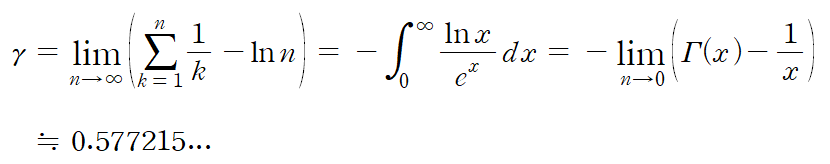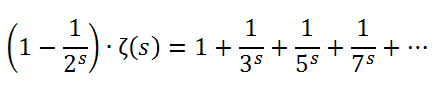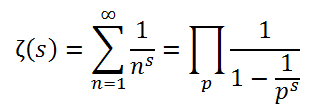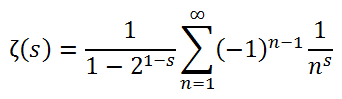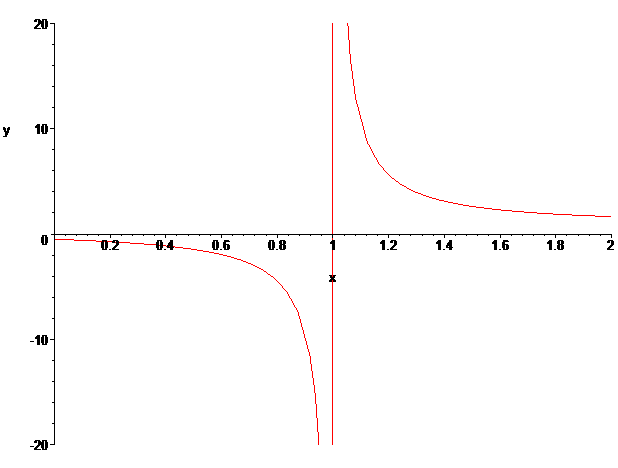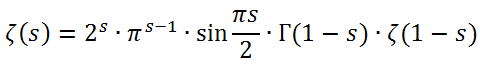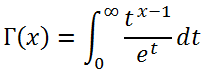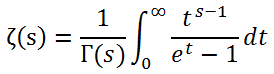18세기를 살았던 레온하르트 오일러가 인류 역사상 얼마나 충격과 공포 괴수 급의 천재 수학자였는지는 자연계· 이공계 맛을 조금이라도 본 사람이라면 모를 수가 없을 것이다. 본인 역시 이에 대해서 이 블로그에 글을 쓴 바 있다.
그의 여러 업적 중에서 자연수들의 거듭제곱의 역수의 무한합과 관련된 것들이 특히 주목할 만하다. 이걸 일반화해서 그냥 리만-제타 함수라고 하는데, 가령 2승에 해당하는 ζ(2) = 1/1 + 1/4 + 1/9 + 1/16 ...이런 식이다.
오일러는 천재적인 직관으로 ζ(2) = pi^2 / 6이 된다는 것을 최초로 발견했다. 그는 더 나아가 이런 무한합이 다음과 같이 모든 소수들을 후처리한 값들의 무한곱과 동치라는 것을 증명했으며...
(이런 식으로 3^s, 5^s, 7^s ... 순으로 몽땅 소거하는 것이 포인트)
2 같은 짝수 승일 때는 이 값이 언제나 원주율을 거듭제곱 및 유리수배 한 형태로 나온다는 것까지도 알아냈다.
자연수의 거듭제곱의 역수의 무한합에는 원주율도 들어있고 소수의 분포도 들어있고.. 가히 노다지가 가득했다. 괜히 난해한 문제가 아니었던 것이다.
한편으로 짝수가 아닌 홀수 승일 때는 저 함수값이 정확하게 무슨 의미가 있는 형태로 표현되는지 아직까지 아무도 모른다. 무리수인 것까지는 알려졌지만 초월수인지조차 아직 정확하게 증명되지 못했다. (심증상으로는 어차피 매우 높은 확률로 초월수일 것 같다만..) 지금까지 인류의 지성이 캐낸 것만 해도 노다지 급인데, 이 함수의 정체는 아직까지도 다 밝혀지지 못해 있다. 홀수 완전수도 그렇고 홀수에 뭔가 이상한 특성이 있기라도 한가 보다.
게다가 이것이 이야기의 끝이 아니다.
