1. 파일 대화상자라는 개념
윈도우 운영체제.. 사실 이뿐만이 아니라 플랫폼을 불문하고 현대적인 GUI 프레임워크들은
불러오기/저장하기(파일 선택) 기능을 공통 기능으로 제공한다.
어떤 형태로든 사용자가 작업하는 문서(데이터)를 파일로 읽고 쓰는 소프트웨어치고 이 기능을 안 쓰는 녀석은 없으므로, 이건 가히 필수 공통 기능이라 하기에 손색이 없다. 도스 시절에는 불러오기/저장하기 UI도 프로그래머가 제각각으로 직접 구현해야 했으니 얼마나 번거로웠는지 모른다. 이거 하나만 운영체제가 고수준 API를 제공해 줌으로써 응용 프로그램이 직접 FindFirstFile, FindNextFile 같은 파일 탐색 함수를 호출해야 할 일은 상당수 없어졌다.
물론 이것 말고도 색깔을 찍는 대화상자, 인쇄 대화상자 같은 것도 공통 대화상자에 속하며 운영체제가 제공해 주는 게 있다. 그리고 필요한 경우, 대화상자의 일부 요소나 동작 방식을 프로그래머가 자기 입맛에 맞게 customize하는 테크닉도 응당 제공된다.
2. 윈도우 운영체제의 파일 대화상자의 역사
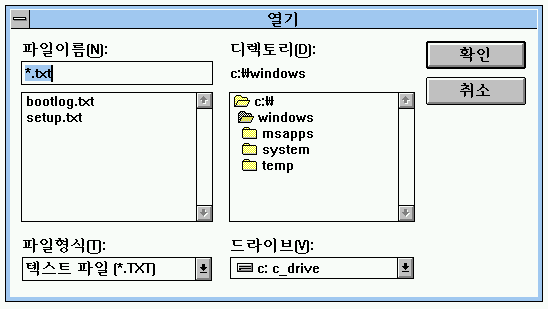
윈도우 3.x의 파일 대화상자는 파일 목록과 디렉터리 목록이 리스트 박스의 형태로 좌우로 나란히 나오고, 그 아래에는 저장하거나 열려는 파일의 format 그리고 드라이브 목록이 콤보 박스의 형태로 나란히 나와 있었다. 드라이브-디렉터리-파일이라는 클래식한 형태에 충실한 디자인이라 하겠다. 가정에서는 네트웍이 아직 많이 생소하던 시절이었기 때문에, 네트웍 드라이브에 접근하기 위해서는 별도의 버튼을 눌러야 했다.
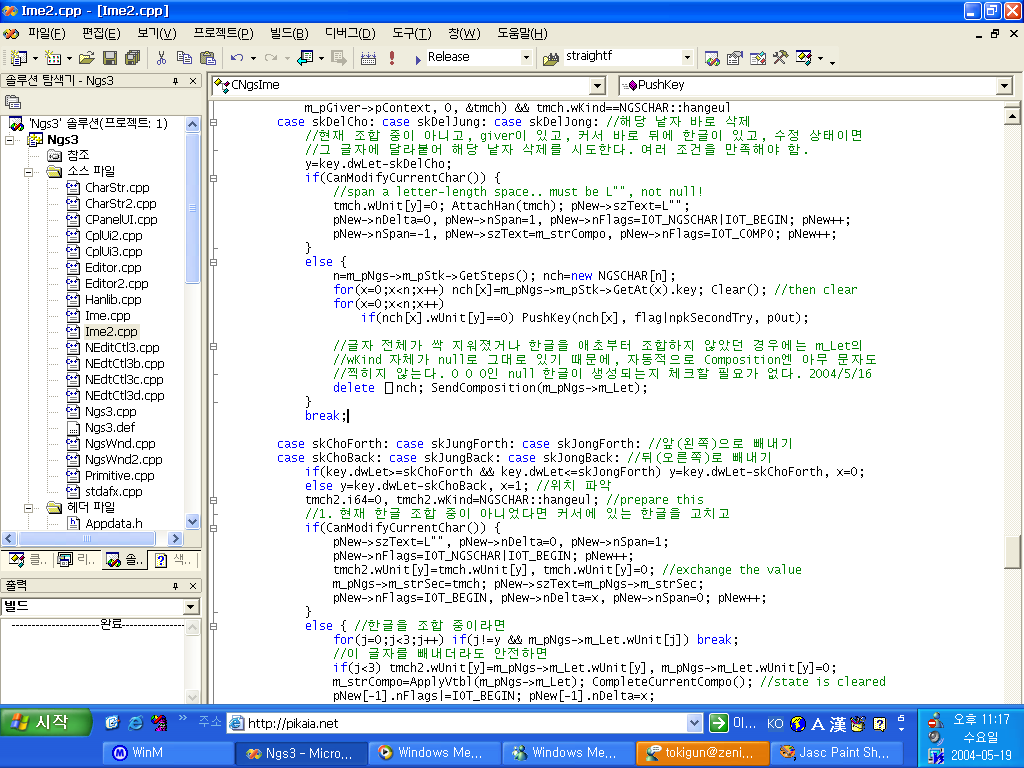
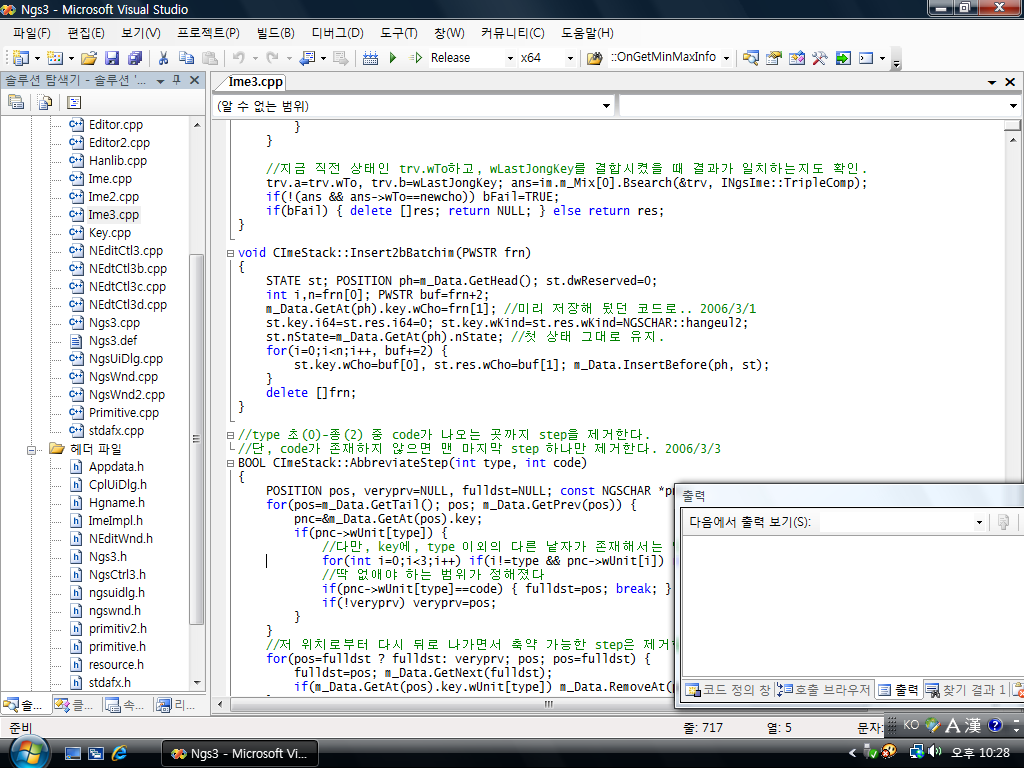
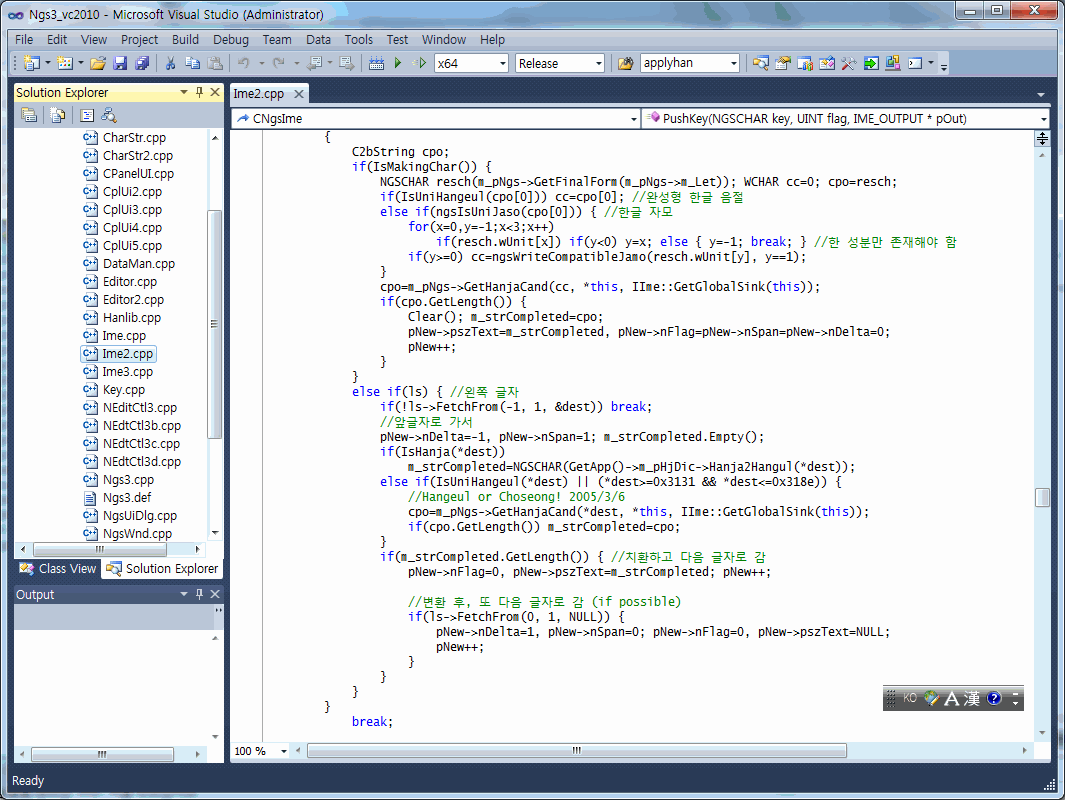
