1. 단품 판매되는 DOS
(1) 197, 80년대에는 컴 단말기가 아니라 개인용 컴퓨터라는 건 이제 막 정립되고 있었고, 소프트웨어도 하드웨어와 함께 딸려 나오는 게 아니라 독립된 제품이라는 인식이 이제 막 정립되던 중이었다.
그래서.. 마소에서 만들었던 MS-DOS도 말이다. 1.0부터 4.x에 이르기까지는 다들 PC와 함께 OEM 형태로만 공급됐다. 도스 자체가 단품 패키지로 개별 소비자에게 retail 판매되기 시작한 건 1991년, 무려 5.0부터였다고 한다. himem.sys와 DOS=HIGH가 첫 도입됐던 그 역사적인 물건 말이다.
아 글쎄.. Windows 1.x 시절이던 1986년에 3.2 버전도 단품 패키지가 있긴 했다. 하지만 이때는 이 방식이 오래 지속되지는 못한 듯하다.
 |  |
현실적으로 대다수 사용자들이 패키지 판매를 기억하는 건 아무래도 끝물인 6.x버전이지 싶다. 이 무렵에 마소는 IBM과 사이가 단단히 틀어져서 PC-DOS와 MS-DOS의 격차도 벌어지고, Windows와 OS/2도 격차가 벌어졌었다.
1990년대 들어서 MS-DOS는 이렇게 독립을 했는데, 매크로 어셈블러(Macro Assembler)는 그 무렵쯤에 반대의 길을 갔다. 단독 독립 제품으로서는 단종이고, MS C/C++이나 Visual Studio 같은 더 큰 제품에서 제공되는 유틸리티로 흡수되었다.
(2) MS-DOS가 대기업의 PC와 함께 공급되던 시절, 대략 쌍팔년도 정도까지는 한글 MS-DOS에 내장돼 있던 한글 바이오스도 PC 제조사들별로 제각각이었다.
- PC 제조사: 대우, 금성, 현대, 삼보 등
- 제3자 써드파티: 도깨비, 한메, 태백 등
- 마소 자체 개발: hbios, mshbios. Windows 3.1 + MS-DOS 6부터.
한글 바이오스 만드는 게 첨단 시스템 프로그래밍이던 시절이 있었다니.. 추억 돋는다. =_=;;
기능이 제일 많고 성능도 뛰어나던 건 역시 써드파티 제품들이었다. 조합형도 지원하고, 다양한 폰트와 글자판(세벌식까지)도 지원했지만.. 역시 1990년대 중후반쯤부터는 개발의 맥이 끊겼다.
현재 한글 바이오스가 돌아가는 중인지를 무슨 API를 호출해서 어떻게 판별했는지 궁금하다.
(3) MS-DOS는 버전 1부터 4까지는 OEM이었고 5~6 사이에 잠깐 독립 제품.. 그리고 마지막 7~8 버전은 Windows 9x에 포함된 채로 제공.. 이렇게 역사가 정리된다.
그 중에 OEM 끝자락이던 MS-DOS 4는 DOS shell이 처음 도입되었고 FAT16 파일 시스템의 개편으로 하드디스크 용량을 2GB까지 인식할 수 있게 하는 큰 변화가 있었다(종전에는 꼴랑 32MB까지만.. =_=) 하지만 4.0은 버그가 너무 많아서 곧 4.01로 패치가 돼야 했다.
이건 마치 버그가 너무 많아서 온갖 서비스 팩들이 덕지덕지 나와야 했던 Windows NT 4의 행로와도 비슷해 보인다.
그리고 개발툴 중엔 Visual Studio .NET 첫 버전(2002, 7.0)이 금세 묻혀 버렸던 것과도 처지가 비슷하다.
(4) 끝으로.. MS-DOS의 대체품으로 DR-DOS라는 게 있기도 했고, 그걸 한때 네트워크 솔루션으로 유명했던 어느 기업에서 인수하여 노벨 도스로 계승되었다.
한편, MS-DOS의 셸만 대체해서 강화한 제품으로 4DOS라는 게 있었다. 그걸 노턴 유틸리티에서 인수해서 더 발전시킨 게 NDOS...이다. 노벨 도스와 이니셜이 같지만 이들은 서로 다른 제품이다.
2. Rational
옛날에 Rational이라는 이름을 가진 컴퓨터 소프트웨어 회사가 둘 있었다.
