날개셋 한글 입력기 9.82가 어제, 9.81 이후 딱 두 달 만에 완성되어 나왔다. 딱히 원조가카의 서거 40주년에 맞춘 것은 아니다. 24일이나 25일에 완성을 못 했기 때문에 26일에 완성하게 됐을 뿐이다.
원래 생각 같아서는 아예 이 달 초 한글날쯤에 공개하고 싶었다. 그러나 답이 없는 지독한 버그(알고 나면 별것 아니지만..)와 컨디션 조절 실패 때문에 일정이 늘어져서 그보다 훨씬 더 늦게 나오게 됐다.
이번 버전은 눈에 띄는 기능 추가가 아니라 개선과 버그 수정 위주이다. 그러니 버전 번호도 0.01만치만 증가했다. 그리고 타자연습은 변화가 없으며, API 호환성도 달라지지 않았다.
그럼에도 불구하고 이번 9.82는 유의미한 변화를 열거하라면 꽤 많다. 특히 외부 모듈 내지 입력 도구 UI와 관련된 것이 많다.
1. 한자 변환 UI 관련
(1) 바로 직전 버전인 9.81부터는 MS Word의 우클릭 메뉴를 통해서 단어 단위로 한자 변환을 할 수 있게 되었다. 그런데 한자를 고르지 않고 ESC를 눌렀을 때 블록으로 잡힌 단어가 사라지는 문제를 비롯해 몇몇 사소한 glitch들이 있던 것을 바로잡았다. 오랫동안 본인의 심기를 건드려 온 찝찝한 문제였는데 드디어 해결되어 기쁘다.
또한, 단어의 앞부분 일부만 한자로 바꾼 뒤에 cursor가 다시 원래 있던 뒷부분으로 되돌아오는 것도 날개셋 편집기 내지 MS IME와 동일하게 처리되게 했다.
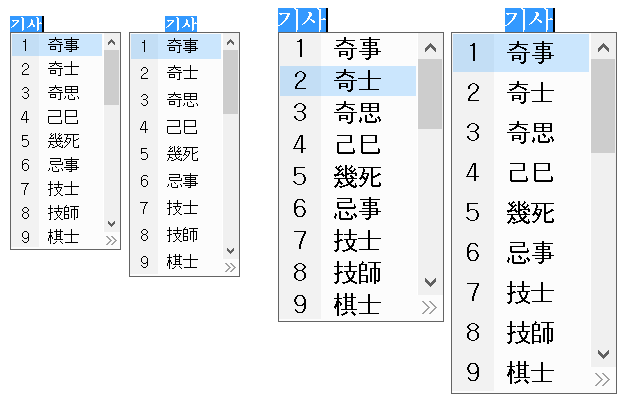
(2) 한자 변환 UI의 선택막대를 더 큼직하게 키웠다. 특히 간격이 하드코딩된 픽셀수로 지정되어 있어서 화면 DPI가 올라갈수록 실질적인 간격이 말도 안 되게 좁아지던 문제를 해결했다. 이제 high DPI 환경에서도 한자 변환 기능을 사용하기가 더 수월할 것이다.
아래 그림은 각각 100%와 150%배율에서 before와 after 모습이다.
(3) 그리고 키 동작 방식을 MS IME의 UI와 더 일치하도록 바꿨다.
가령, space로도 항목을 이동할 수 있으며, 화살표 키로 선택막대가 페이지의 시작이나 끝에 도달한 뒤에는 다시 끝이나 시작 지점으로 순환되게 했다. 또한, page up/down을 눌렀을 때는 선택막대가 해당 페이지의 맨 처음 지점에 가게 했다.