그러던 것이 윈도우 95/NT4에 와서는 크게 바뀌었다. 사실 윈도우 95부터는 쉘의 디자인의 근간이 싹 바뀌어 오늘날까지 이어져 오고 있다. 드라이브를 제공하는 장치간의 구분이 완화되었고, 가장 최상위 계층인 바탕 화면 아래로 내 컴퓨터, 휴지통 등등이 따르는 컨셉이 이때 도입된 것이다. 파일 리스트는 구닥다리 리스트 박스 대신, 소위 공용 컨트롤이라고 불리는 리스트뷰 컨트롤 기반으로 바뀌고 디렉터리와 드라이브는 폴더라는 개념으로 바뀌었다. 그리고 탐색기가 제공하는 쉘 기능(파일 복사, 붙여넣기, 삭제, 개명, 각종 우클릭 메뉴)은 파일 대화상자 내부에서도 그대로 쓸 수 있게 된 것 역시 큰 변화이다.
윈도우 98부터는 파일 대화상자의 크기 조절이 가능해졌다. 상당히 바람직한 변화이다.
윈도우 2000/ME부터는 파일 리스트 왼쪽에 바탕 화면, 내 문서 등 주요 폴더로 곧바로 이동하는 아이콘이 추가되었다(일명 favorite bar). 그리고 아마 이 무렵부터, 파일이나 디렉터리 이름의 처음 몇 자를 입력하면 자동 완성 후보가 뜨는 아주 편리한 기능이 생겼다.
