Windows에는 문자열을 입력받는 일반 에디트 컨트롤뿐만 아니라 글자마다 서로 다른 서식(글꼴, 크기, 진하게/이탤릭, 탭, 문단 정렬, 하이퍼링크..)을 주고 그림이나 표를 집어넣을 수도 있는 리치(rich) 에디트 컨트롤이라는 게 있다.
그야말로 소형 워드 프로세서가 통째로 윈도우 컴포넌트로 만들어진 셈이니 이건 굉장한 혁신이었다. 심지어 특정 용지 크기에 맞게 위지윅(장치 독립 레이아웃)을 지원하기 위해 기준으로 참조할 DC를 지정하는 기능도 있고.. 아예 윈도우 없이 에디팅 엔진의 동작만 뽑아서 쓰라고 windowless rich edit control이라는 라이브러리도 제공된다. 이 정도면 작정하고 굉장히 세심하게 만들어진 셈이다.
Windows의 기본 예제 프로그램 중 하나인 워드패드가 얘를 써서 만들어진 것으로 유명하며, 초창기에는 Visual C++에 워드패드의 소스가 통째로 제공되기도 했다.
얘의 내부 자료구조는 RTF라는 파일 포맷으로 제정되어서 마소뿐만 아니라 애플 같은 타 회사에서도 쓰기 시작했다. 단적인 예로 macOS의 TextEdit도 이 포맷을 지원한다.
다만, RTF는 HTML이라는 완벽한 상위 호환이 등장하면서 존재감이 굉장히 묻혀 버린 감이 있다. 당장 도움말만 해도 16비트 Windows 시절에는 RTF 기반의 hlp였지만 곧장 HTML 기반으로 대체됐으니 말이다.
상업용 워드 프로세서보다는 기능이 빈약해도 리치 에디트도 엄연히 워드 프로세서에 준하는 물건이니.. 얘는 단독으로 덩치가 굉장히 컸다. 공용 컨트롤 comctl32 패밀리의 멤버 형태로 제공되지 않았으며, 자신만의 전용 DLL과 버전업 체계를 갖추고 있다. 게다가 역사적으로 형태도 몇 차례 바뀌었다.
초창기 1.0은 riched32.dll이었고 윈도우의 공식 클래스 이름은 RICHEDIT였다. Windows 95와 함께 제공되었다.
그러다가 리치 에디트 2.0은 riched20.dll로 바뀌고 클래스 이름도 RichEdit20A 또는 W로 바뀌었다. 짐작하다시피 이때 유니코드가 최초로 지원되기 시작했고 다단계 undo도 지원되기 시작했다. 저 둘은 텍스트 에디터를 밑바닥부터 다시 만들어야 할 명분이 충분한 대공사가 맞다. 얘는 Windows 98과 함께 제공되었다.
나중에 Windows 2000/ME 타이밍 때는 3.0이 나왔는데, 3.0은 프로그래머의 입장에서 API가 바뀐 것이 전혀 없이 2.0을 상위 호환 명목으로 아주 부드럽고 자연스럽게 대체하게 됐다. 그리고 기존 1.0의 생성 요청조차도 그냥 3.0 엔진을 기반으로 호환성 모드로 동작하게 바뀌었다.
지금도 Windows의 system32 디렉터리를 가 보면 riched32.dll은 있긴 하지만 크기가 달랑 10KB밖에 되지 않는다. 실질적인 기능은 riched20.dll에서 수행되기 때문이다.
그랬는데 수 년 뒤, Windows XP sp1에서 리치 에디트 컨트롤은 형태가 또 바뀌었다. 목적은 TSF를 지원하기 위해서다. 얘 역시 내부의 모든 동작을 저 스펙에 맞게 수정해야 하는 엄청난 대공사였다.
얘는 모듈 이름이 영 생소한 msftedit.dll로 바뀌고, 버전도 공식적으로는 4.1이지만 클래스 이름은 RICHEDIT50W이라고 정해졌다. 어디서는 4.1이었다가 저기서는 5라고 표기하면서 혼란스럽다.
리치 에디트 컨트롤은 이렇게 두 번 격변을 거친 뒤에는 딱히 단절적인 변화 없이 지금까지 전해져 오고 있다. MFC에서는 리치 에디트 컨트롤을 초기화하는 AfxInitRichEdit() 계열의 전용 함수를 두고 있다. 2와 5가 붙은 버전도 있다.
그래도 일반적인 대화상자에서 리치 에디트 컨트롤을 집어넣어야 할 일은 그리 많지는 않을 것이며, 굳이 넣더라도 서식이 동원된 문서나 데이터를 “읽기 전용”으로 표시하기 위해서일 것이다.
Visual C++ IDE의 리소스 에디터가 지원하는 것은 버전 2 (사실상 3)에 머물러 있다. 굳이 버전 5를 집어넣으려면 custom control을 삽입해서 RICHEDIT50W를 수동으로 지정해야 한다.
그래도 Visual C++ 201x대의 최신 MFC는 CRichEditView 클래스에 대해 버전 5를 집어넣게 돼 있다. 하긴 4.1인지 5인지 최신 버전이 나온 지가 이미 10년이 넘었는데, 진작에 지원했어야지..