언뜻 보기에 ζ(x)는 x > 1일 때에만 유의미한 값을 가지며, x가 커질수록 함수값은 1에 한없이 가까워질 것이다. 그리고 x <= 1이면 얄짤없이 무한대로 발산이니 함수에 대해 논하는 것이 아무 의미가 없다.
가령, ζ(1) = 1 + 1/2 + 1/3+ 1/4 ...는 로그 스케일로나마 발산한다는 것이 잘 알려져 있고, ζ(0)이면 1+1+1+1+...이 될 것이다. ζ(-1)은 역수의 역수이니까 1+2+3+4+...가 되니 이 이상 더 따질 필요도 없다.
그럼에도 불구하고 이 함수는 사실 1을 제외한 다른 모든 수에 대해서 함수값이 정의된다. 아니, 실수를 넘어서 복소수에서까지 정의된다. 어찌 된 영문일까? '해석적 연속'(analytic continuation)이라는 개념을 통해서 정의역을 확장할 수 있기 때문이다.
수학이라는 학문은 이런 식으로 사고의 영역을 확장하면서 서로 다른 개념이 한데 연결되고, 추상화의 수준이 상승하고, 거기서 아름다움과 일치, 질서를 발견하는 식으로 발전해 왔다.
고등학교 수준에서 가장 먼저 발상의 전환을 경험하는 건 허수와 복소수이다. "제곱해서 -1이 되는 수라니, 세상에 그런 황당무계한 물건이 어디 있냐? 그걸 도대체 왜 정의하며 그게 무슨 의미가 있냐?"라고 처음엔 누구나 자연스럽게 생각할 수 있다. 아니, 그렇게 고집을 부리는 게 이전까지 수학 공부를 정상적으로 제대로 한 사람의 반응이다.
그런데 그 개념만 하나 도입하고 나니 이제는 뭐 4제곱해서 -1이 되는 수 이런 식으로 이상한 숫자를 또 만들 필요 없이, 복소수 범위에서 i만 동원함으로써 정수 계수 n차 방정식의 근 n개를 언제나 모두 기술할 수 있게 된다. (대수학의 기본 정리) 이게 대단하다는 것이다.
물론, i로도 모자라서 j, k 같은 괴상한 수를 추가한 삼원수 사원수 같은 확장 개념도 있긴 하지만, 그건 벡터· 행렬과 연계해서 다른 특수한 용도 때문에 쓰이는 것일 뿐, 대수 내지 해석학적인 필요 때문에 쓰이는 건 아니다.
다음으로 거듭제곱을 생각해 보자. 이걸 동일한 숫자를 n회 곱하는 식으로만 정의한다면 끽해야 정수 내지 유리수 승밖에 생각할 수 없다. 그러나 거듭제곱의 역함수 격인 로그가 미분 가능한 연속함수이며, 자연상수의 거듭제곱 e^x를 다항식 급수로 풀어 쓸 수도 있다. 더구나 e^(I*x) = cos(x) + I*sin(x)로 자연상수와 I가 복소평면에서 삼각함수와도 만나게 되었으니, 이제 거듭제곱을 정수와 유리수의 영역에만 한정해서 생각할 필요란 전혀 없을 것이다.
이런 식으로 a^x 정도가 아니라 x^x나 x!(팩토리얼)마저도 매끄러운 함수 형태로 그래프로 그릴 수 있다. 특히 팩토리얼의 경우 '감마 함수'라고 별도의 명칭까지 있고 말이다.
또한 x는 실수가 아닌 복소수로 확장해서 2^I, I^I 같은 것도 생각할 수 있다.
고등학교 수학에서는 음수 로그는 생각하지 않고 지냈지만, 복소수 범위에서는 로그 역시 정의역이 복소수로 확장 가능하다. base(밑)도 0이나 1만 아니면 다 된다. 오일러가 정립한 e^(Pi*I)+1=0 이 괜히 위대한 발상이 아닌 것이다.
그럼 리만-제타 함수의 정의역은 어떤 방식으로 확장할 수 있을까?