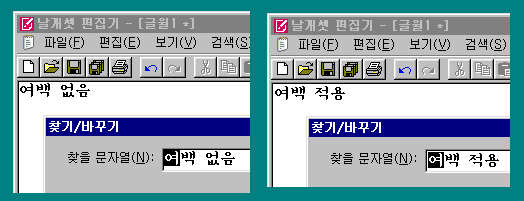
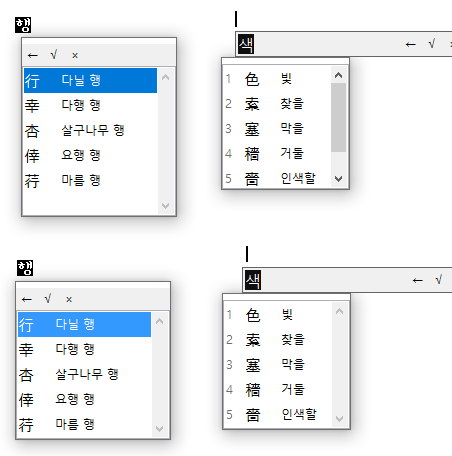
(4) 끝으로, 아까 저 한자 변환 UI 그림에서 '기사'의 위치를 보면 유추할 수 있듯, cursor의 아래에 나타나는 모든 UI들이(입력 도구).. 창 테두리가 아니라 창 내부 글자가 cursor의 바로 아래에 나타나도록 표시 위치를 조정했다. 아래 그림에서 위는 before이고, 아래는 after이다.
또한, 목록에도 불필요하게 여백이나 스크롤 영역이 생기지 않도록 초기의 창의 크기가 더 정확하게 계산되게 했다. 그 차이도 위의 그림에서 이미 묘사되어 있다.
옛날에는 이런 게 왜 눈에 들어오지 않았던가 모르겠다.
2. 엑셀에서 입력 도구의 특이한 오동작
날개셋 한글 입력기가 제공하는 입력 도구 중에는 GUI 요소에 콤보 상자가 들어있는 것이 있다.
'부수로 한자 입력'에서 부수의 획수를 고르는 UI, 그리고 '문자표'의 위쪽에서 글꼴과 문자표 종류를 고르는 UI 말이다.
그런데 MS Excel에서 날개셋 외부 모듈을 구동한 뒤, 여기서 저런 입력 도구의 콤보 상자를 눌러서 열고 나면 몇 초 못 가, 혹은 심지어 마우스 포인터를 살짝 움직이기만 해도 열었던 콤보 목록이 저절로 닫혀 버리곤 한다. 그래서 글꼴이나 획수 같은 걸 제대로 선택할 수 없다.
이건 다른 프로그램들은 괜찮고 오로지 엑셀에서만 발생하는 문제이다. MS Word에 black blank 문제가 있는 것처럼 Excel도 특이한 동작 방식이 존재하는 셈이다.
이것 때문에 본인은 며칠을 끙끙대며 헤맸으며, 그 과정에서 입력 도구 UI 엔진의 여러 미세한 버그들, 불필요한 코드 따위를 제거하는 부수적인 효과를 내긴 했다. 그러나 이 문제는 근본적으로는 엑셀이 굉장히 특이하게 동작하면서 날개셋 한글 입력기의 동작까지도 교란하기 때문에 발생한다.
심지어 마우스 휠을 굴렸을 때의 반응도 다르더라.
요즘 Windows에서는 입력 도구에서 마우스 휠을 굴리면 그게 입력 도구로 가는 반면, 엑셀에서만은 여전히 이전 버전 Windows처럼 휠 이벤트가 엑셀 창으로 간다.
내 추측으로는 쟤들도 마우스 관련 훅킹이라도 해서 마우스 포커스를 가로채는 것 같다.
엑셀에서 콤보 목록이 닫히는 문제는 엑셀의 버전에 따라 양상이 둘로 나뉜다.
첫째, 2007 초창기 버전과 그 이하의 구버전에서는 그냥 콤보 상자를 누르고 가만히만 있어도 몇 초 후에 목록이 닫힌다. 이건 근본적인 해결이 불가능하며, 저 예외적인 상황만 감지해서 어거지로 보정하는 것도 가능하지 않다.
