걸려서 가로 스크롤 막대가 필요해지는 상황으로 되돌아온다.
이솝 우화로 치면 당나귀에다 아들(가로 스크롤)만 태워도, 아버지(세로 스크롤)만 태워도, 둘 다 태워도, 둘 다 걷게 해도 어떻게 해도 사람들이 욕을 하는 것과 같은 상황이 되는 것이다.
WM_SIZE 메시지를 처리하는 과정에서 스크롤 막대의 상태가 바뀌고, 그게 또 WM_SIZE를 중첩 생성한다. 이건 이론적으로는 무한 루프에 빠지지만 실제로는 함수의 호출 깊이가 한없이 증가하기 때문에 스택 overflow로 이어진다. 다만, 대놓고 내가 짠 함수로만 스택이 깊어지는 게 아니라 message loop이 중첩해서 쌓이기 때문에 상황을 곧장 파악하지 못했을 뿐이었다.
이 문제를 해소하기 위해 WM_SIZE 메시지와 스크롤 막대 처리 함수가 일정 깊이 이상으로 종료 없이 중첩 호출되는 것을 감지하는 코드를 추가했다. 이런 꼬인 상황에서는 양방향 스크롤 막대를 깔끔하게 모두 제거시켰다. 이로써 문제를 해결했다.
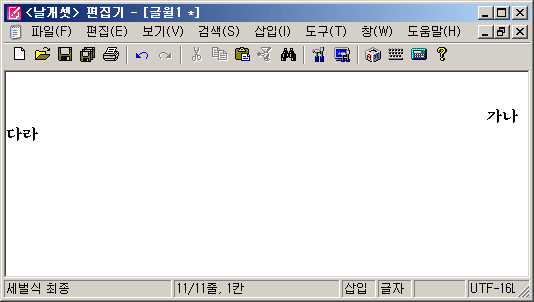
2.x 때부터 있었던 지병이 9.0을 바라보는 타이밍에서야 고쳐졌다는 게 참 감개무량하다. 이건 버그가 아니라 지병에다 비유하고 싶었다. 또는 몇십 년 전에 전사한 무명용사의 유해를 이제야 DNA 감식을 통해 다시 찾아내고 신원까지 파악한 듯한 느낌에다가도 비유할 수 있겠다.
15년 전부터 존재하던 버그가 뒤늦게 고쳐지기도 하니 이 쾌감에 내가 코딩 중독에서 빠져나올 수가 없는 거다. 이걸 고칠 생각을 하게 된 건 우연한 계기 때문이었다. 지난 8.8에서 해치운 작업들을 다 삭제하고 to do list를 정리하고 있었는데, 하필 이 문서가 스크롤 막대 딜레마 오류를 일으키고 있었기 때문이다.
세월이 흐르면서 본인의 절대적인 프로그래밍 실력...이라기보다는 일단 품질을 보는 눈이 예전보다 높아졌다. 예전에는 대충 적당히 만들었던 것을 지금 꼼꼼하게 다시 개량하는 게 개발 트렌드가 됐다. 과거의 철도가 자갈 노반 나무 침목 단선 비전철이라면 지금은 콘크리트 노반과 침목에 복선 전철이 기본인 것처럼 말이다.
2. 조금 거시기한 버그: 타자연습에서 또 외부 모듈을 사용할 때의 충돌
이건 입력기 엔진의 직접적인 문제는 아닌데..
<날개셋> 타자연습에서 외부 모듈(IME)를 또 구동할 때 외부 모듈에서 플러그 인의 기능들을 사용하지 못하는 충돌 문제가 꽤 오래 전부터 있었다. 그걸 사용자의 버그 신고 덕분에야 인지하여 문제를 해결했다.
사실, 외부 모듈이 이미 <날개셋> 한글 입력기를 사용하고 있는 편집기나 타자연습 같은 프로그램(호스트)의 밑에서 돌아가는 상황에 대한 대비 자체는 오래 전부터 돼 있었다. 호스트가 자신과 바이너리 호환이 되지 않는 날개셋 엔진을 사용할 경우, 외부 모듈은 자기에게 맞는 엔진을 따로 로딩하게 했으며, 한 프로세스에 디렉터리 위치만 다른 ngs3.dll이 동작하더라도 문제가 없게 조치를 취했다.
