컴퓨터 화면에 그려진 어떤 물건(주로 사각형 모양)의 경계 테두리에다 마우스를 갖다대면 포인터가 그 경계 테두리와 수직인 방향의 화살표로 변한다. 그 상태에서 마우스를 클릭하여 끌면, 그 물건의 크기를 마우스 포인터가 움직이는 방향으로 변경할 수 있다.
이것은 GUI에서 매우 흔히 볼 수 있는 기능이다. 특히 크기 조절 가능한 창--운영체제가 정식으로 제공하는 GUI 구성요소--의 경우 이런 기능은 운영체제가 non-client 영역에서 알아서 자동으로 처리해 준다.
그런 창이야 운영체제가 처리를 알아서 해 주지만, 대화상자 내부의 임의의 영역에 대해서, 혹은 클라이언트 영역에 내가 그려 주는 임의의 객체에 대해서 이런 처리를 구현하려면 어떻해야 할까? 뭔가 공통된 패턴의 알고리즘을 처리해야 할 텐데 코딩량이 적지는 않으며 왠지 귀찮고 번거로워 보인다.
크기 조절 내지 화면 분할 UI와 관련해서는 다음과 같은 여러 상황을 생각할 수 있다.
1. 한 윈도우 내부에 그려지는 개체의 크기 조절
2차원 벡터 그래픽 프로그램 내지 RAD 툴의 폼 에디터가 정확하게 여기에 속한다. 요즘은 워드 프로세서도 자체적인 벡터 그래픽이나 하다못해 OLE 개체라도 취급하니 마우스를 이용한 크기 조절 기능을 제공해야 한다. 개체를 클릭하면 8군데의 앵커 사각형이 생기며, 경계 아무 곳이라기보다는 그 앵커 사각형을 드래그했을 때 크기 조절이 된다. 다른 곳을 드래그하면 크기 조절이 아니라 이동이 되고. 그리고 요즘 MS 오피스 제품은 회전용 앵커까지 덤으로 제공한다.
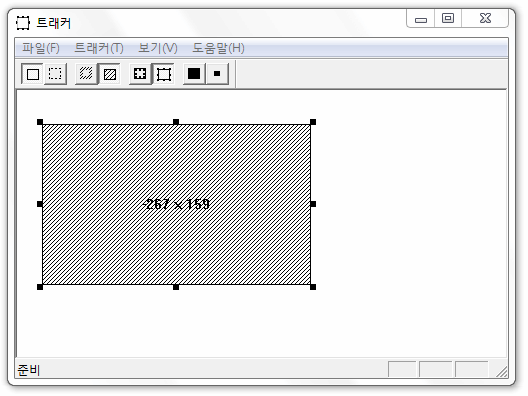
비주얼 C++에는 CRectTracker라는 고전적인 클래스가 있어서 마우스 드래그로 임의의 사각형 영역을 화면에다 그리고 마우스가 클릭됐을 때의 일체의 처리를 알아서 해 준다. 이것만 쓸 줄 알아도 상당히 편리한데, 본인은 지금까지 그런 분야의 프로그램을 개발할 일이 없다 보니 실제로 써 본 적은 전혀 없다. 이런 게 있다는 것만 안다.
그리고, 지금도 있나 모르겠다만, 비주얼 C++에는 DrawCli라고 딱 개체 기반 벡터 드로잉과 드래그 드롭, 크기 조절과 이동을 모두 시연해 놓은 걸출한 예제 프로그램이 있다.
학창 시절 나의 친구였던 <비주얼 C++ 완벽 가이드>(김 용성)에도 '트래커'라는 예제 프로그램이 있으니 참고할 것.
참고로, 저렇게 테두리를 그리고 사각형 안의 내용물은 대각선 사선으로 칠하는 건.. embed된 OLE 개체를 외부 프로그램이 수정 중일 때 클라이언트 프로그램이 표시하는 표준 모양이기도 하다.
