※ 이 글의 내용은 예전에 썼던 <확률과 조합에서 발견한 자연대수 e>와 <원에 대한 적분 외>의 연장선상에 있다.
1차원 선에서 0부터 1까지의 선분의 길이는 두 말할 나위 없이 1이다.
2차원 공간에서 원점, (1,0), (0,1)을 지나는 이등변삼각형의 넓이는 1의 절반인 1/2이다.
이를 더 확장해서 3차원 공간에서 원점과 (1,0,0), (0,1,0), (0,0,1)을 꼭지점으로 갖는 사면체의 부피는 1/6이다.
이를 일반화해서 n차원 적분을 생각해 보면, 차원이 하나 올라갈 때마다 n차원 축을 한 칸씩만 점유하는 초입방체의 부피는 1/(n!)로 팩토리얼의 역수가 되고, 전체 초면체와의 비는 기하급수적으로 감소한다는 걸 알 수 있다. x^n의 부정적분은 (x^(n+1)) / (n+1) + C이다.
한편, 한 변의 길이가 2인 정사각형의 넓이는 4이고, 그 안에 들어가는 반지름이 1인 원의 넓이는 잘 알다시피 pi이다. 원과 사각형의 넓의 비는 pi/4, 즉 78.5% 정도 된다.
이를 공간으로 확장하면 한 변의 길이가 2인 정육면체의 부피는 8이고, 그 안에 들어가는 반지름이 1인 구의 부피는 4*pi/3이다. 구와 정육면체의 부피 비율은 pi/6 (약 52.3%)으로, 넓이일 때보다 비율이 더 작아진다. 이 비율 역시 차원이 증가할수록 더욱 작아진다는 것은 두 말할 나위가 없을 것이다.
그럼 혹시 4차원, 5차원, n차원 초구의 부피를 구할 수도 있지 않을까? 몰론 있다.
원의 방정식의 핵심이라 할 수 있는 f(x) = sqrt( r^2 - x^2 ) 라는 함수를 먼저 정의하자. 얘는 x가 0에서 r로 갈 때 임의의 구간에서 원의 높이를 나타내는, 즉 '둥긂'을 수학적으로 기술하는 함수이니까 말이다.
반지름이 r인 원의 넓이는 잘 알다시피 int( 2*f(x), x=-r..r) 로 나타내어지며 pi*r^2이라는 유명한 공식이 나온다.
그럼 반지름이 r인 구의 부피는 pi*r^2에서 r 대신 f(x)를 다시 집어넣어서 적분을 하면 된다.
int(pi*f(x)^2, x=-r..r) 가 (4/3)*pi*r^3이 된다.
4차원부터도 동일한 방식으로 적분을 계속하면 된다. 수많은 구들이 4차원에 있는 원 표면의 높이 변화량만치 연속적으로 쌓여 있는 것이므로.. 저 r 대신에 또 f(x)를 집어넣으면
int(4*pi*f(x)^3/3, x=-r..r) 은 드디어 파이까지도 제곱이 되어 4차원 초구의 부피는 (1/2)* pi^2 * r^4가 나온다. 한 변의 길이가 2인 4차원 초정육면체와의 부피 비율은 약 30.8%대로 곤두박질친다.
5차원 초구는? int( pi^2 * f(x)^4 / 2, x=-r..r)의 결과는 (8/15) * pi^2 * r^5 (약 16.4%)
6차원 초구는 pi^3 * r^6 / 6 (약 8%)가 된다. 사면체의 부피만큼이나 이것도 비율이 갈수록 곤두박질친다.
요렇게 비율이 한데 수렴하고 특히 짝수차일 때와 홀수차일 때 번갈아가며 무슨 특성이 발견되는 건 리만 제타 함수의 값하고도 비슷해 보인다. 게다가 리만 제타 함수도 n이 짝수일 때는 나름 pi^n의 유리수배가 되기도 하니, 반지름 길이가 1인 n차원 초구의 부피하고도 비록 수학적 의미는 딴판일지언정 좀 비슷해 보이는 구석이 있다.