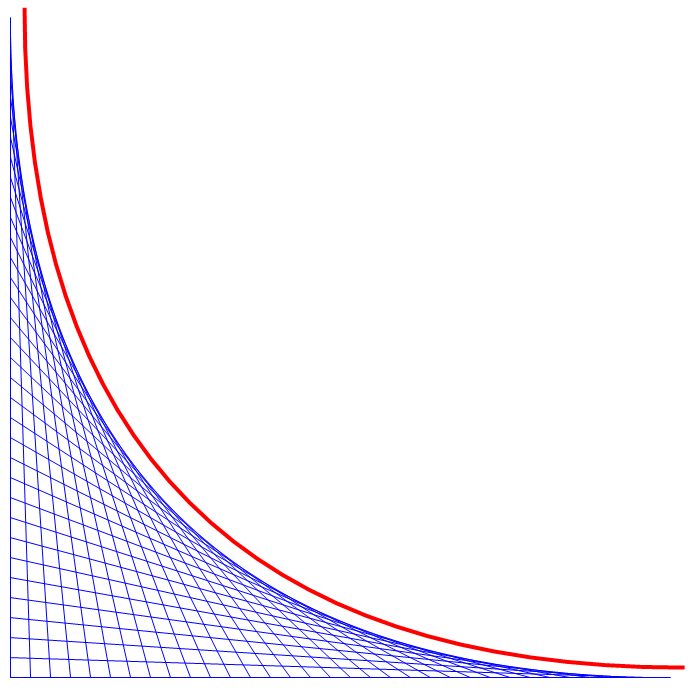
일단 무한합 함수를 다음과 같은 형태로 바꾸면.. >1에 대해서만 정의되던 기존 함수를 1을 제외한 >0에 대해서도 정의되게 범위를 조금 넓힐 수 있다.
앞에는 뭔가 등비수열의 무한합 같은 계수가 곱해졌고, 뒤에는 1+2+3+4... 덧셈 일색이던 것이 1-2+3-4+... 형태로 바뀌었다. (참고로, s=1일 때.. 1 -1/2 +1/3 - 1/4...는 ln(2)로 수렴하는 것으로 잘 알려져 있음.)
이렇게 식을 써 주면, s>1일 때는 아까와 결과가 동일하면서도 0<s<1일 때는 음의 무한대로 발산하는 형태로 함수값이 추가로 정의되게 된다.
즉, 이 함수는 1에 대해서 좌극한과 우극한의 값이 서로 다르게 된다.
뭔가 (1, 1)이 중심인 반비례 그래프처럼 생겼지만 실제로 그렇지는 않다. 가령, ζ(4/5)는 -4.4375...이지만 -ζ(6/5)-1은 -4.5915...로 값이 서로 미묘하게 다르다.
그럼 0과 음수에 대해서는 어떻게 정의하느냐 하면.. 더 복잡하고 난해한 개념을 동원해야 한다.
구체적인 유도 과정은 본인도 다 모르겠고 시간과 지면이 부족하니 생략하지만.. 리만-제타 함수는 이미 정의된 함수값으로부터 다른 구간의 함수값을 해석적으로 유추할 수 있는 '함수 방정식'이 이렇게 정의되어 있다.
얘를 0과 음수에 대해서도 적용하면 된다는 것이다.
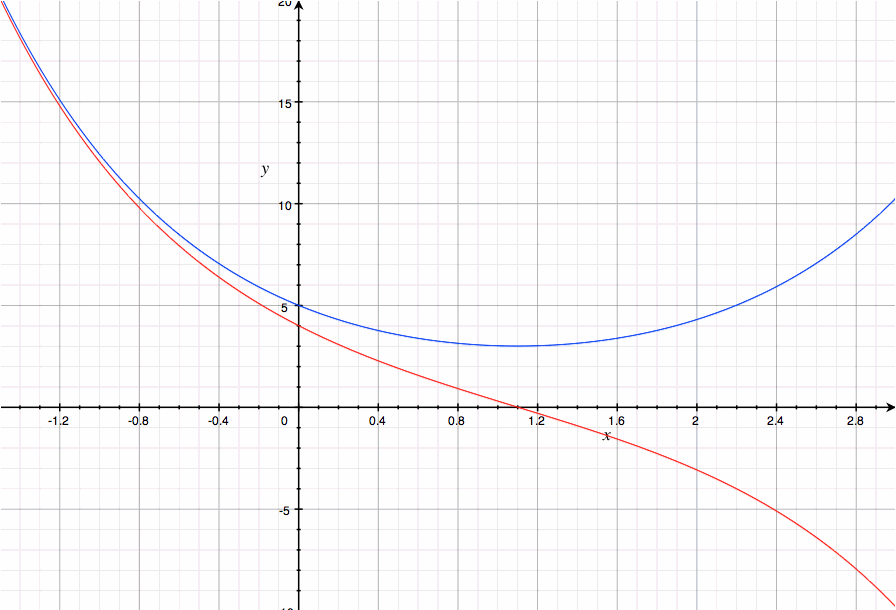
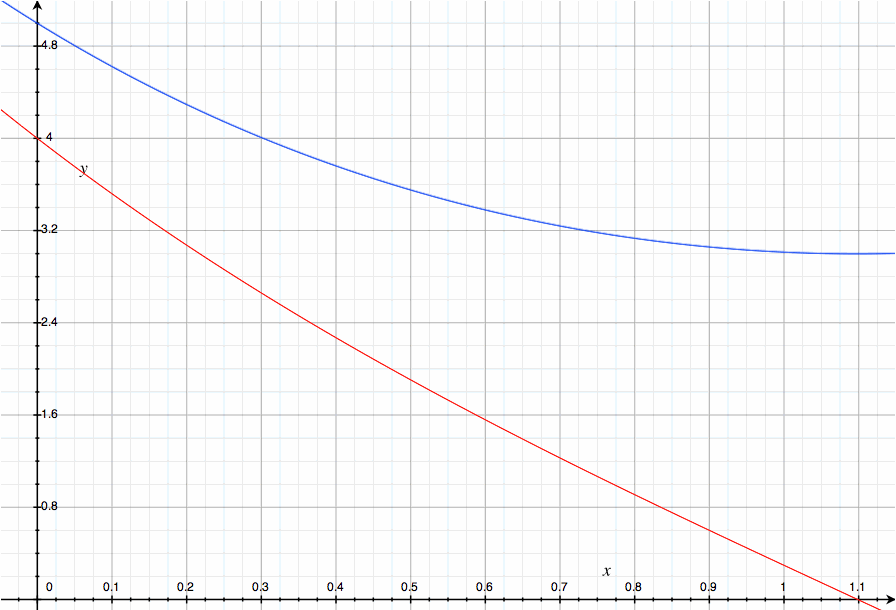