저것 자체는 늦어도 지난 2010년대 초에 이미 다 이뤄진 일이다. 하지만 이번 문제는 그것과는 별개인 또 다른 문제였다. 동일한 ngs3.dll이 두 번 로딩되었는데 플러그 인은 한 군데밖에 없다 보니 한 프로그램에서는 내부 구조의 문제로 인해 플러그 인을 사용할 수 없었다.
이런 문제가 존재할 거라고 전혀 생각을 못 하고 있었는데 결국은 ngs3.dll을 불러들이는 방식을 변경해서 불가피한 경우가 아니면 중복 로딩이 되지 않게 했다.
3. 그럭저럭 내력이 있는 버그: 부팅 전후 외부 모듈의 crash 문제
8.8을 공개한 뒤에 의외로 외부 모듈의 안정성과 관련된 결함이 몇 군데 발견되어 해결되었다. <날개셋> 한글 입력기를 운영체제의 기본 IME로 지정한 뒤 Windows 7 기준으로,
(1) 처음 부팅을 하면 explorer 프로세스에서 오류가 발생할 수 있다.
(2) 시스템을 로그아웃/종료할 때 taskhost 프로세스에서 오류가 남.
(1)의 경우 일반적인 상황에서는 발생하지 않고 날개셋 커널이 로딩되지 못해서 외부 모듈도 아무런 제공 기능 없이 시체 상태로 동작할 때에만 그런다. IME라는 게 live 업데이트가 쉽지 않은 프로그램이다 보니, 설치 후에 재부팅을 제대로 하지 않고 뭐가 꼬이면 커널과 외부 모듈의 버전이 서로 안 맞아서 아주 드물게 저런 상황이 발생할 수 있는 듯하다.
이유야 어쨌든 날개셋 외부 모듈은 시체 상태이더라도 최소한 프로그램을 뻗게 하지는 않아야 하므로, 이는 의도하지 않은 버그이긴 하다.
그리고 (2)는 지난 8.5 버전에서 각종 이벤트 통지 기능이 추가되면서(프로그램 활성화, 글자판 전환 등) 민감한 곳을 건드리다가 생긴 버그이다. 저렇게 짜도 다른 프로그램들은 아무 문제 없는데 유독 저 프로세스만 탈을 일으켰다.
지금까지 잘만 돌아가다가 왜 그 상황에서 있어야 할 오브젝트가 온데간데없이 사라졌고 NULL인지는 정말 '귀신이 곡할' 노릇이고 도무지 알 수 없다. 그냥 결과론적인 안전 점검 루틴을 추가하는 것밖에 대처 방법이 없었다.
게다가 평범하게 문제가 발생하는 게 아니라 로그아웃/시스템 종료를 하는 순간에만 잠깐 발생하고, 그때는 종료를 취소하고 디버거를 띄울 수도 없었기 때문에 더욱 난감했다. 그래도 다행히 그때 예외 처리기 분기와 덤프 파일 생성이 됐기 때문에 이 정보와 pdb 파일을 토대로 당시 스택 프레임을 재구성하고 문제 발생 지점을 찾아낼 수 있었다.
(1)과 (2) 모두 문제가 발생한 곳은 의외로 구닥다리 레거시 imm32 프로토콜 기반의 IME 계층 쪽이었다. TSF 쪽이 아님.
4. 직전 버그: 외부 모듈에서 초성 조합 중에 특수문자 변환이 되지 않는 문제
이번엔 고질병과는 반대로 직전의 8.8 버전에만 존재하는 버그 얘기이다.
개발 연혁이 15년이 훌쩍 넘어가는 프로그램에서 더는 이런 어처구니없는 실수가 없어야 정상이겠지만 안타깝게도 그런 예가 하나 발견되어 이 자리를 통해 알리도록 하겠다.
8.8 버전은 외부 모듈에서 ㄱ~ㅎ 같은 자음을 조합하고 있는 상태에서 후보 변환(한자 같은)을 눌러 특수문자를 입력하는 기능이 제대로 동작하지 않는다.
더 구체적인 문제 발생 조건은, 자음을 호환용 한글 낱자로 바꿨을 때(외부 모듈 환경 또는 최종 변환 규칙을 통해서)이다. 그렇기 때문에 편집기에서 최종 변환 규칙 없이 그냥 자음을 단독으로 입력하고 있을 때는 문제가 없다.