5.0의 가장 큰 존재 의의라 할 수 있는 TSF를 사용하기 위해서는 SES_USECTF 스타일을 지정하는 코드 단 한 줄만을 실행해 주면 된다. SendMessage(hRichEdit, EM_SETEDITSTYLE, SES_USECTF, SES_USECTF)
글쎄, TSF를 제대로 지원하려면 원래는 응용 프로그램에서 COM을 초기화하고 message loop에도 TSF 오브젝트에다가 선처리를 먼저 맡기는 등 해야 할 일이 많다. 이 때문에 날개셋 편집기는 TSF 사용 여부 옵션을 변경한 것이 프로그램을 재시작해야만 적용된다. 그걸 다 무시하고 일반 앱에서 이렇게 간단하게 TSF 지원이 정말 가능한지는 잘 모르겠다.
이걸 해 주면 리치 에디트 컨트롤에서 IME에서 단어 단위 한자 변환이 되며, 날개셋의 경우 다른 고급 특수 기능들도 모두 아무 제약 없이 사용할 수 있다.
 |  |
그 밖에 리치 에디트 컨트롤이 사용 측면에서 기존 에디트 컨트롤과 다른 점은 다음과 같다.
- 기존 에디트 컨트롤은 단일 배열 버퍼 기반이지만 리치 에디트는 문자열의 연결 리스트 기반으로, 처음부터 대규모 텍스트 편집에 최적화돼 있다. Windows 9x 시절에는 기존 컨트롤은 편집 가능한 텍스트의 크기도 64K 남짓으로 제한돼 있었지만 리치는 그런 한계가 없다.
- 리치 에디트 컨트롤은 기존 에디트 컨트롤과 달리, 자체적인 우클릭 메뉴가 없다. 우클릭 이벤트 때 할 일은 전적으로 부모 윈도우의 동작에 달려 있다.
- 기존 에디트 컨트롤은 텍스트의 드래그 드롭을 지원하지 않지만 리치는 지원한다.
- 기존 컨트롤은 블록이 언제나 짙은 파랑 highlight색으로만 표시된다. 그러나 리치 에디트는 그냥 반전색 또는 요즘 유행인 옅은 파랑으로 표시되며, 사용자 정의를 할 수 있다.
- 리치는 트리플 클릭(3연타...)으로 텍스트 전체를 선택할 수 있다. 기존 컨트롤은 그런 동작이 지원되지 않는다.
서로 지향하는 목표와 설계 방식이 생각보다 많이 차이가 난다는 걸 알 수 있다. 에디트 컨트롤을 두 종류 따로 만들 만도 하다.
리치 에디트 컨트롤의 다른 사용법들이야 기존 문서를 참고하면 되니 여기서 다룰 필요가 없다. 이 글에서는 역사, TSF 지원, 그리고 한 가지 더.. 중요하지만 다른 문서에서 다루지 않는 특성을 하나 더 다룬 뒤 글을 맺도록 하겠다. 바로.. 경계 테두리이다.
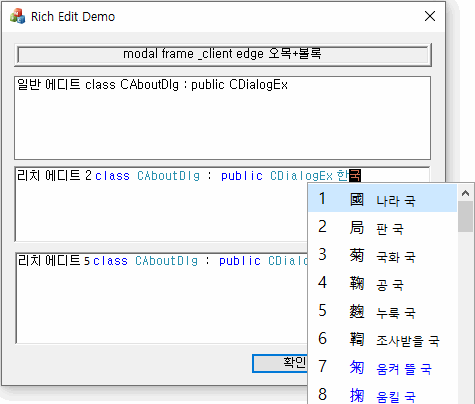
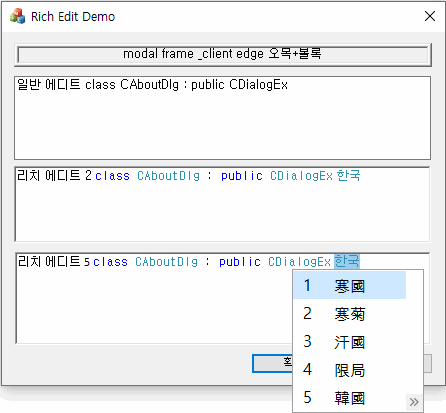
리치 에디트 컨트롤은 공용 컨트롤 계열의 물건이 아니다. 그래서 그런지 공용 컨트롤 6 테마가 적용되었더라도 경계 테두리가 일반 에디트 컨트롤 같은 새끈한 모양으로 안 나오고 그냥 고전 테마의 투박한 모양으로 그려진다. 위의 스크린샷에서 보는 바와 같다. 어찌 된 영문일까? 답을 말하자면 상황이 좀 복잡하다.
윈도우 스타일 중에는 WS_BORDER (검고 가는 테두리), WS_DLGFRAME (버튼 같은 볼록 두툼한 테두리), WS_EX_CLIENTEDGE (오목 두툼한 테두리), WS_EX_STATICEDGE (오목 가는 테두리) 처럼 운영체제 차원에서 윈도우 주변에 non-client 영역을 확보하고 테두리를 치는 스타일들이 몇 가지 있다.