2. 부모 윈도우가 자식 윈도우를 동적으로 분할하고 관리
규모깨나 좀 있는 문서 편집 프로그램을 보면, view를 분할하는 기능이 있다. 이것은 한 문서 컨텐츠에 대해 뷰 윈도우를 여러 개 둬서 한 컨텐츠를 여러 가지 다른 방식, 다른 위치를 표시할 수 있게 한다. 사용자의 입장에서 매우 편리한 기능이지만, 컨텐츠와 뷰 윈도우가 완전히 일심동체라고 전제하고 만들어져 버린 프로그램이라면 추후에 이러 기능을 추가하기가 쉽지 않을 것이다. MDI 프로그램이라면 아예 별도의 독립된 창을 만드는 기능도 있겠지만 SDI에서는 한 창을 분할하는 것만 가능하다.
이건.. 생각보다 만들기 어려운 기능이다. 경계(splitter) 부분을 마우스로 끌었을 때의 처리도 처리거니와--이를테면 XOR 연산으로 자취를 그렸다가 지우는 것도..--, 내가 무엇보다도 힘들겠다고 느끼는 건 스크롤 바를 자체적으로 따로 만들어서 관리하는 부분이다. 이게 무슨 뜻인지를 설명하자면 이렇다.
Windows 운영체제에는 어떤 윈도우가 자체적으로 스크롤 바를 가질 수 있고, 한편으로 스크롤 바 자체가 별도의 컨트롤로 존재할 수 있다.
윈도우가 자체적으로 갖는 native 스크롤 바는 당연히 운영체제가 모든 처리를 알아서 해 준다. 창의 크기가 바뀌어도 스크롤 바를 자동으로 우측(상하) 내지 하단(좌우)에 배치해 주고, 스크롤을 할 필요가 없어지면 알아서 스크롤 바가 없어지고 그 영역까지 클라이언트 영역이 확대된다.
그러나 splitter가 존재하는 view를 보면, 스크롤 바가 있던 자리의 구석 일부에 창을 분할시키는 앵커가 자리잡고 있다. 이건 native 스크롤 바로 구현 가능하지 않기 때문에 스크롤 바 컨트롤을 따로 만들어서 앵커 밑이나 옆에다 두고, 스크롤 바의 위치· 크기와 관련된 모든 처리를 수동으로 해야 한다. 이 얼마나 복잡하고 손이 많이 갈까? 그러니 MFC가 CSplitterWnd라는 클래스에다 전부 구현해 놨다.
MFC AppWizard에서 '뷰 분할 기능 사용'을 체크하면, 프레임 윈도우는 밑에다 저 splitter 윈도우를 생성하고 걔가 또 자기 밑에다 어떤 view를 생성할지를 따로 지정해 준다. 다시 말해 프레임 윈도우와 view 사이에 splitter라는 중간 계층 윈도우가 하나 또 생긴다는 것이다. 그리고 요놈이 스크롤 바와 앵커의 위치를 관리하고 앵커 드래그에 대한 처리도 담당한다.
내가 MFC의 splitter 윈도우에 대해 꽤 놀란 것은, 분할을 2개씩뿐만 아니라 그 이상도 얼마든지 할 수 있다는 점이다. 위의 그림처럼 가로 3개, 세로 3개를 분할해서 무려 9개나 되는 view 윈도우를 뻥튀기시킬 수도 있다. 가로와 세로의 splitter 중 어느 것 하나의 위치가 바뀌었을 때, 혹은 창 전체의 크기가 바뀌었을 때 splitter가 총체적으로 조율하고 해야 할 일의 양도 그에 비례해서 많아질 것이다.
그런데 각각의 창들이 다 독자적인 가로· 세로 스크롤 바를 갖는 건 아니고.. 위의 스크린샷에 보듯이 한 column에 해당하는 view들은 가로 스크롤 바를 하나 다같이 공유한다. 그리고 한 row에 해당하는 view들은 세로 스크롤 바를 다같이 공유한다. 특이한 점임.
3. 부모 윈도우가 자식 윈도우를 '정적'으로 분할하고 관리
위의 2번과 마찬가지로 부모 윈도우가 자식 윈도우의 분할을 관리하는 경우이긴 한데, 위처럼 성격이 비슷한 윈도우가 아니라 별개의 윈도우를 고정적으로 관리하는 경우를 추가적으로 생각할 수 있다. 처음엔 1개였다가 2개 이상으로 자유자재로 분할되는 건 아니기 때문에, 스크롤 바나 앵커 같은 건 없다.