둘째, 2007 SP3쯤과 2010 등 이후 버전에서는 콤보 목록을 연 뒤 마우스 포인터를 살짝 움직이면 목록이 닫힌다. 이건 다행히 내 프로그램에서 동작을 변경함으로써 해결 가능한 것을 확인했으며, 이번 9.82 버전에서 반영됐다. 최신 버전에서 해결 가능한 문제이니 이 문제는 사실상 해결된 것이나 마찬가지이다.
그리고 정사각형 문자표가 있는 입력 도구들(부수, 문자표, 이모지..)을 마우스로 클릭하고 잠시 있으면 확대된 글자를 잘 보라고 마우스 포인터가 사라지는데..
이때도 엑셀에서는 알 수 없는 이유로 인해 포인터가 사라지지 않곤 했다. 사라졌다가도 마우스 포인터를 살짝 움직이면 다시 나타났다.
그 문제를 이번에 덤으로 해결했다. 마우스 포인터를 숨기는 방법을 바꿨다. 이건 콤보 목록이 닫히는 문제와는 별개의 문제였다.
참고로, 당연한 말이지만 외부 모듈이 아니라 입력 패드에서 입력 도구들을 꺼내면 Excel에서도 아무 차이 없이 입력 도구들을 사용할 수 있다. 얘는 아예 별도의 프로세스에서 입력 도구를 구동한 것이기 때문이다.
3. 아래아한글에서의 미세한 문제
아래아한글은 MS Word와 달리 전통적으로 TSF를 지원하지 않는 불모지였다. 그런데 2018을 뒤늦게 써 보니 여기에도 변화가 느껴졌다. 비록 문서 본문은 변함없지만 대화상자의 텍스트 입력란에서는 TSF가 지원되기 시작했기 때문이다. 마소나 날개셋 한글 IME에서 단어 단위로 한자 변환을 할 수 있으며, backspace 달라붙기 같은 기능들이 모두 제대로 동작한다.
2010년대 중반이 되니 유니코드 5.2 방식의 옛한글 글꼴이 운영체제 차원에서 완전히 정착했고, 2010년대 후반이 되니 날개셋 말고도 TSF 기반의 한글 IME가 만들어져 나오고 심지어 TSF를 지원하는 텍스트 에디팅 엔진도 나오는구나 하는 생각이 든다. 뭐, 아래아한글의 경우, 문서 본문에도 TSF를 지원하는 건 여전히 쉽지 않을 것이다.
다만, 이렇게 아래아한글에 TSF 기반 텍스트 입력란이 구현되면서 날개셋 한글 입력기와도 충돌을 일으키기 시작했다. 버그 내지 오동작 의심 증상이 무려 세 가지나 있었는데, 이것 때문에 개인적으로 굉장히 힘든 나날을 보냈다.
- 첫째는 그냥 답이 없는 문제였다. 안 그래도 동작 방식이 A형 B형 둘로 나뉘어 있는데, 아래아한글은 이미 알려진 다른 유형인 B형으로 인위로 보정을 해 줘야 했다.
- 둘째는 프로그램이 뻗을 수도 있는 제일 치명적인 문제인데, 엄~밀히 말하면 내 입력기의 버그가 맞았다. 조합 상태가 아니면 그냥 조합을 완전히 해제해야 하는데 빈 조합으로 남겨 놓고 있었다. 하지만, 그런 결함이 있다고 실제로 이상한 문제를 외형적으로 일으키는 프로그램은 아래아한글이 처음이었다.
- 마지막 셋째는 도대체 왜 내 입력기를 쓸 때만 이상하게 동작하는지 알 길이 없었는데, 알고 보니 일반적인 상황에서는 발생할 일이 없는 문제라는 것을 최종 확인했다. 간단하게만 말하자면 날개셋이 제공하는 한자 변환 기능과, 아래아한글이 자체적으로 제공하는 한자 변환 기능이 충돌하는 문제이다.
세 문제가 원인과 해결책이 전부 저 정도로 제각각으로 달랐다. 그래도 어쨌든 다 해결되니 기쁘다.