여기서 감마 함수 Γ(x)는 바로 (x-1)!의 해석적 확장 버전이며, 다음과 같이 정의된다.
x^n / e^x를 0부터 무한대까지 적분한 값이 n!이라니, 신기하기 그지없다.
더 신기한 것은, 리만-제타 함수도 기존의 >1 구간에 대해서는 감마 함수와 매우 유사한 형태로 이렇게 정의할 수 있다는 점이다.
저 복잡한 수식들이 논리적으로 서로 다 맞아떨어진다는 사실을 리만이라는 사람이 발견했다. 자연수의 거듭제곱의 역수 무한합이 도대체 몇 가지나 서로 다른 방식으로 표현되나 모르겠다..!
사실, 리만-제타라는 함수 이름도 저 사람이 정의역을 해석적으로 완전하고 깔끔하게 확장된 뒤에 붙은 이름이다. 그 전에 직관적으로 생각하기 쉬운 1보다 큰 실수 버전은 그냥 '제타 함수'였다.
리만-제타 함수는 음의 짝수에 대해서는 모두 0이 나온다. 함수 방정식에서 sin(Pi*x/2) 부분이 -180도의 배수가 걸리고 0이 돼 버리기 때문이다.
그럼 양의 짝수는 괜찮은가 하면.. 괜찮다. 저 함수 방정식에 포함된 감마 함수라는 놈은 음의 정수가 걸리면 무한대로 발산하며(제타 함수에서 원래 양의 정수가 들어왔을 때), 이 경우 함수 방정식의 값은 극한 형태로 구해야 하기 때문이다. 0과 무한대의 곱 형태의 극한은 원래 제타 함수의 값 형태로 나올 수가 있다.
비슷한 맥락에서 ζ(0)의 값을 구할 때도 극한을 동원해야 한다. 함수 방정식에 따르면 ζ(1-0) = ζ(1)을 동원해야 하는데 리만-제타 함수는 원래 1에서 값이 정의되지 않기 때문이다. 상황이 약간 까다롭다.