(1) Rational Software는 소프트웨어공학 툴이라고 해야 하나.. 딱 정확하게 개발툴, IDE나 컴파일러는 아니지만 어쨌든 소프트웨어 설계· 개발과 관련이 있는 전문 도구를 개발해 왔다. 콕 집어 코딩, 프로그래밍이라기보다는.. 더 거시적인 소프트웨어 개발 말이다.
Rose라는 툴이 유명했다. 꽃하고는 별 관련 없고, 다른 단어들의 이니셜이 저렇게 된 거지 싶다. 내 기억으로 Visual C++ 6 시절에 엔터프라이즈 에디션에는 Rose의 데모 축소판이 번들로 제공됐던 적이 있었다.
얘의 제조사는 2003년에 IBM에 인수됐다. IBM이 PC용으로 소프트웨어를 만든 게 지금은 망한 운영체제 OS/2, 그리고 유구한 역사를 자랑하는 통계 패키지 SPSS 정도밖에 없는 줄 알았는데.. 지금은 Rose도 IBM 휘하로 넘어갔는가 보다.
하긴, 엑셀에 대항하여 넥셀이 있고, AutoCAD에 대항하여 캐디안이 있는 것처럼.. Rose의 저렴한 국산 대체제로 StarUML이라는 제품도 있다.
개인적으로는 직장에서 보고서 쓸 때 각종 UML 다이어그램 그리는 용도로 사용해 봤다.;; 클래스 관계 모식도라든가 각종 시퀀스 다이어그램 따위..
하긴, 그 비싼 프로그램에 겨우 다이어그램을 그리는 기능밖에 없으면 그냥 Visio 같은 벡터 드로잉 툴과 아무 차이가 없을 것이다. 그럴 리는 없고, 여기서 만든 설명대로 Java 클래스 파일을 생성하고 문서를 생성하는 기능도 있었던 걸로 기억한다.
(2) 그 다음으로 Rational Systems라는 곳이 있었다. 얘는 1980년대부터 DOS extender만 전문으로 개발해 왔다. 16비트에 640KB 메모리에 쩔어 있던 도스 환경에서 보호 모드를 구현하고, 메모리를 골치 아픈 제약 없이 32비트 그대로 접근하게 해 주는 획기적인 런타임 말이다.
사실, DOS extender라는 걸 처음으로 개척한 회사는 Phar Lap이었다. 워크스테이션에서나 돌릴 만한 거대한 업무용 프로그램을 PC용으로 포팅할 때 원래 Phar Lap의 extender가 주로 쓰였다. 옛날에 도스용 아래아한글도 전문용 내지 32비트 에디션은 얘를 사용했다.
그러나 Rational Systems에서는 DOS/4G라는 제품을 개발하고, 이걸 Watcom C/C++ 컴파일러에 DOS/4GW라는 번들 버전으로 아주 저렴하게 공급해 줬다. 1993년 말에 Doom이라는 게임이 딱 이 솔루션을 사용해서 출시되면서 DOS/4GW라는 32비트 extender는 세계적인 히트를 치게 됐다.
환상적인 그래픽을 선보였던 Doom이 어셈블리어를 거의 쓰지 않고 이식성 높은 C 코딩으로만 구현될 수 있었던 비결엔 이런 신기술이 있었던 것이다. 물론 그래픽을 제대로 보려면 그 당시로서는(1993~1995) 아직 가격이 부담되는 고성능 컴터이던 486급이 필요했지만 말이다.
그리고 Doom은 이 장르에서 하드웨어 가속이 없이 CPU 연산/소프트웨어만으로 동작한 마지막 게임이기도 했다. ^^ 이렇게만 동작해서는 320*200보다 더 높은 해상도에서 3D 폴리곤 그래픽이 실시간 애니메이션으로 나오기란 굉장히 무리였을 것이다. 뭐, 그래픽의 하드웨어 가속에도 더 높은 데이터 대역폭이 필요할 것이고, 32비트 버프가 기여했다고 볼 수 있다.
1990년대 중후반까지 덩치 큰 도스용 게임들은 처음 실행될 때 DOS/4GW 로고가 뜨는 게 무척 많았다. 이게 무슨 흥행 보증수표처럼 느껴질 정도로..;;
PC 역사에 한 획을 그었던 이 개발사는 훗날 Tenberry Software이라고 이름이 바뀌고 2000년대 초반까지는 살아 있었다. 하지만 도스 시절이 끝난 뒤엔 없어졌는지 근황을 모르겠다.
요컨대, 두 Rational들은 분야는 다르지만 과거에 뭔가 비범한 소프트웨어들을 개발하곤 했다. ^^.