여기서 볼록이라 함은 좌측과 상단은 밝은 계열, 우측과 하단은 어두운 색인 테두리를 말하며, 오목은 순서가 그 반대이다. WS_DLGFRAME(볼록 테두리)을 지정하면 대부분의 다른 테두리 스타일들이 무시되지만, 그래도 WS_EX_CLIENTEDGE와 동시 지정은 가능하다. 그러면 꽤 흥미로운 테두리가 만들어진다. 이 역시 위의 스크린샷에서 묘사된 바와 같다.
이 테두리가 그려지는 모양은 테마의 적용 여부와 무관하게 언제나 동일하다. 그렇기 때문에 특별히 하는 일이 없다면 원래는 리치 에디트 컨트롤처럼 투박하게 그려지는 게 맞다.
테마가 적용된 공용 컨트롤 6들은 WS_EX_CLIENTEDGE(오목하고 두툼한 테두리)가 존재할 경우, WM_NCPAINT 메시지를 자체 처리하여 DrawThemeBackgroundEx 같은 theme API를 호출해서 테두리를 그린다. 자세히 보면 심지어 포커스를 받았을 때와 그렇지 않을 때 테두리 색깔이 달라지는 것도 확인할 수 있다. 하지만 리치 에디트 컨트롤은 저런 처리를 안 하기 때문에 테두리가 고전 테마 모양 그대로인 것이다.
그러니 컨트롤 자신이 테두리를 제대로 그리지 않으면 응용 프로그램이 강제로 그려 주는 수밖에.. 리치 에디트 컨트롤의 테두리 미관을 개선하려면 해당 컨트롤을 서브클래싱 해서 WM_NCPAINT 처리를 직접 하는 것 말고는 선택의 여지가 없다. 이것도 뭔가 운영체제 차원에서의 자동화 절차가 필요해 보인다.
본인이 이런 테두리 그리기와 관련해서 알게 된 굉장히 놀라운 사실이 있다.
오늘날 Windows에서 대화상자를 꺼내는 DialogBox, CreateDialog 계열 함수들은 대화상자 리소스에서 WS_BORDER이라고 지정된 스타일을 무시한다. 그걸 무조건 WS_EX_CLIENTEDGE로 치환해 버린다.
오목하고 두툼한 테두리는 대화상자 내부에서 사용자가 뭔가 아이템을 선택하고 문자를 입력하는 '작업 공간'을 나타내는 시각 피드백이다. 그에 비해 볼록/오목 효과가 없이 그냥 flat한 검정 단색 테두리(WS_BORDER)는 대화상자에 회색 입체 효과가 없던 Windows 3.x 시절 비주얼의 잔재로 여겨진 것이다.
어쩐지 옛날에도 WS_BORDER이랑 WS_EX_CLIENTEDGE가 차이가 없는 것 같았는데 그땐 그저 그러려니 하고 넘겼었다. 관계가 정확하게 저렇다는 걸 본인도 이제야 직접 조사해 보고 알게 됐다. 대부분의 경우 WS_BORDER는 그냥 WS_EX_CLIENTEDGE로 포워딩 되는 호환성 옵션으로 전락했다.
다만, 테마가 적용된 뒤에는 윈도우의 외형이 다시 옛날 같은 flat 스타일로 돌아간지라.. 검정 단색 테두리가 회색 단색 테두리로 바뀌었을 뿐이다. 그래서 볼록/오목 효과가 역으로 오래되고 촌스럽게 보이는 촌극이 빚어져 있다. 역사는 이런 식으로 돌고 돈다! =_=;;;
이상이다. 그러고 보니 리치 에디트는 최신 버전인 5(또는 4.1)에 대해 공용 컨트롤 6처럼 side-by-side assembly를 적용하는 게 충분히 일리가 있음에도 불구하고 전혀 그런 조치가 취해지지 않았다. 그렇기 때문에 얘는 사용자가 DLL과 윈도우 클래스 이름을 달리하는 원시적인 방법으로 버전 구분을 해야 한다.
즉, 리치 에디트는 Windows XP와 동시대에 개발됐음에도 불구하고 같이 개발되던 관련 신기술 두 종류와는 완전히 열외된 셈이다. (테두리 테마, SxS assembly) 아쉬운 대목이 아닐 수 없다. 리치 에디트 팀의 관심사에 든 XP의 신기술은 오로지 TSF뿐이었다.
본인이 개발한 날개셋 한글 입력기에도 자체 에디트 컨트롤과 텍스트 에디터가 있다. 먼 옛날에 2.x에서 3.0으로 넘어갈 때 프로그램이 내부 구조를 다 뜯어고치고 완전히 새로 개발되었는데, 이때 유니코드 기반, 다단계 undo, 그리고 TSF까지.. 리치 에디트 컨트롤이 1에서 2, 3에서 5로 갈 때의 공사를 몽땅 진행했다. 리치 에디트와 비슷하다면 비슷한 전철을 밟은 셈이다.
Posted by 사무엘