이것은 8.8에서 새로 추가된 '앞에서 뒤로 탐색하여 단어 단위 한자 변환' 기능으로 인해 발생한 부작용이다.
새 기능인 '앞에서 뒤로 탐색'(즉, '토선생'을 변환하면 '선생'이 아니라 '토선'이 먼저 제안되는 것)을 선택했을 때는 그런 부작용이 없고, 예전부터 지원되던 동작인 '뒤에서 앞으로 탐색' 또는 단어 단위 한자 변환을 사용하지 않으면 저렇게 초성+한자 특수문자가 동작하지 않게 된다.
메모장은 TSF 확장 옵션을 사용하지 않으면 어차피 단어 단위 한자 변환이 동작하지 않는 환경인데도 저런 옵션의 영향을 받는다.
사소한 버그이기 때문에 다음 버전에서는 문제가 곧장 고쳐졌다.
5. 기능 추가: 외부 모듈에 키보드 드라이버 배열 미리보기
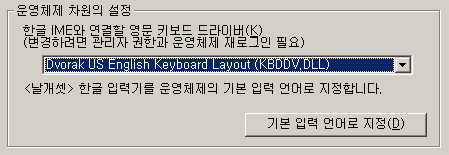
외부 모듈의 '시스템 - 고급 시스템 옵션' 제어판 페이지에는 지난 8.6때부터 "한글 IME와 연결할 영문 키보드 드라이버" 지정 기능이 추가되었는데, 사용자가 선택한 키보드 드라이버의 글쇠배열을 간단하게 미리 들여다보는 기능이 추가되었다.
<날개셋> 한글 입력기에 키보드 드라이버를 바로 불러오는 기능은 무려 10년 전 4.4 버전부터 존재했다. 그러니 그 기능을 여기에다 연계하지 못할 이유가 없다.
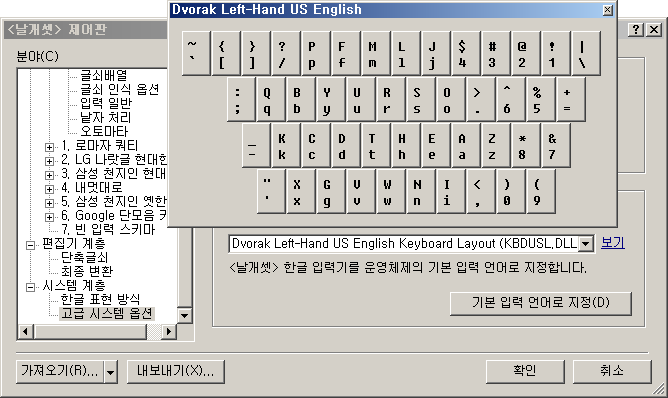
'보기' 링크를 누르면 글쇠배열 그림이 별도의 modal 대화상자의 형태로 뜬다.
좀 더 욕심을 내자면, 옛날에 MS Excel에서 차트 미리보기 기능처럼 뭔가를 누르고 있는 동안만 preview가 뜨고, 버튼에서 손을 떼는 순간 그림이 사라지는 게 내 본래 의도이다.
하지만 그런 기능이 운영체제의 표준 GUI에는 존재하지 않고, 또 키보드 드라이버 변경 기능이 한글 입력과 직접적인 관계가 있으면서 많이 쓰이는 기능은 아니라고 생각되어 그냥 이 정도 기능만 넣는 것으로 그쳤다.
6. 그 밖에
(1) 외부 모듈과 변환기에는 유니코드 5.2 옛한글을 호환성 차원에서 1.1 과거 방식으로 풀어서 표시하는 옵션 내지 기능이 있는데.. 8.8 버전에서는 이 부분의 코드가 리팩터링 되던 과정에서 더 풀어서 표시해야 하는 낱자를 풀지 않고 잘못 표시하는 문제가 들어갔음을 뒤늦게 발견했다.
가령 ㅗㅒ는 ㅗㅑㅣ로 더 풀어야 하고 중성엔 ㅛㅐ, ㅠㅐ, ㅣㅖ, ㅡㅔ, ㅣㅒ, ㆍㅔ 같은 예가 더 있다.
오늘날이야 유니코드 1.1 옛한글은 한양 PUA보다도 인지도가 없고 거의 쓸 일 없으니 당장 대다수 사용자에게는 별 여파는 없는 문제이긴 한데, 이런 문제 자체가 있다는 건 밝힌다. 이번 새 버전에서 곧장 해결되었다.