3. 옛날에 C++ 코딩 환경
난 왕년에 이런 시퍼런 화면에서 코딩을 해 봤다. -_-;;
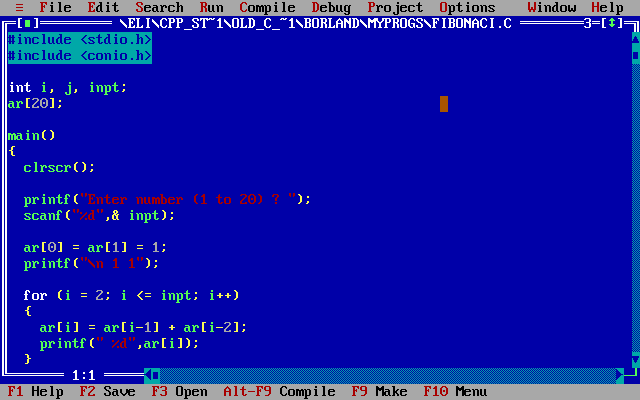
쌍팔년도를 넘어서 1990년대가 되자.. 이제 막 C가 아니라 C++ 직통 컴파일러라는 게 처음으로 등장했다. 그리고.. IDE의 텍스트 에디터에 syntax coloring이라는 게 제공되기 시작했다.
코드에서 예약어는 진하게 표시하고, 전처리기는 별도의 색깔로, 상수 리터럴이나 주석도 별도의 색깔로.. 이거 말이다. 하긴, 1990년대는 이제 막 VGA와 컬러 모니터가 보급되었던 시절이고, 286이니 386이니 하던 컴터 성능도 실시간 컬러링을 구현해도 될 정도로 향상됐다.
그 당시 도스용 컴파일러의 본좌는 볼랜드...였는데, Turbo C++ 3.0 버전부터 IDE에서 컬러링이 지원되기 시작했다. 1과 2 시절엔 저런 게 아직 없었다.
오 그런데... 말로만 듣던 Turbo C++와 Borland C++가 차이가 있었나 보다. 난 Turbo C++ 것만 어린 시절에 직접 봤었다.
일반 명칭은 초록색, 문자열 상수는 빨강, 전처리기는 저렇게 청록색 바탕, 기호가 노란색 말이다.
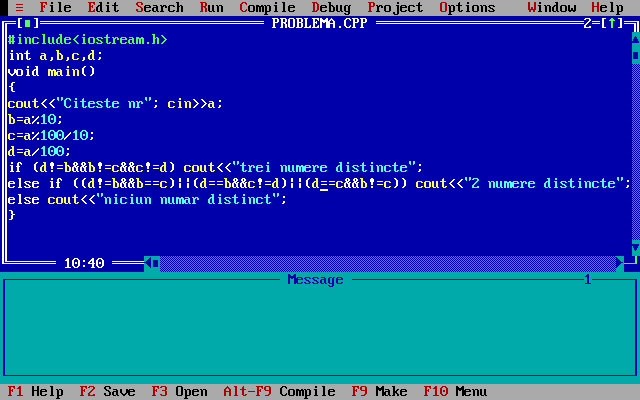
그러나 Borland C++은 보니까 일반 명칭이 노랑, 문자열 상수는 청록, 전처리기가 초록, 기호는 하양이다.
난 도스용 볼랜드 개발툴 IDE에서 C++의 컬러링이 저렇게 되는 건 직접 본 적이 없고, 구글 검색을 통해서 난생 처음 본다. 비슷한 시기에 동일 회사에서 내놓았던 Borland Pascal과 더 비슷해졌다. 우와..
사실, Turbo와 Borland의 차이는 Visual Studio로 치면 standard 에디션(개인용)과 enterprise 에디션(기업용) 같은.. 에디션 급의 차이와 비슷하다.
아.. 옛날에.. 볼랜드 IDE를 따라 djgpp 진영에서 개발했던 rhide는.. C/C++ 코드에 대한 컬러링이 Turbo가 아니라 Borland C++ 스타일이었다. 자, 난 저런 것도 기억하는 세대다. -_-;;;;
프로그래밍, 코딩이라는 건 30년 전이나 지금이나 재미있다.
참고로, 코딩 하다가 .이나 ->를 찍었을 때 멤버가 쫘르륵 나오고 명칭이 자동 완성되는 기능은..