이 구조가 윈도우 XP까지 이어지다가 비스타/7부터는 또 파일 대화상자가 싹 바뀌었다. 변화의 양상에 대해 한 마디로 요약하자면, 탐색기와의 경계가 더욱 모호해지고 좀더 "웹처럼"(webby) 바뀌었다. 웹 페이지 탐색하는 기분으로 내 컴퓨터의 폴더를 탐색하게 되었는데, 이는 IE4부터 MS에서 부르짖은 캐치프레이즈이기도 하다. 물론 탐색기와 IE의 완전 통합은 보안상의 이유로 인해 IE7부터는 좀 지양되었지만 말이다.
얼마나 바뀌었냐 하면, 파일 대화상자에도 웹브라우저처럼 "뒤로, 앞으로" 버튼이 생겼고, 검색란이 생겼다. 자주 쓰는 폴더 목록은 마치 인터넷 즐겨찾기처럼 뜨기 시작한 것이다. 그런 디자인이야 디자이너의 취향 나름이라 하지만, 기본 크기가 좀더 큼직해지고 마우스로 두세 단계의 폴더를 바로 건너뛰어 상위 단계로 갈 수 있어서 디렉터리 변경이 좀더 편해진 게 매우 좋다.
3. 과거 호환성
이렇게 운영체제가 버전업되면서 파일 대화상자의 디자인은 몇 차례 변화를 겪었다.
응용 프로그램이 아무 조작을 안 가하고 기계적으로 MSDN에 명시된 input과 output만 FM대로 잘 활용한다면, 파일 대화상자의 디테일은 응용 프로그램의 본질적인 동작에 전혀 영향을 끼치지 않는다. (당연한 말이지만)
그렇기 때문에 윈도우 비스타 이전에 개발된 프로그램이라 할지라도, 파일 대화상자 API만 곱게 쓴다면 비스타에서 실행했을 때 최신 디자인의 파일 대화상자가 뜬다. 이게 무슨 공용 컨트롤 매니페스트도 아니고, 최신 대화상자를 쓰기 위해서 응용 프로그램이 뭔가 조치를 취해야 할 필요는 없다.
그럼에도 불구하고 운영체제들은 옛날 버전 파일 대화상자들의 디자인도 갖고는 있다.
응용 프로그램이 파일 대화상자에다가 자신만의 컨트롤을 추가하고, 동작 방식을 제어하고 특정 컨트롤을 서브클래싱까지 하는 경우, 그 파일 대화상자의 디자인이 최신 운영체제에서 바뀌어 버린다면 동작 방식에 심각한 문제가 생길 수 있기 때문이다.
이미지 프로그램의 경우 열기 대화상자에다가는 그림 preview를 추가하기도 하고, 저장 대화상자에다가는 JPG로 저장할 경우 화질을 지정하는 추가 옵션을 대화상자에다 덧붙이곤 했다.
압축 유틸리티나 파일 변환 프로그램은 아예 파일 열기 대화상자에다가 자기네 동작 옵션을 한 보따리 가득 집어넣어 그걸로 프로그램 메인 화면을 만들기도 했다는 걸 알 필요가 있다.
최신 디자인을 적용할 수 없는 경우, 운영체제는 여전히 윈도우 2000이나 심지어 98(favorite bar까지 없어진) 스타일로 파일 대화상자를 출력해 준다.
특히 MFC를 써서 프로그램을 개발하는 경우 이 점을 매우 신경써야 한다. MFC는 프로그래머가 원하는 타이밍에 손쉽게 이벤트를 날려 주기 위해서.. 쉽게 말해 개발자의 편의를 위해서 윈도우에다가 온갖 보이지 않는 훅킹과 서브클래싱을 남발하는데, 이런 이유로 인해서 구형 버전의 비주얼 C++로 CFileDialog 클래스를 쓰면, 아무리 내가 customize를 하는 게 없어도 최신 운영체제에서 파일 대화상자가 최신 디자인으로 나오지 않는다!
까놓고 말해 본인이 개발한 <날개셋> 편집기의 열기 대화상자와, <날개셋> 타자연습의 연습글 추가 대화상자를 윈도우 비스타/7에서 살펴보기 바란다. 차이가 느껴질 것이다.