(2) Metro 앱에서 시스템 계층의 키보드 드라이버 보정 기능이 동작하지 않던 것을 동작하게 했다. (연결되는 키보드 드라이버 자체를 변경하는 것은 여전히 지원 불가) 그리고 지금까지 Internet Explorer 11 내부의 텍스트 입력란(주소 입력란 말고)에서 외부 모듈의 글자판 동기화가 되지 않고 입력 패드도 동작하지 않던 문제를.. 우연한 계기로 드디어 해결했다.
IE는 IME 개발자의 입장에서 굉장한 요물이고 뭔가 자체적인 샌드박스 같은 환경을 갖춘 것 같았는데 메트로만치는 아니어도 어느 정도 샌드박스가 있긴 했다. 이런 부류의 문제들이 하나하나 해결돼 가는 걸 보는 건 내 인생의 낙이다.
(3) 오랫동안 '외장형 후보' 예제 데이터 파일로는 구결밖에 없었는데, 정 재민 님의 제안으로 대법원 제정 인명용 한자 목록 8000여 자를 추가했다. 제1후보를 대체하는 물건으로 활용 가능하다.
이게 의외로 종이 문서나 이미지로만 존재하거나, 글자별 조회만 가능하지 전체 목록을 뽑기가 쉽지 않았는데 일일이 목록을 만든 분이 국내도 아니고 일본에 있었다. (☞ 출처) 참고로 인명용 한자는 한번 정하고 끝이 아니라 계속 추가되는 편이다.
(4) 타자연습의 게임은.. 아예 운영체제의 표준 GUI만 사용하는 다른 연습 UI보다는 비주얼이 낫겠지만, 그래도 요즘 게임 트렌드에 비해서는 기술적으로 너무 뒤쳐진 구닥다리가 됐고 게임 시스템도 좀 바꿔야 할 때가 됐다.
하지만 전면개편을 하기에 앞서..;; 또 사소한 UI를 좀 고쳤는데,
게임 화면 하단은 시스템의 색상과(특히 고대비 검정 같은) 관계없이 언제나 흰 배경에 검은 글자로 찍히게 했다.
그리고 컴퓨터 속도가 2GHz를 넘어간다 싶으면 "256색 전체 화면" 옵션을 없애고 표시하지 않게 했다.
옛날에 Windows 2000/XP 초창기에는 256색 전체 화면이 트루컬러 전체 화면보다 속도가 더 빠르고 진행이 원활한 경우가 있어서 저 옵션을 넣은 것이었지만, 오늘날이야 당연히...;; 아무 차이가 없어졌기 때문이다.
게임도 창 모드로 실행될 때는 자기 별도의 창을 띄우는 게 아니라 프로그램 main 창 내부에서 돌아가게 하고 싶긴 하다.
추신: 외부 모듈이 IME 목록에 나타나지 않는 이유는?
<날개셋> 한글 입력기를 설치하고 나면 외부 모듈도 일부러 제외하지 않은 한 같이 설치되고 운영체제 IME로서 등록된다.
그런데 <날개셋> 한글 입력기가 한 번도 설치된 적이 없던 완전히 새 컴퓨터에다 프로그램을 처음 설치한 경우, IME 목록에 내 프로그램이 제대로 뜨고 있는지 궁금하다.
IME 목록에 곧장 나타나지 않는 경우도 종종 있어서 말이다. Windows 8/10에서 특히 그러하다. 이 경우, 입력 언어 제어판을 꺼내서 '한국어 - 추가'를 누르면 거기에 <날개셋> 한글 입력기가 숨어 있곤 한다. 이걸 수동으로 꺼내야 사용 가능하다.
이것은 기술적으로는 입력 언어의 enable/disable 상태 차이 때문에 그렇다. 그런데, 새로 등록된 내 IME를 enable시키려면 이러이러한 함수를 호출하면 된다고 MSDN에서 시키는 대로 다 했는데도 일부 컴퓨터에서는 설치 직후에 <날개셋> 한글 입력기가 곧장 나타나지 않는 듯하다.
현재로서는 이유를 알 길이 없다. 그럴 때는 딱히 해결책이 없으며, 사용자가 수동으로 내 입력기를 추가해 주면 된다고 도움말에다 써 놓기만 했을 뿐이다.
(下에서 계속됨)
Posted by 사무엘