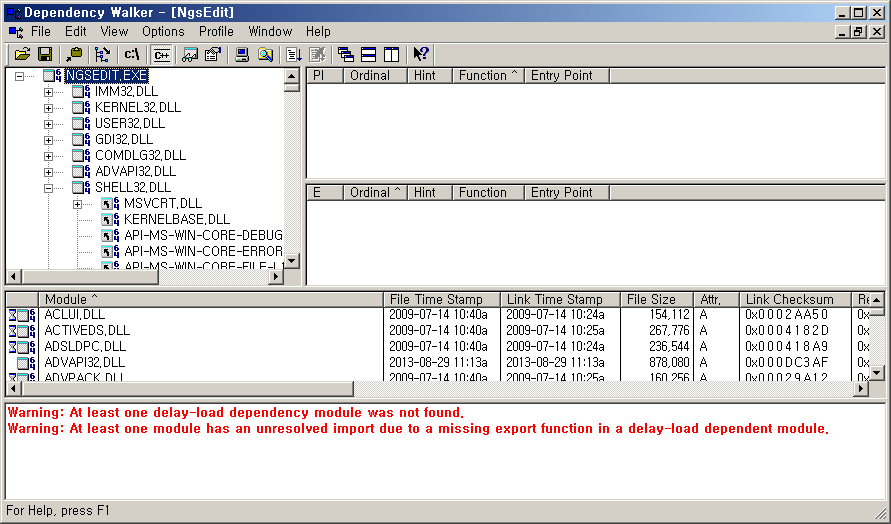
왼쪽에 트리 컨트롤, 오른쪽에 리스트 컨트롤을 두고 가로로 크기 조절이 가능한 탐색기 같은 프로그램도 좋은 예이고, 그보다 좀 더 복잡한 경우로는 개발자들의 친구인 Dependency Walker가 있다.
Spy++ 같은 프로그램으로 들여다보면, 창 구조가 생각보다 복잡하다는 걸 알 수 있다.
가장 겉에 있는 창은 화면을 상하로 나눈다. 위에 있는 창은 화면을 또 좌우로 나눠서 왼쪽은 모듈 트리 구조가 나오며, 오른쪽은 또 상하로 나누어서 각각 이 모듈이 import하는 심벌들, 그리고 대상 모듈이 export 하는 전체 심벌들이 표시된다.
한편, 아래의 화면은 또 상하로 나뉘어서 위에는 전체 모듈 리스트가 있고 아래에는 메시지 log가 있다.
즉, 한 윈도우에 여러 개의 컨트롤들이 sibling 관계로 대등하게 늘어서 있는 게 아니라, 또 분할 윈도우가 있고 그 아래에 또 분할 윈도우가 자식 윈도우로 있는 형태다. 한 분할 윈도우는 언제나 좌우로든 상하로든 2개의 윈도우만을 담당한다.
이렇게 이분법적으로 접근하면, 제아무리 복잡하게 화면이 좌우 상하로 분할되어 있는 창이라 해도 전체 크기가 바뀌었다거나 할 때 자기가 맡은 두 개의 창만 비율 분배를 잘 하고 나머지는 자가반복적인 재귀 처리에 맡기면 되니 문제가 단순해진다는 장점이 있다.
저런 윈도우가 활용의 자유도가 더욱 올라간다면 아예 별도의 창으로 분리하거나 docking까지 가능해진다. Visual Studio의 각종 보조 윈도우들처럼 말이다. 그건 우리 같은 평범한 프로그래머가 밑바닥부터 할 짓이 못 되며, 이미 있는 GUI 라이브러리의 사용법을 익히는 것만으로도 충분할 것이다. MFC 없이 Windows API만으로 docking toolbar를 구현한 소스를 외국 사이트에서 본 적이 있는데, 가히 근성이 느껴졌다.
사용자 인터페이스라는 건 컴퓨터로 하여금 의미 있는 작업을 하게 만드는 실질적인 알고리즘이 아니다. 없던 걸 처음 시도하여 만드는 게 아닌 이상, 베끼기만 하느라 시간 낭비할 필요는 없을 것이다.