이런 이유로 인해, 최신 운영체제의 GUI 혜택을 입으려면 새로운 기능을 쓰는 게 없어도 개발툴도 최신으로 써야 하는 경우가 있다. 싫으면 MFC 클래스 쓰지 말고, 불편하더라도 GetOpenFileName처럼 윈도우 API를 직접 호출하든가 말이다. ^^
4. 파일 대화상자의 중복 개발
그런데 MS 오피스 제품들은 전통적으로 운영체제의 표준 API를 쓰지 않고, 무려 자기네가 따로 자체 개발한 파일 대화상자를 사용해 왔다. 가령, 운영체제의 표준 파일 대화상자는 윈도우 2000/ME대에 가서야 favorite bar가 추가된 반면, MS 오피스의 대화상자는 꽤 일찍부터.. 최소한 오피스 97 시절부터 그런 걸 갖추고 있었다.
이런 식으로 MS 내부에서 운영체제 GUI가 오피스 GUI를 뒤쫓아가는 양상은 일상적인 모습 같다. 하다못해 윈도우 3.1 시절에도 오피스가 자체 구현했던 도구모음줄(toolbar), 상황선(status bar), 은빛 3D 효과 대화상자, 프로퍼티 시트와 위저드 같은 게 95로 넘어가면서 운영체제 표준 GUI로 나중에야 편입되었다. 그러던 관행이 세월이 흘러 윈도우 7에서는 리본 인터페이스가 워드패드와 그림판에까지 적용되어 있다.
오피스 제품 중에서도 무려 1980년대부터 개발되어 온 워드와 엑셀은, 겉모습은 별 차이 안 나지만 사실 일반 대화상자들마저도 윈도우 운영체제의 표준 대화상자가 아니며 마치 아래아한글처럼 자체 구현 대화상자이다! 걔네들이 처음부터 아주 크로스 플랫폼으로 개발되어서 그런 건 아니고, 애초에 개발 컨셉이, 빈약한 운영체제의 기본 컴포넌트에 의존하지 않고 자기네 컴포넌트로 UI를 자체 구상하겠다는 방향이었던 것 같다. 그 부자 기업이 하고 싶은 걸 뭘 못 하겠는가?
90년대 이후부터 개발된 파워포인트나 액세스는 그런 수준까지는 아니지만 열기/저장 대화상자라든가 About 대화상자만은 여전히 MS 오피스 공용 라이브러리의 것을 사용해 왔다.
개발툴인 비주얼 스튜디오도 닷넷급부터는 MS 오피스의 GUI 엔진을 이어받고 있는 중이다. 순수 MFC만으로 MS 오피스 짝퉁 GUI을 구현했던 비주얼 C++ 5와 6의 계보는 흑역사가 된 지 오래.
그런데, 그러던 정책이 이제는 바뀌었다.
윈도우 비스타와 동일한 timeline에 개발된 제품인 비주얼 스튜디오 2008과 MS 오피스 2007부터는
놀랍게도 운영체제의 표준 파일 대화상자를 사용하며, 앞으로도 계속 그런 구도가 유지될 것이다!
비주얼 스튜디오 2005와 MS 오피스 2003은 그렇지 않다는 소리.
다만, 이건 비스타 이상에서 실행됐을 때에 한해서이다. 윈도우 XP에서 돌아가는 비주얼 스튜디오 2008이나 MS 오피스 2007은 여전히 자체 대화상자를 사용한다. -_-;; 이것도 무지 신기한 점임.
비스타부터는 이제 운영체제의 파일 대화상자도 기능이 매우 향상되었고 customize하는 수단도 충분히 깔끔해졌기 때문에 굳이 운영체제 따로, 오피스 따로 노선을 갈 필요를 느끼지 않게 되어 그렇게 바뀐 것 같다.
비스타에서는 비주얼 스튜디오 2005의 옛날식 파일 대화상자가 오히려 더 촌스럽게 느껴진다. ^^;;
Posted by 사무엘