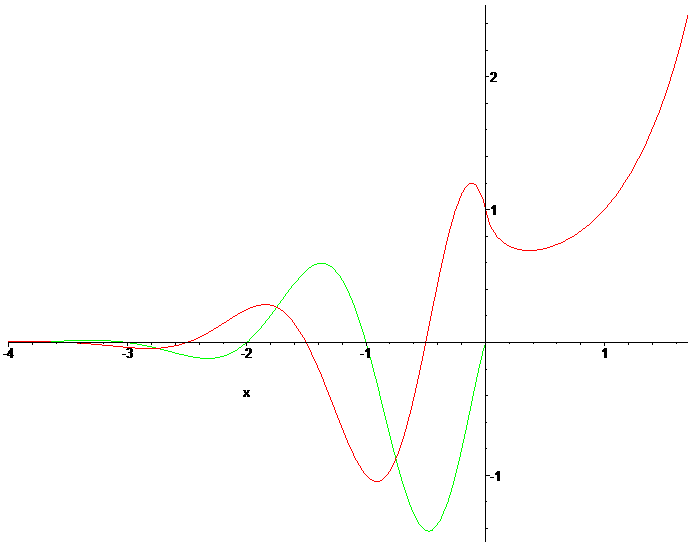
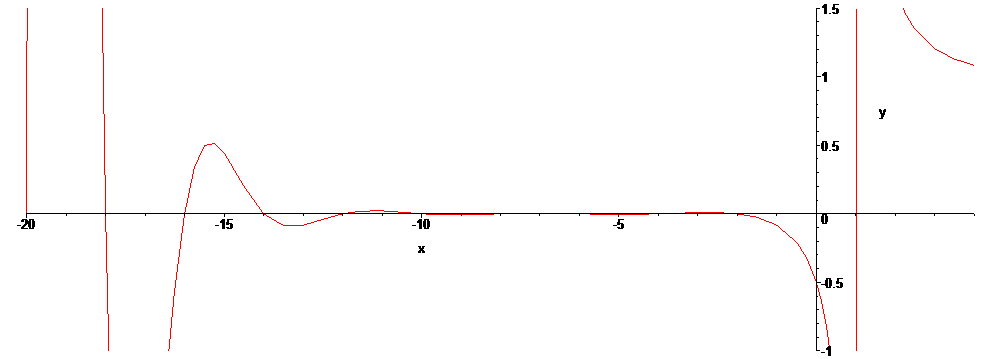
이런 우여곡절을 거치고 나면 리만-제타 함수의 음수 구간은 값이 상하로 진동하는데, 그 진동의 폭이 0에서 멀어질수록 급격히 커진다. 그래프의 모양이 얼마나 제멋대로인지 -20부터 4까지의 그래프를 그려 보면 다음과 같다.
그럼 리만-제타 함수의 0 이하 음수 구간은 수학적으로 도대체 무슨 의미가 있는가?
이것은 일명 '라마누잔 합'과 직통으로 연결된다. 20세기 초 인도의 천재 수학자 라마누잔의 이름에서 딴 명칭이다.
1+2+3+4... 무한합이 무한대도 아니고 -1/12라는 웃기는 짬뽕 같은 소리를 들어 보신 적 있나 모르겠다. 비슷한 논리로 1+1+1+1...은 -1/2라고 한다.
이건 0으로 나눗셈을 슬쩍 해 놓고는 "모든 수는 0과 같다", "0은 2와 같다" 같은 paradox 궤변· 유체이탈 화법을 늘어놓은 게 아니라, 무한급수의 합에 대한 정의 자체를 달리함으로써 도출 가능한 결론일 뿐이다.
실제로 모든 수를 0승 해서 1로 만든 것과 같은 ζ(0)의 값은 -1/2이며, 모든 자연수를 그대로 무한히 더한 것과 같은 ζ(-1)의 값이 -1/12이다.
리만-제타 함수와 직접적인 관계가 있는 수열은 아니지만 1+2+4+8+...의 무한합은 이런 체계에서는 -1이다. 자기 자신 s에 대해서 s = 1+2s가 성립되므로, s=-1이 된다는 식이다.
무한히 더하기만 하는 것 말고 더했다 빼기를 반복하는 1-2+3-4+5 ... 교대 무한합은 라마누잔 합에 따르면 등비수열의 무한합을 예외적으로 적용하는 방식으로 구해서 1/4가 된다.