4. 대등한 위상의 윈도우끼리 분할 관리를 해야 하는 경우
어휴, 글을 이렇게 길게 쓸 생각은 없었는데... 마지막 아이템도 언급을 안 할 수가 없구나. -_-;;
자, 지금까지 얘기한 것들을 정리하자면 1번은 그냥 한 윈도우 내부에서 그리기를 하는 것뿐이며, 2번과 3번은 부모 윈도우가 자식 윈도우들의 공간 관리를 하는 경우를 특별히 MFC의 document-view 아키텍처의 예를 들어 소개한 것이다.
그러나 실무에서는 그것만이 전부가 아니다. 대화상자처럼 document-view 아키텍처가 적용되지 않는 창에 대해서도 수평/수직 splitter 같은 물건을 만들어야 할 때가 있다.
예를 들어, <날개셋> 제어판 같은 경우, '분야'를 나타내는 왼쪽의 트리 컨트롤과, 오른쪽의 여타 컨트롤들 사이에 수직 splitter를 둬서, 트리 컨트롤의 폭을 좀 더 넓힌다거나 반대로 좁히는 경우를 생각할 수 있다.
이 경우 splitter는 여타 컨트롤들과 마찬가지로 대화상자 안에 존재하는 여러 자식 윈도우의 하나일 뿐이지 나머지 컨트롤들을 모두 통솔하는 부모 윈도우의 지위는 아니게 된다. Spy++로 들여다보면, 가로나 세로로 길쭉한 고유한 splitter 윈도우가 잡히는 걸 볼 수 있다.
이런 상황에 대해서는 MFC는 딱히 제공해 주는 있는 클래스가 없다. codeguru 같은 데서 splitter dialog 정도로 검색해 보면 예제 소스나 관련 튜토리얼들이 쭉 나온다. 예전에 아주 괜찮은 코드를 하나 구해서 유용하게 쓴 적이 있었는데 지금 다시 검색하려니까 못 찾겠다.
이런 일을 하는 범용적인 클래스를 만들 때 염두에 둬야 하는 사항으로는, 좌우나 상하든 보장해 줘야 하는 최소 크기를 인자로 받아야 할 것이고, 좌우 상하 중 한쪽에다 뒀으면 하는 윈도우를 배열 같은 자료구조로 관리해야 한다. 윈도우 핸들이 아닌 ID로 받으면.. ID로부터 실제 핸들값(HWND)을 얻어야 하는 번거로움이 있지만, 그 컨트롤이 중간에 재생성된다거나 해도 여전히 식별이 가능하기 때문에 범용성이 좀 더 향상된다.
다른 splitter조차 자기의 크기 조절에 영향을 받게 하고 WM_SIZE 메시지에 반응한다면, 아까 Dependency Walker 같은 복잡다단 splitter도 얼마든지 구현 가능하다.
splitter를 구현하려면 당장 크기를 조절하는 것 처리는 둘째치고라도, 창의 크기가 바뀌었을 때 각 분할 화면들의 공간 배분을 어떻게 할지 같은 것도 생각해야 하니 여러 모로 골치가 아픈 건 사실이다.
끝으로 언급하고 싶은 이슈가 있다. 1~4번들은 다 마우스가 클릭되었을 때 캡처를 잡고 마우스 움직임을 추적하다가 버튼이 떼졌을 때 마무리 처리를 한다는 공통점이 있다.
이 경우, WM_LBUTTONDOWN, WM_MOUSEMOVE, WM_LBUTTONUP을 모두 메시지 맵에다 등록하고 각 상황별 코드를 메시지 핸들러 함수에다 제각기 따로 작성하는 방법을 생각할 수 있지만..
좀 더 능숙한 프로그래머라면, 그런 드래그 드롭 처리 정도면 WM_LBUTTONDOWN에다가 아예 별도의 message loop을 만들어서 거기에다 WM_MOUSEMOVE와 WM_LBUTTONUP에 해당하는 코드를 다 집어넣는 방법을 선택한다. 한 함수에다가 한 기능에 대한 처리를 몰아서 넣는 게 훨씬 더 깔끔하기 때문이다.
Posted by 사무엘