1990년대 "말"이 돼서야 제공되기 시작했다. 그건 그만큼 구현하기 더 어려운 기능이었고, PC가 못해도 펜티엄 2 이상급으로 성능이 좋아진 뒤에나 쓸 만했다.
요즘은 이 기능이 없으면 너무 불편해서 코딩을 못 할 것이다. 옛날에 텍스트 에디터가 불편하고 컴퓨터 메모리가 부족하던 시절에는 각종 함수 명칭을 아주 짧고 암호 같이 붙이는 게 관행이었지만..
지금은 코드 양이 너무 방대해지고 저런 자동 완성 기능도 발달하니 길게 길게 풀어서 써 주는 편이다. setmemmgr() 대신에 SetMemoryManager() 같은 식.
4. PowerBasic
198~90년대에.. BASIC이라는 프로그래밍 언어는 입문하기 간편한 대신, 인터프리터 방식 위주이고 실행 속도가 느리다는 게 상식 겸 통념이었다. 즉, 언제까지나 교육용이지, 실무용은 "영 아니올시다"였다. 그러나 BASIC에 대해 그 통념을 정면으로 도전하고 반박하는 이단아 제품이 있었으니, 바로 PowerBasic(파베)이었다.
얘는 BASIC이라는 언어에다가 C/C++ 같은 이념을 접목했다. 마소처럼 느린 P-code 갖고 깨작거리거나 비주얼 RAD 툴 컨셉을 씌우는 게 아니라, 최적화되고 단독 실행 가능한 네이티브 코드 컴파일을 추구했다. 그렇다, 이 컴파일러 엔진을 만든 주 개발자는 그야말로 x86 어셈블리어에 정통한 smaller, faster 최적화 덕후 장인이었다.
PowerBasic은 마이너 비주류 제품군이지만 나름 존재의 의미는 있었다. 베이식 언어로 C/C++ 급의 작고 빠른 프로그램을 생성해 줬기 때문이다. 자기 자신의 덩치도 Visual Studio에 비하면 그냥 깃털 같은 수준이니 아주 실용적이었다.
얘는 16비트 도스에서 32비트 Windows까지는 잘 갈아탔다. 하지만 그 이후의 시대 변화에는 따라가지 못한 채, 2020년대에 와서는 명줄이 사실상 끝난 상태이다.
일단, 주 개발자인 Bob Zale 할아버지가 별세한 지가 이미 10년이 넘었다. 적절한 후임 개발자를 양성하지 못했는지, 파베는 x64건 arm64건 일단 64비트 버전이 못 나오고 있다.
살상가상으로.. PowerBasic 컴파일러 자체부터가 통짜 어셈블리어=_=;;;로 개발됐고, 코드가 호락호락 maintainance 가능한 구조가 아니라고 한다. 이러면 뭐 과거의 OS/2나 dBASE 같은 꼴 나면서 죽는 건 시간 문제지..
그렇게도 성능에 목숨 걸었다지만, 최신 멀티코어 프로세서나 GPU에 맞춰진 컴퓨팅을 잘 지원한다는 얘기도 난 못 들었다. 이러면 머신러닝 스크립트인 파이썬의 용도를 대체하기도 대략 곤란해진다.
지금 생각하면 PowerBasic이 뭔가 슈퍼컴 Cray 같은 물건이라는 생각도 든다. 고전적인 성능 덕후 장인이 애지중지 만들었지만 시 대에 뒤쳐지고 도태됐다는 점에서 말이다.
글쎄, 쟤는 그 성능빨에다가.. 마소에서 버린 자식인 클래식 Visual Basic 6 코드를 지원하는 후속 써드파티 개발툴을 표방하고 나섰으면.. 마르지 않는 고객 수요를 확보하고 절대로 망할 일이 없었을 것 같은데 말이다. 그렇지 않은가? 이렇게 사라지기에는 아깝고 아쉽다.
쌍팔년도 시절에 볼랜드와 마소가 PC용 베이식, C, 파스칼 컴파일러 시장을 꽉 잡고 있긴 했다. 하지만 그 컴파일러들은 처음부터 그 회사에서 만든 게 아니었다. 다들 다른 사람이나 영세업체의 제품을 인수한 것에서부터 개발을 시작했다.
- BASIC/Z by Bob Zale --> Turbo Basic (요게 PowerBasic의 전신)
- Wizard C by Bob Jervis --> Turbo C 1.0 in 1987
- PolyPascal by Anders Hejlsberg --> Turbo Pascal
- Lattice C --> Microsoft C
Posted by 사무엘