1-1+1-1+1-1...의 교대 무한합은 1/2이다. 이건 1과 -1의 평균 같으니 그나마 좀 직관적으로 들린다.;;;
이들의 구체적인 근거와 계산 내역, 배경 원리는 이 자리에서는 역시 언급을 생략하겠다.;;
이거 무슨 고전 역학만 파다가 갑자기 양자역학이고 상대성 이론이고 하는 분야로 넘어간 듯한 느낌이다. 오일러가 뉴턴이라면 리만은 아인슈타인 정도? 진짜 그런 관계인 것 같다.
혹은 데카르트 좌표계와 유클리드 기하학만 열심히 파다가 갑자기 구면 같은 다른 기하학으로 넘어간 것 같은 느낌이다. (삼각형 세 각의 합이 180도가 아닐 수도 있는..)
무한이라는 개념이 이래서 다루기가 까다롭다. 뭐 하나 까딱 뒤틀면 별 희한한 등식이 다 나오기 때문이다.
0.99999...를 1과 동급으로 만들어 주는 것이 무한이며 그 새 발의 피 같은 소수의 역수들의 합을 발산시켜 주는 것도 '무한'이다. 그런데 한편으로 무한도 다 같은 무한이 아니기 때문에 자연수 전체의 개수보다 0~1 사이의 실수가 훨씬 더 큰 무한이라고 여겨진다.
아무튼 리만-제타 함수를 완전히 확장하고 나니 양수 구간에서는 오일러가 발견했던 그 어마어마한 의미가 담겨 나오고, 음수에서는 또 저런 신세계가 펼쳐지면서 한편으로 1을 제외한 전구간에서 저런 정교한 수학적 질서가 다 충족되었다.
그런데 수학자들의 욕심은 여기서 그치지 않고 이 함수를 복소수 구간에서까지 써먹을 생각을 하게 되었다. 당연히 얘의 저변에 있는 감마 함수, 삼각함수 등등도 전부 복소수 범위에서 값이 정의되어 있어야 할 것이다.
자 그럼 여기서.. ζ(x) = 0을 만족하는 근은 얼마나 있을까?
일단 양의 실수 중에는 그 정의상 존재하지 않는다. 그리고 음수 중에는 아까 말했던 짝수들이 모두 함수값을 0으로 만든다. 이들은 그냥 자명한, 중요하지 않은 trivial한 근이다.
그런데 문제는 이 함수는 복소수 범위에서 다른 근도 갖는다는 것이다. 이것은 유의미한, non-trivial한 근이다.
구하기가 무진장 어렵긴 하겠지만 베른하르트 리만은 0에 가까이 있는 것부터 시작해 근을 4개 정도 찾아내 봤다. 그런데 여기서 신기한 공통점을 발견했으며, 그는 다음과 같은 주장을 하기에 이르렀다.
"ζ(x) = 0을 만족하는 자명하지 않은 복소수 근 x들은 실수부가 모두 1/2일 것이다."
그리고 우리는 이것을 리만 가설이라고 한다.
리만-제타 함수의 유의미한 근은 무수히 많이 존재하는데, 첫 몇 개가 다음 사이트에 올라와 있다. 실수부는 1/2이고 허수부가 저런 값인 복소수들 근이라는 얘기이다. 즉, 1/2 + 14.134725...I 부터 시작해서 1/2 + 21.02203963..I , 25.010857...I 등이다.
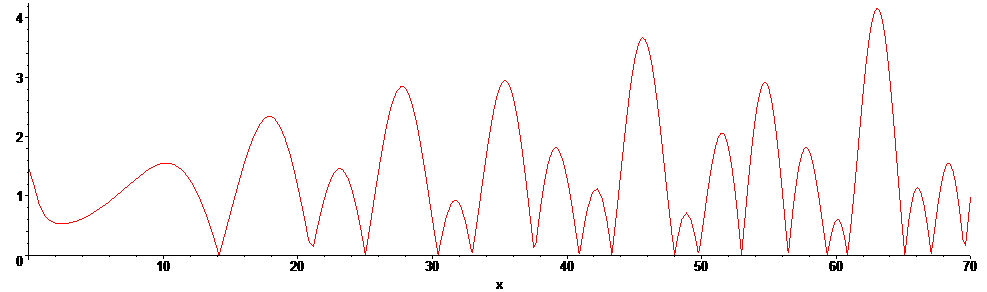
실제로 ζ( 1/2 + x*I )의 절대값을 그래프로 그려 보면 이렇다. 저 산들의 밑바닥이 근이라는 뜻 되겠다.
