지금 와서 가만히 생각해 보니, 컴퓨터 알고리즘을 동원하여 푸는 문제들은 다음과 같은 세 범주로 나눌 수 있는 것 같다. 뒤로 갈수록 설명이 길어진다.
1. 최적해를 다항 시간 만에 구할 수 있으며, 직관적인 brute-force 알고리즘과 뭔가 머리를 쓴 알고리즘이 시간 복잡도 면에서 충분히 유의미한 차이를 보이는 문제
간단한 발상의 전환으로 인해서 속도가 드라마틱하게 빨라질 수 있고, 알고리즘에 대한 정량적인 분석도 어렵지 않게 다 되는 경우이다. 요런 게 알고리즘 중에서는 가장 무난하다. 정보 올림피아드에도 이런 부류가 가장 많이 나온다.
가장 전형적인 예는 시간 복잡도 O(n^2)가 O(n log n)으로 바뀐다거나, 지수함수 복잡도가 O(n^2)로, 혹은 O(n^3)이 O(n^2)로 바뀌는 것이다. 물론 시간 복잡도를 줄이기 위해서는 공간 복잡도가 시공간 trade-off 차원에서 추가되는 경우가 대부분이다. 중간 계산 결과들을 모두 저장해 놓는 다이나믹 프로그래밍 문제가 대표적인 예이다.
정렬, common subsequence 구하기, 그래프에서 최단거리 찾기 같은 깔끔하고 고전적인 문제들이 많다. 기하 분야로 가면 convex hull 구하기, 거리가 가까운 두 점 구하기도 있다. 하지만 세상에 산적한 문제들 중에는 이 1번 부류에 속하지 않는 것도 많다.
2. 최적해를 다항 시간 만에 구하는 것이 가능하지 않은 (것으로 여겨지는) 문제
P에는 속하지 않지만 NP에는 속하는 급의 문제이다. 이건 다항 시간 만에 원천적으로 풀 수 없는 문제를 말하는 게 아니며 개념과 관점이 사뭇 다르다. 비결정성 튜링 기계라는, 실물이 없는 이론적인 계산 기계에서는 그래도 다항 시간 안에 풀 수 있다는 뜻이다.
입력 데이터의 개수 n에 비례해서 상수의 n승 내지 n 팩토리얼 개수의 가짓수를 일일이 다 따져야 하는 문제라면 다항 시간 만에 풀 수가 없다. 그런데 실생활에는 이런 무지막지하게 어려운 문제가 은근히 많이 존재한다. 진짜 말 그대로 n!개짜리 뺑이를 쳐야 하는 외판원 문제가 대표적이고, 그래프에도 '해밀턴 경로 문제'처럼 이런 어려운 문제가 산적해 있다. 이런 분야의 문제는 소위 말하는 NP-complete, NP-hard이기도 하다.
요런 문제는 brute force 알고리즘으로는 대용량 데이터를 도저히 감당할 수 없고 그렇다고 다항 시간 최적해 알고리즘이 있는 것도 아니기 때문에, 이런 문제는 100% 최적해는 포기하고 그 대신 95+n%짜리로 절충하고 시간 복잡도는 O(n^2)로.. 뭔가 손실 압축스럽게 tradeoff를 하게 된다.
국제 정보 올림피아드에는 이런 문제가 많이는 안 나오지만 전혀 안 나오는 건 아니다. 출제된다면 답은 최적해와의 비율로 점수가 매겨지며, 프로그램 실행이 아닌 그냥 제출형으로 출제되기도 한다.
P와 NP 사이의 관계는 전산학계에서 만년 떡밥이다. 현실에서는 마치 장기간 실종자를 법적으로 사망한 것과 마찬가지로 간주하듯이 P와 NP는 서로 같지 않다고 여겨지고 있다. 이를 전제로 깔고 발표된 연구 논문들도 수두룩하다. 하지만 그게 정말로 딱 그러한지는 전세계의 날고 기는 수학자들이 여전히 완벽하게 규명을 못 하고 있다.