수학 전공자 중에는 위의 적분들을 직접 손으로 푸는 용자도 있다. 그나마 짝수 승일 때는 루트가 없어지기 때문에 계산이 더 쉬워지는 편. 난 차마 손으로 풀어 볼 시간이나 자신은 없어서 그냥 수학 패키지를 돌려서 답을 구했다.
딱 보면 알겠지만 식에는 규칙성이 있다. 홀수승일 때와 짝수승일 때를 따로 생각해서 각각 차수가 2씩 증가할 때마다 pi에 붙는 제곱도 1씩 증가하고 계수는 2/n씩 증가한다고 보면 정확하다. 짝수승일 때는 1/2 (4차원), 1/24 (6차원)처럼 상수 계수가 1/n!으로 깔끔하게 증가하는 반면, 홀수승일 때는 계수가 좀 복잡하게 올라간다.
울트라 초천재가 아니고서야 4차원이 넘어가는 초구의 존재를 인간의 머리로 제대로 상상하고 실감하기는 거의 불가능할 것이다. '넘사벽'이라는 말이 괜히 있는 게 아니다~!
눈과 귀로 직감할 수 없는 차원이라는 게 신앙의 영역에 있다면, 이해가 안 되더라도 말 그대로 믿음으로 받아들일 수밖에 없을 것이다. 그러나 수학은 그런 게 아니라 고도의 논리와 이성의 영역에 있다.
아쉬운 대로 고차원 공간을 시뮬레이션 할 수 있는 방법은 프로그램을 작성하는 것이다. 다음 코드는 n차원 공간을 -1부터 1까지 점을 순서대로 마구 찍은 뒤, 원점으로부터 거리가 1 이내인 점의 개수를 세서 부피 비율을 구한다. 깔끔한 재귀호출 대신 사용자 정의 스택으로 구현했다.
double GetVolume(int dim, double delta)
{
double buf[8], vl; int pos=0, i;
double initv=-1.0-delta;
__int64 x=0,y=0; buf[0]=initv;
while(pos>=0) {
if(pos==dim) {
for(vl=0, i=0; i<dim; i++) {
vl+=buf[i]*buf[i]; if(vl>1.0) break;
}
if(i==dim) ++x; ++y; --pos; //1 이내에 들면.
}
else {
buf[pos+1]=initv;
if( (buf[pos]+=delta) > 1.0) --pos; else pos++;
}
}
return (double)x/y;
}
그래서 이렇게 찍으면 결과는 다음과 같이 나온다.
printf("%f\n", GetVolume(2, 0.01)); //0.785075
printf("%f\n", GetVolume(3, 0.01)); //0.523467
printf("%f\n", GetVolume(4, 0.03)); //0.302340
printf("%f\n", GetVolume(5, 0.05)); //0.164649
처음엔 -1부터 1까지 0.01씩 움직이니까 200등분을 했지만 4차원과 5차원으로 갈수록 66등분, 40등분으로 간격을 늘린 이유는.. 당연히 4승, 5승으로 급격히 증가하는 계산량을 감당할 수 없기 때문이다. 그래서 2차원과 3차원은 값이 상당히 정확히 나온 반면, 4차원과 5차원은 오차가 좀 큰 편이다.
그래도 계산이 워낙 단순무식하고 간단하므로 OpenMP 지시자를 집어넣거나 직접 손으로 코드 차원에서 스레드를 강제 분배하든가 해서 멀티코어+병렬화 최적화로 계산 속도를 몇 배 정도 끌어올릴 여지는 존재한다.
사실은 4차원 이상으로 갈 필요도 없이, 3차원 공간에 구가 여러 개 포개어져 있는 장면을 상상하는 것도 쉽지 않다.
학교 수학 시간에 집합 사이의 bool 관계를 구하는 문제에서 집합의 개수는 3개를 넘어간 적이 없었다. 왜냐하면 2차원 평면에서 집합들의 모든 소속 가짓수를 벤 다이어그램으로 그릴 수 있는 한계가 3개이고 2^3, 총 8가지 가짓수이기 때문이다.