리만 제타 함수는 복잡한 함수들의 조합에다, 무한대 적분(정확한 부정적분 형태를 알 수 없는 놈을 대상으로 이상적분..)까지 동반하는 형태로 인해, 계산량이 실로 어마어마하다.
그렇기 때문에 평범한 다항함수, 삼각함수, 로그, 지수(일명 초등함수)로만 구성된 함수보다 그래프를 그리기가 훨씬 더 힘들다. 그러고도 저건 정확하게 그려진 게 아니다. (21 부근에 그래프가 정확하게 바닥까지 내려가지 않았음) 다른 건 다 해석적으로 확장한다 쳐도, 대소 비교가 존재하지 않는 복소수 구간에서 적분이란 게 어떻게 존재 가능하단 말인가?
그래프를 봐도 모양이 참 희한하다. 저기서 근들의(= 허수부 값) 분포에는 딱히 규칙성이 없는 것으로 여겨진다. 복소평면에서의 무슨 프랙탈 영역 그림 이래로 이 정도로 복잡기괴한 그래프를 보는 건 개인적으로 처음이다.;; 다만, 지금까지 셀 수 없이 많은 복소수 근들을 직접 구해 봤는데, 일단 리만 가설이 다 성립하긴 했다. 전부 1/2 + xx*I의 형태로 표현되었다. 자명하지 않은 근도 무한히 많이 존재하긴 하며, 이는 증명되어 있다.
아아.. 본인이 수학 분야에서 이렇게 길고 복잡한 글을 쓸 일이 이렇게 또 생길 줄은 정말 상상하지 못했다. 나도 머리가 뱅뱅 돌아 버리겠다.. ㅡ,.ㅡ;;
리만-제타 함수는 문제를 풀기는커녕 그 배경을 이해하는 것만으로도 복소해석학 등 최하 대학교 수학과 학부 이상의 고등 수학 지식을 요구한다.
공대 수준의 수학 지식이 아니다. 공대에서 배우는 통상적인 미적분의 개념을 아득히 초월하니 원.. 복소수는 그 정의상 실수부와 허수부의 관계가 아주 미묘하다 보니, 해석적으로 다루는 방법론도 평범한 다변수 기반 해석학과는 다르다.
이 함수의 자명하지 않은 근의 분포는 우리에게 도대체 무슨 의미가 있을까?
저게 다 규명되고 리만 가설이 증명 내지 반증된다고 해서 무슨 암호 알고리즘이 다 뚫리고 생활이 큰 혼란이 야기된다거나 하지는 않는다.
다만, 리만 가설은 현대 정수론의 금자탑이라 해도 과언이 아닌 소수 분포와 직접적인 관계가 있다.
자세한 내막은 모르겠지만, x보다 작은 소수의 개수를 나타내는 공식 x/log(x)은 제타 함수의 자명하지 않은 모든 근들의 실수부가 "1이 아니다" 내지 "1보다 항상 작다"와 동치 급으로 얽혀 있다고 한다. 즉, 소수 정리는 리만 가설이 참이라는 것을 얼추 전제로 하고 세워져 있다.
하지만 리만의 추측이 수학적으로 딱 엄밀하게 증명되거나 반증되지는 못한 상태이다. 마치 P와 NP의 관계 문제처럼 말이다.
전세계의 날고 기는 천재 수학자들, 심지어 필즈 상을 받은 사람도 내가 이 문제를 풀었다고 증명을 내놨지만, 어디엔가 오류와 불완전한 점(그게 왜 저렇게 연결되는데?)이 발견되어 종종 퇴짜를 맞곤 했다. 오죽했으면 20세기 초에 세계구급 수학자들이 이렇게 말을 했을 정도이다.
- 나는 잠들었다가/죽었다가 한 500년쯤 뒤에 깨어날 수 있다면, 벌떡 일어나자마자 주위 사람에게 "리만 가설 문제가 이제 풀렸나요?"라고 물어 보고 싶다. -- 다비트 힐베르트(1862-1943)
- 나는 배를 탈 일이 있으면 낚시로라도 "난 리만 가설을 증명했다.