엔하위키에는 P!=NP임을 증명하는 사람은 전산학 전공 서적에 이름이 실릴 것이고, P=NP임을 증명하는 사람은 아예 초등학생 위인전에 등재될 것이라고 얘기를 했는데... 적절한 비유인 것 같다. 지수함수 brute force 말고는 답이 없는 문제가 좀 있어야 암호와 보안 업계도 먹고 살 수 있을 텐데..!
3. 최적해를 다항 시간 만에 구할 수 있음이 명백하고, naive 알고리즘도 실생활에서 그럭저럭 나쁘지 않은 결과가 나오지만, 그래도 미시적· 이론적으로는 최적화 여지가 더 있는 심오한 문제
말을 이렇게 어렵게만 써 놓으면 실감이 잘 안 가지만 이 그룹에 속하는 문제의 예를 보면 곧장 "아~!" 소리가 나올 것이다. 이 분야에도 어려운 문제들이 은근히 많다.
(1) 문자열 검색
실생활에서는 그냥 단순한 알고리즘이 장땡이다. 원본 문자열을 한 글자씩 훑으면서 그 글자부터 시작하면 대상 문자열과 일치하는지 처음부터 일일이 비교한다. 실생활에서 텍스트 에디터는 대소문자 무시, 온전한 단어 같은 복잡한 옵션들이 존재하며 각 글자들의 변별성도 높다(대상 문자열과 일치하지 않는 경우 첫 한두/두세 글자에서 곧바로 mismatch가 발생해서 걸러진다는 뜻). 그 때문에 그냥 이렇게만 해도 딱히 비효율이 발생할 일이 없다.
하지만 문자열 검색이라는 건 실무가 아닌 이론으로 들어가면 생각보다 굉장히 심오하고 난해한 분야이다. 원본과 대상 문자열이 자연어 텍스트가 아니라 오로지 0과 1로만 이뤄진 엄청 길고 빽빽하고 아무 치우침이 없는 엔트로피 최강의 난수 비트라고 생각하자. 그러면 예전에 패턴이 어디서부터 어긋났는지를 전혀 감안하지 않은 채 오로지 1글자씩만 전진하는 방식은 효율이 상당히 떨어진다. 이제야 좀 더 똑똑한 문자열 검색 알고리즘이 필요해진다.
퀵 정렬의 중간값(pivot) 선택 알고리즘을 의도적으로 엿먹이는 '안티' 데이터 생성 알고리즘만큼이나..
특정 문자열 검색 알고리즘을 엿먹여서 언제나 최악의 경우로 한 글자씩만 전진하게 만드는 문자열 데이터를 생성하는 안티 알고리즘도 있을 것이다.
(2) 팬케이크 정렬
a1부터 a_n까지 임의의 수 배열이 존재하는데, 우리가 이 수열에 대해 취할 수 있는 동작은 여느 정렬 알고리즘처럼 임의의 두 원소끼리의 교환이 아니다. 1~2, 1~3 또는 1..m (m<=n)처럼 첫째부터 m째의 원소들을 모조리 역순으로 뒤집는 것만 가능하다. 1 7 4 2였으면 2 4 7 1로 바꾼다는 것. n개의 임의의 수열이 있을 때 수열을 정렬하기 위해 필요한 이론적인 최대 뒤집기 횟수는 정확하게 얼마나 될까? 한꺼번에 몇 개를 뒤집건 한번 뒤집는 데 걸리는 시간은 무조건 상수라고 가정하고, 뒤집기 자체 외에 다른 계산의 비용(가령, 현 구간에서 maximum 값을 찾는 것)은 전혀 고려하지 않아도 된다.
본인은 아주 어렸을 때 GWBASIC 교재에서 이 팬케이크 정렬 문제와 같은 방식으로 수열을 뒤집어서 "사람으로 하여금 문제를 풀게 하는" 프로그램을 본 기억이 있다. 프로그램의 이름이 REVERSE였다.