4. 크롬과 에지
(1) 마소의 Edge 브라우저가 크로뮴 기반으로 재개발(?)되고 있으며, 현재 베타 버전이 공개돼 있다. 그런데 얘는 크롬과 동일한 엔진(크로뮴) 기반이어서 그런지 예전의 크롬과 동일하게 조합 중인 글자가 덧나는 버그가 있었다. 이에 대한 보정을 추가했다.
(2) 그리고 크롬도 최근에 버전 78로 업데이트가 됐는데.. 생뚱맞게도 자신이 Metro 앱이라고 IME에다가 알려주고 있었다.
Metro 앱 환경에서는 통상적인 데스크톱 GUI가 제공되지 않기 때문에 날개셋 제어판을 꺼낼 수 없다. 그렇기 때문에 이 환경에서는 내 프로그램 역시 제어판을 여는 버튼을 disable시켜 버린다.
그런데 본인이 확인해 본 결과, 크롬과 Edge 베타 모두 말은 그렇게 해도 데스크톱 GUI의 구동에는 문제가 없었다. 그렇기 때문에 이번 버전에서는 저 프로그램에서 제어판이나 각종 대화상자들을 변함없이 열 수 있게 보정을 추가했다.
5. 외부 모듈의 응용 프로그램별 수동 보정 옵션
이 기능은 오래 전부터 날개셋 한글 입력기에 도입할까 말까 망설였는데.. 크롬 버그 이후로 갈수록 증가하는 glitch 신고를 계기로, 더는 대세를 거스를 수 없겠다 싶어서 결국 구현하게 되었다.
무엇인고 하니, 날개셋 한글 입력기가 응용 프로그램마다 호환성 차원에서 일부러 다르게 보정해서 동작하는 세부 알고리즘을 외부에 노출하고, 사용자가 프로그램별로 이를 수동으로 customize 할 수 있게 하는 것이다. 내부에 하드코딩 되어 있던 보정 규칙 테이블이 이 기회에 개방되었다.
Windows용 한글 IME라는 건 단일 로직으로 모든 프로그램에서 정확하게 동작하는 것이 불가능하다는 것이 확실시되고 있다. 크롬 브라우저와 MS Word는 걔네들에게만 적용되는 고유한 보정이 존재하고, 그것 말고도 전반적이 통신 방식이 크게 A와 B라는 두 갈래로 양분되어 있다.
어느 방식으로 통신하나 잘 동작하는 프로그램도 물론 있고 그래야만 정상이지만.. >_< 현실에서는 둘 중 한 방식을 거부하는 프로그램도 있다.
특히.. 지난번 9.8 시절의 크롬 버그를 잡고 그 방법을 다른 프로그램에다가도 범용적으로 적용시켰더니.. 기껏 지금까지 잘 돌아가던 모 프로그램에서 부작용이 발생하더라는 연락을 개인적으로 받기도 해서 멘붕했다.
아, 여기서 버그나 오동작이라는 건 한글 입력 자체가 안 된다기보다는 IME의 문자 입력 이벤트에 응용 프로그램이 반응을 제대로 못 해서 글자가 덧난다거나, 조합 중인 문자열이 사라진다거나 하는 glitch들을 말한다.