하지만 증명을 다 적기에는 여백이 부족하다"라는 쪽지를 지니고 탄다. 그 상태로 사고가 나서 죽으면 세상은 낚시에 낚여서 나를 온통 안타까워하고 추모해 줄 것이다. 하지만 나는 무신론자이고, 신이 존재한다면 그런 내게 저런 영광을 허락해 주지 않을 것이기 때문이다." (즉, 저 쪽지가 나를 죽지 않게 하는 일종의 보험· 부적 역할을 할 것이란 말을 참 배배 틀어서 어렵게 표현했다. =_=) -- 고드프리 해럴드 하디(1877-1947)
사람에게는 오늘 당장 먹고 살기 위한 빵과, 내일을 준비하기 위한 꿈이 필요하다고들 그런다. 그것처럼 저명한 천재 수학자들은 다른 자기 전공 분야에서 논문 발표하고 연구 실적을 낸 뒤, 그걸 밑천으로 리스크가 큰(= 전혀 풀리지 않아서 시간과 노력만 낭비하게 될 수도 있는) 리만 가설에도 틈틈이 남 몰래 매달리는 식으로 시간을 분배하는 편이라고 한다.
이건 마치 침몰한 보물선을 인양하고 신대륙에서 금을 찾는 일에다가도 비유할 수 있을 것 같다. 금과 보물을 찾았다가는 인생한방 역전이지만.. 전혀 성과가 없으면 투자금만 날리고 사람을 완전 미치게 만들 수 있으며, 실제로 미쳐 버린 수학자도 몇몇 있다. (영화 뷰티풀 마인드 참고..)
그리고 미치지는 않았는데, 반대로 어줍잖은 실력으로 이 문제를 풀었다고 주장하면서 학계 사람들을 귀찮게 굴거나, 거짓 주작 사기를 치는 사람도 있다. 문화재를 거짓 조작한 사기꾼처럼 말이다.
그랬는데.. 지난 2018년 9월 말, 영국에서 '마이클 아티야'(1929-)라고 나이 90을 바라보는 어느 원로 수학자가 리만 가설을 수리물리학적인 방법론으로 접근하여 완전히 풀었다고 나섰다. 논문을 내고 방송 발표를 자청했다.
이 사람은 여느 듣보잡 관심종자가 아니었다. 무려 1966년(지금 본인과 비슷한 나이.ㅠㅠ)에 필즈 상을 받았으며 2004년에 아벨 상까지 받은 금세기 최고로 손꼽히는 천재요 수학계의 거장이었다. 소싯적에 리만 가설 만만찮은 연구 실적을 잔뜩 내기도 했고, 이딴 것 갖고 사기를 칠 아무 동기도, 이유도 없는 사람이었다.
그의 선언은 세계의 이목을 받았지만 정작 뚜껑을 열어 보니 학계의 반응은 허탈함과 아쉬움 일색이었다. "우리 대선배님이 갑자기 왜 이러시나.." 안 그래도 예전부터 그가 공개 석상에서 횡설수설하면서 오락가락.. 상태가 좀 안 좋다는 정황이 포착되어 왔는데, 이번 방송에서도 수학사가 어떻고 하면서 진짜 증명과 별 관계 없는 얘기만 늘어놓으면서 막무가내로 학계가 내 주장을 안 받아주는 거라고 우기는 식이었기 때문이다. 방송 말고 논문도 검증 과정이라고 하지만 예상 반응은 벌써부터 극히 회의적이다.
그래서 현직 수학자들은 이 사태에 대해서 언급을 극도로 꺼리면서 "비록 증명에 실패했다 하더라도 유의미한 연구의 밑거름이 될 것입니다" 덕담이나 하는 한편으로, "리만 가설이 위대한 수학자 한 분을 또 골로 보냈구나, 그것도 말년에.. 저분은 원래 늘그막에 저렇게 망신당할 군번이 절대 아닌데 아 슬프도다!" 이런 입장이었다고 한다...;;
사실, 본인은 이 뉴스 기사를 접하기 전에는 저 사람에 대해 알지도 못했다. 단지, 리만 가설 이상으로 악명 높고 역시나 여러 사람들을 골로 보낸 이력이 있던 "페르마의 대정리"를 풀어 낸 사람(앤드루 와일즈)이 영국 사람인 건 진작부터 알고 있었다. 저런 유럽 나라들은 어떻게 저렇게 수학· 과학이 발달할 수 있었는지 경이롭고 대단하게 느껴질 따름이다.
Posted by 사무엘