이 문제는 마치 선택 정렬과 비슷한 방식으로 명백한 해법이 존재한다. 가장 큰 수가 m째 원소에 존재한다면 m만치 뒤집어서 가장 큰 수가 맨 처음에 오게 한 뒤, 판 전체를 뒤집어서(n만치) 그 수가 맨 뒤로 가게 하면 된다. 이 과정을 그 다음 둘째, 셋째로 큰 수에 대해서 계속 적용하면 된다.
그렇게 명백한 해법의 계산 횟수는 최대 2*n-3으로 알려져 있다. 하지만 이것은 그렇게 뒤집은 여파가 다음으로 큰 수들을 정렬하는 데 끼치는 영향이 감안되어 있지 않다. 물론 여기서 좀더 머리를 써 봤자 2n이던 계수가 1.xx 정도로나 바뀌지 그게 n 내지 심지어 log n급으로 확 바뀌지는 못한다. 비록 O(n) 표기상으로는 동일하지만 그렇게 상수 계수를 조금이라도 줄이는 최적화이다 보니, 알고리즘이 더 까다롭고 머리가 아프다.
마이크로소프트의 창립자인 그 빌 게이츠가 1979년에 바로 이 문제의 계산 횟수를 최적화하는 알고리즘을 (공동) 연구하여 이산수학 학술지에다 투고했었다. 이 사람의 기록은 그로부터 거의 30년이 지난 2008년에야 더 정교한 알고리즘이 나옴으로써 깨졌다. 이것은 빌이 단순히 비즈니스맨이기만 한 게 아니라 엔지니어 기질도 얼마나 뛰어났고 수학 쪽으로도 얼마나 천재였는지를 짐작케 하는 대목이다. 학부 중퇴 학력만으로도 이미 전산학 석· 박사급의 걸출한 리서치를 했으니 말이다.
(3) 행렬의 곱셈
갑자기 팬케이크 정렬 얘기가 좀 길어졌는데 다음 항목으로 넘어가자면.. 계산 관련 알고리즘도 이런 급에 속한다. 대표적으로 행렬.
일반적으로야 두 개의 n*n 정방행렬끼리 곱셈을 하는 데 필요한 계산량, 정확히 말해 두 수 사이의 곱셈 횟수는 정확하게 O(n^3)에 비례해서 증가한다. 그러나 거대한 행렬을 2*2 형태의 네 개로 쪼개고, 덧셈을 늘리는 대신 곱셈을 줄이는 방식으로 최적화를 하는 게 가능하다. 게다가 쪼개진 행렬이 여전히 크다면 그걸 또 재귀적으로 쪼갤 수 있다.
a+bi와 c+di라는 복소수의 곱셈을 위해서 통상적으로는 ab, ac, bc, bd라고 곱셈이 총 4회 필요하다고 여겨지지만 실은 덧셈을 더 하는 대신에 곱셈은 ac, bd와 (a+b)*(c+d)로 3회로 줄일 수 있지 않은가? 그런 식으로 줄인 것이다.
그렇게 해서 O(n^3)보다 이론상 작은 시간 복잡도가 최초로 제안된 게 1969년에 나온 슈트라센 알고리즘이다. 대략 O(n^2.8). 정확하게 2.8인 건 아니고 지수 자체가 로그 n 이런 형태로 떨어진다. 프랙탈의 차원 수가 로그로 표현되는 것처럼 말이다.
여기서 2.8x의 정확한 의미는 log[2] 7이다. 원래 2*2 행렬 두 개를 곱하기 위해서는 상수 곱셈이 8회 필요한데, 중간 과정의 공식들을 궁극의 캐사기 테크닉을 동원하여 변형했다. 어마어마한 양의 우회 연산을 통해 덧셈은 횟수가 왕창 늘었지만 곱셈이 8회에서 7회로 딱 1회 줄었다! (도대체 무슨 약 빨고 연구해서 이런 걸 생각해 냈을까? ㄷㄷ) 이 여파가 분할 정복법의 특성상 재귀· 연쇄적으로 적용된 덕분에 전체 시간 복잡도가 감소한 것이다.