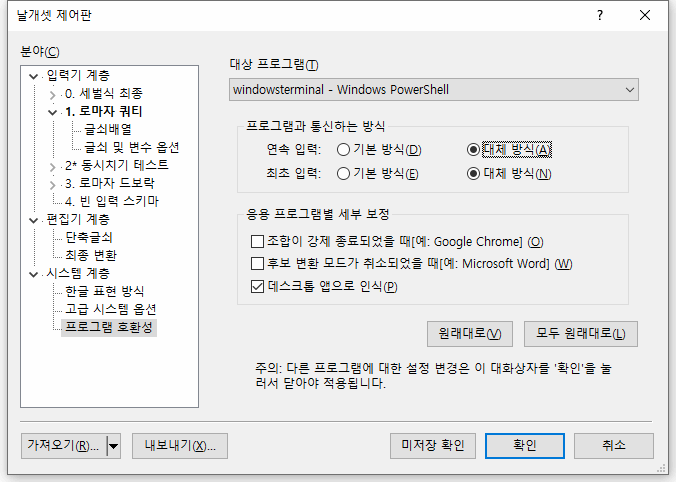
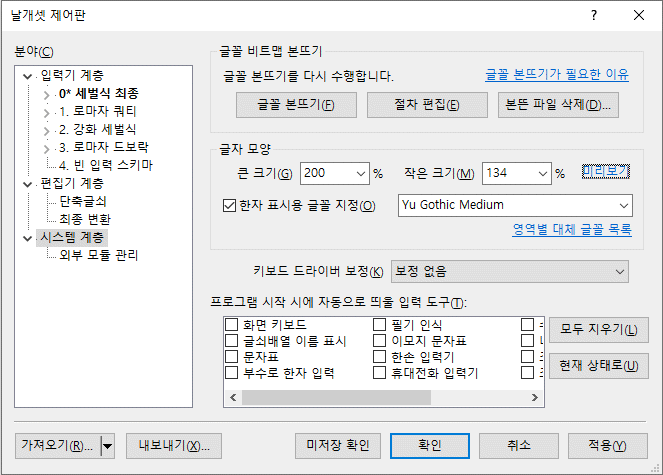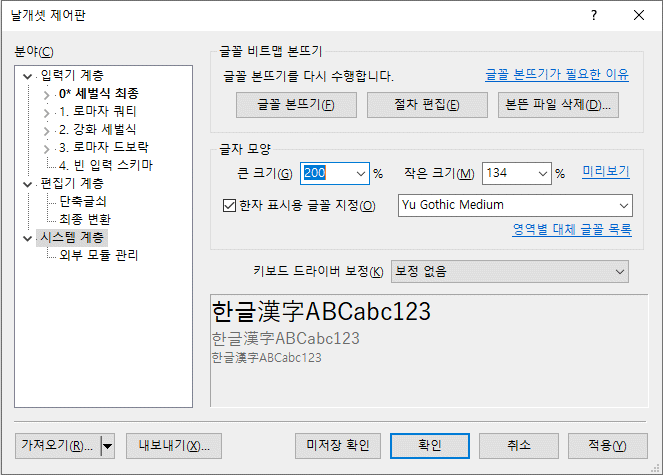
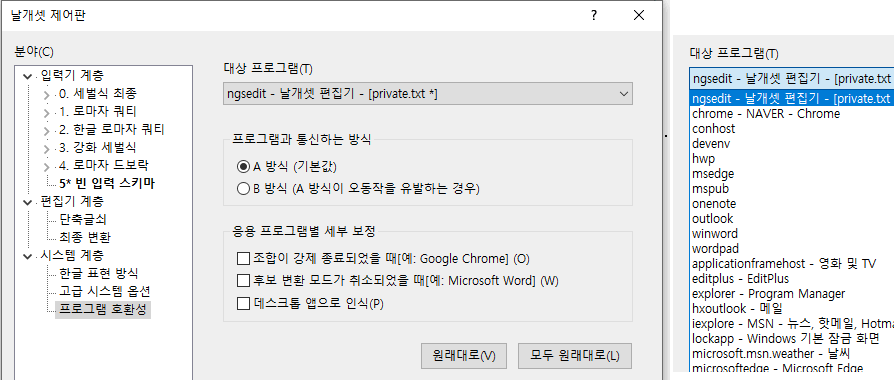
이제 제어판의 '시스템 계층'을 보면 "한글 표현 방식"과 "고급 시스템 옵션"의 아래에 "프로그램 호환성"이라는 카테고리가 하나 더 추가되며, 지금 당장 실행돼 있는 프로그램을 대상으로 통신 방식과 몇몇 보정 방식을 변경할 수 있다.
'대상 프로그램'은 지금 날개셋 IME가 동작하고 있는 프로그램이 가장 먼저 제시된다. 하지만 콤보박스를 열어 보면 현재 실행돼 있는 프로그램 또는, 실행되지 않았더라도 보정 정보가 등록된 프로그램을 고를 수 있다. 프로그램은 그냥 실행 파일 이름으로 식별한다.