그러나 3차원 공간에서 구를 4개 포개어서 입체 벤 다이어그램을 그리면 16가지 가능성을 모두 표현할 수 있다. 구 3개가 8가지 가짓수를 만들고, 거기에 위에다 4개의 구를 적당히 겹쳐 놓으면 8개에다가 넷째 구와 겹치는 놈 8가지가 또 추가되어서 16개가 되니까 말이다. 이 역시 코드로 작성해서 무식하게 확인하면 다음과 같다.
struct SPHERE { double x,y,z; };
const SPHERE fp[4]={
{0,0,0},
{0.4,0,0},
{0.2,0.4,0},
{0.2,0.2,1.5}
};
auto Square = [](double x) { return x*x; };
SPHERE d;
bool bitfl[16]={false,};
for(d.x=-1; d.x<=1.5; d.x+=0.02)
for(d.y=-1; d.y<=1.5; d.y+=0.02)
for(d.z=-1; d.z<=1.5; d.z+=0.02) {
int bt=0;
for(int i=0; i<4; i++)
if( Square(fp[i].x-d.x)+Square(fp[i].y-d.y)+Square(fp[i].z-d.z) <=1) bt|=(1<<i);
bitfl[bt] = true;
}
for each(int n in bitfl)
printf("%d ", n);
반지름은 모두 1이고, (0,0,0), (0.4,0,0), (0.2,0.4,0), (0.2,0.2,1.5)인 4개의 구를 설정한다. 그리고 -1부터 1.5까지 0.02 간격으로 뺑뺑이를 돌려서.. 각 점별로 자기가 속하는 구의 번호에 해당하는 2진수 비트들(8+4+2+1)의 합을 구한다. 그 뒤 그 합에 해당하는 플래그를 켠다.
나중에 플래그의 값을 출력해 보면 모든 비트들이 1로 바뀌었음을 알 수 있다. 즉, 어느 구에도 속하지 않은 놈, 모든 구에 속한 놈, 1, 3, 4번 구에만 속한 놈, 2, 3번 구에만 속한 놈 등등 16가지 가능성이 실제로 모두 존재한다는 뜻이다. 어찌 보면 당연한 얘기이다. 그 반면 구가 5개를 넘어가면 그 32, 64가지 가능성을 한꺼번에 3차원에서 표현할 수는 없게 된다.
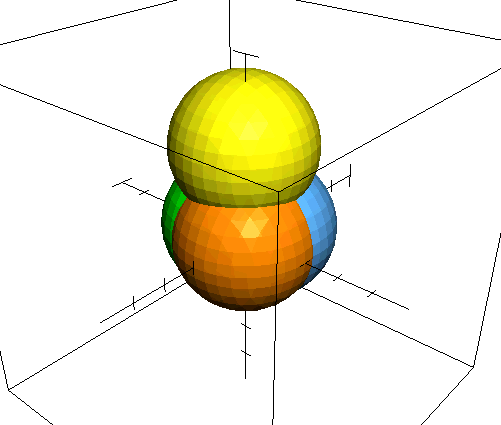
반지름이 수십~수백 정도에 달하는 충분히 큰 구의 복셀의 표면을 보는 느낌은 어떨까 문득 궁금해진다.
수학 패키지 소프트웨어들은 3차원 음함수의 그래프를 아무래도 폴리곤+와이어프레임 형태로 근사해서 보여 줄 것이다. 하지만 곡선/곡면을 폴리곤이 아니라 아예 계단현상을 볼 수 있는 복셀로 근사해서 보면 또 느낌이 굉장히 이색적일 것 같다.

표면에는 역시나 원들 무늬가 그러져 있구나!
앞서 보다시피 5차원~6차원 이상으로 가면 단순무식하게 점을 때려박는 것도 계산이 너무 많아서 도저히 감당할 수 없다.
이럴 때 정확한 초구의 부피를 구할 수 있는 건 역시나 수학 해석적인 방법이라는 것을 알 수 있다.
미분 내지 역함수인 부정적분을 할 때 변수의 차수와 계수가 왜 저렇게 변하는지는 다항함수의 차이 극한값을 구해 보면 알 수 있다. 극한부터 시작해서 미분· 적분이라는 개념을 생각해 낸 건 정말 위대한 발견인 것 같다.
Posted by 사무엘