그리고 이 바닥도 발전에 발전을 거듭한 덕분에 오늘날은 무려 O(n^2.4)대까지 곤두박질쳤다. 덧셈과는 달리 곱셈은 이런 최적화의 여지가 존재한다는 사실 자체가 아주 신기하지 않은가? 크기가 서로 다른 행렬들의 최소 곱셈 횟수를 구하는 다이나믹 프로그래밍 문제하고는 완전 별개의 영역이다.
아래의 그림을 보자(움짤임). RGB라는 세 대의 차량이 서로 부딪치지 않고 G는 그대로 위로, R과 B는 서로 좌우가 엇갈리게 빠져나가려면 어떻게 하면 좋을까? 아래의 중앙은 길이 막혔기 때문에 횡단을 할 수 없다.
결국 가운데 G는 곧이곧대로 위로 나가서는 안 되며, R과 B의 경로를 피해서 몇 배나 더 긴 우회를 해야 한다. 하지만 그래도 RGB 모두 신호 대기가 없이 서로 엇갈리는 방향으로 술술 소통이 가능하다.
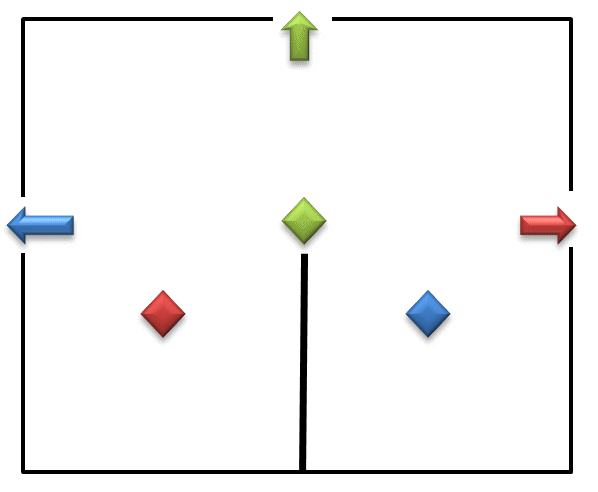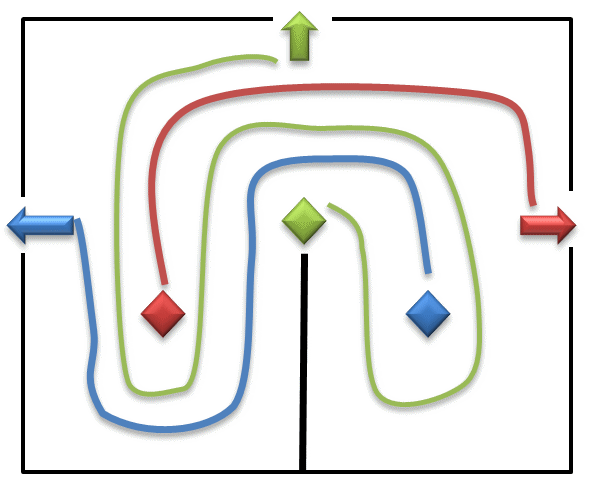
자연에는 관성이라는 게 존재하니, 다리가 아니라 바퀴가 달린 자동차나 열차에게는 우회를 하더라도 이게 훨씬 더 나은 방법인 것이다.
행렬도 덧셈이라는 우회가 아무리 몇 배로 더 늘어 봤자, 아주 큰 행렬(차량 소통이 엄청 많을 때)에 대해서는 곱셈이 눈꼽만치라도 줄어드는 게 도로로 치면 신호 대기가 없어지는 것에 맞먹는 이익이 될 수 있다는 생각이 든다.
물론 행렬의 곱셈 시간 복잡도가 O(n^2)보다 더 낮아질 리는 없으며, 저런 알고리즘들은 지수를 줄이는 대신 공간 복잡도(스택 사용..) 같은 다른 오버헤드가 왕창 커졌다는 점을 감안해야 한다. 크기가 몇십~몇백 정도 되는 초대형 행렬에서 두각을 발휘하지, 그냥 3차원 그래픽용으로나 간단히 쓰이는 3*3이나 끽해야 4*4 행렬에서 적용할 만하지는 않다.
Posted by 사무엘