앞으로 미묘하게 뭔가 잘 동작하지 않는 프로그램을 발견한 경우, 어지간해서는 '프로그램과 통신하는 방식'을 A에서 B로 바꿔 보시기 바란다. 응용 프로그램별 세부 보정은 해당 프로그램 외에서는 크게 쓸 일이 없을 것이다.
이로써 날개셋 한글 입력기는 글쇠배열은 말할 것도 없고 한글 입력 오토마타, 낱자 입력 규칙, 한영 전환 글쇠를 포함해 옛한글의 표현 방식에다 이런 응용 프로그램별 보정 방식까지도 customize 가능한 흠좀무한 프로그램이 되었다.
6. 나머지, UI 차원에서 사소하게 개선된 것들
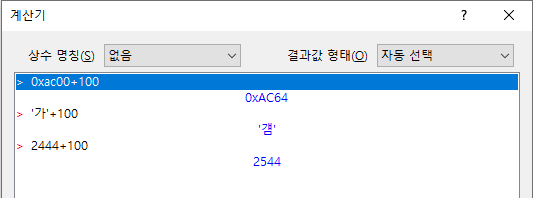
(1) 편집기의 계산기에서 입력된 수식에 오류가 있는 경우, 에러 메시지를 더 구체적으로 표시하게 했다. 그리고 계산 결과를 무조건 10진법, 16진법 또는 상수 명칭 형태로 출력하는 게 아니라, 입력된 상수의 형태를 따라서 유동적으로 출력하는 모드를 추가했다. 100+100은 200이지만 0x100+100은 0x164이고, 'a'+3은 'd'가 되는 식으로 말이다. 이게 기본 상태이다.
사실, 계산기 기능이 아니라 날개셋 제어판 같은 다른 곳에서는 수식을 이렇게 더 자상하게 취급하는 기능이 이미 제공되고 있었는데 계산기로 도입이 다소 늦었다.
그리고 변수에는 언제나 값만 저장되지 대입된 상수의 형태가 저장되지 않는다. 그래서 'a'+1은 'b'라고 출력되지만, A='a'는 출력 방식이 특별히 지정되지 않은 한 그냥 97이라고 출력된다.
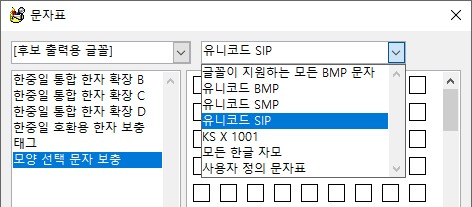
(2) 문자표 도구에서 "글꼴이 지원하는 모든 BMP 문자"를 지정했을 때 바탕, 굴림 같은 글꼴에서 공백(U+20) 미만의 제어 문자들이 앞에 표시되지 않게 했다. 그리고 영역 구분을 A 이상 B '미만'으로 해야 하는데 B '이하'로 하는 바람에 쓸데없이 깨진 문자가 하나씩 포함되던 문제를 이제야 발견해서 뒤늦게 해결했다.
(3) 부수로 한자 입력 도구에서 부수 목록은 화면의 확대 배율과 무관하게 언제나 한 줄에 5개씩 표시되게 했다. 150% 배율에서는 폭 계산이 이상하게 돼서 줄당 4개씩 표시되고 여백이 남아서 보기가 무척 안 좋았는데 이를 개선했다.
(4) 제어판의 '시스템 계층'에서 한자 출력용 글꼴을 수동 지정하는 콤보 상자에는.. 사용자의 선택을 돕기 위해 CJK 언어를 지원하는 글꼴들만 목록에 등록돼 표시된다.
그런데 이 목록에는 몇몇 글꼴이 누락되곤 했다. 가령, 한자 출력용으로 손색이 없는 Noto Sans CJK 같은 글꼴은 설치돼 있어도 표시되지 않았다. 정확한 이유는 알 수 없지만 운영체제가 얘를 평범한 트루타입 글꼴로 분류해서 조회해 주지 않았던 것이다.
이 문제를 해결하여 저런 글꼴도 목록에 등재되도록 했다. 다만, 목록 등재 여부를 떠나서 사용자가 이 글꼴 이름을 딴 데서 복사해서 강제로 지정해 주면 지금도 그 글꼴을 지정 자체는 할 수 있다.
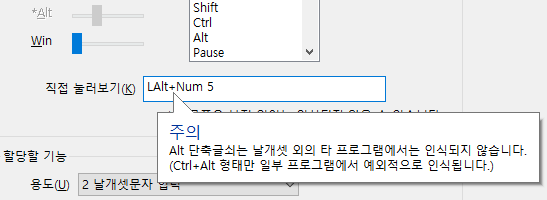
(5) 날개셋 한글 입력기는 각종 단축글쇠에서 shift, ctrl, alt, win의 조합을 modifier로 지원한다. 다만, 편집기와 입력 패드 같은 자체 환경 말고 외부 모듈(IME)에서는 운영체제의 동작 특성의 차이로 인해 alt가 사실상 지원되지 않는다. 그래서 외부 모듈에서 단축글쇠 편집 대화상자를 꺼내면 alt를 조절하는 슬라이더는 disabled 상태로 나타났는데...
이번 버전에서는 그에 덧붙여 사용자가 alt를 할당할 경우 이렇게 풍선 도움말로도 추가적인 안내를 하게 했다.
프로그램에 따라서는 alt는 안 되면서 ctrl+alt 조합은 인식되는 경우도 있는데, 이것도 모든 프로그램에서 다 되는 건 아니다. 그러니 일반적으로 alt는 사용할 수 없다고 생각하는 게 속 편하다.
7. 나빌 한글 입력기와 3-18Na 입력 방식
지난 2000년대에는 '새나루'라고 Windows용 오픈소스 한글 IME 프로젝트가 있었다. 얘는 Windows XP 시절을 풍미하면서 활발하게 개발돼 왔지만 개발이 중단되고 2010년대부터는 맥이 끊어졌다.
그런데 바로 올해엔 어느 용자 능력자께서 '나빌'이라는 한글 IME를 개발하여 오픈소스 진영에 기여했고, 두벌식 글쇠배열 기반으로 신세벌식 원리(중성· 종성 중첩)를 적용한 자기 나름의 새로운 한글 입력 방식까지 제안해 놓았다. 컴퓨터 아키텍처 쪽으로 책도 쓴 유명한 분이던데..
내가 저분의 개발 후기를 읽으면서 정말 놀라고 감탄한 것은.. 세벌식 자판부터 시작해서 Windows 프로그래밍과 새로운 TSF 스펙, 예제 코드까지.. 나라면 몇 주 몇 달 이상을 끙끙대며 삽질했을 새로운 지식과 정보들을 단순히 잉여질(?)만으로 그 짧은 시간 만에 몽땅 습득하고 응용해서 새로운 결과물을 뚝딱 내놓았다는 점이다.
난 정말 무식하게 오래 질질 끌고 한 우물만 오래 팠기 때문에 이 정도 경험과 기술이 축적된 거지, 밑바닥부터 시작하면 절대로 저렇게 못 했을 것이다.
인간의 창의성과 지적 능력의 끝이 어디인지를 다시 생각하게 된다. 이번 버전에서는 3-18Na 입력 방식을 내 프로그램의 설정 예제로 구현해서 추가했다.
아이고 글이 또 왜 이리 길어졌나..? 아무튼, 이번 버전도 유용하게 사용하시기 바란다.
홈페이지의 트래픽을 관리하기 위해 64비트 바이너리는 여전히 Google Drive 링크로 제공하고 있다. 하지만 내 홈페이지에도 파일 자체는 올라와 있다. *_x86.msi 대신 *_x64.msi로 말이다.
그나저나 페이스북 의견 페이지가 왜 또 안 뜨고 있나 모르겠다.
Posted by 사무엘