오늘날처럼 컴퓨터의 문자 인코딩이 유니코드로 천하통일이 되기 전엔 국내에서는 2바이트 완성형과 조합형 한글 코드 논란이 가라앉지 않고 있었다. 완성형은 94*94 격자 모양의 단순하고 국제 규격에 부합하는(?) 방식으로 인코딩돼 있었지만 한글의 구성 원리를 무시하고 한글을 난도질했다는 비판을 떠안고 있었다.
완성형은 “한글 vs 비한글”을 구분하고 처리하는 데 유리했다.
그에 비해 민간에서는 “한글 글자 vs 낱자”의 처리가 더 용이한 조합형이 훨씬 더 대중적으로 쓰였다. 그도 그럴 것이 640KB 기본 메모리를 1KB라도 더 확보하려고 목숨 걸던 시절, 메모리 모델이 어떻고 far 포인터가 어떻고 이러던 시절에.. 한글 처리를 위해서 2350자 테이블을 내장하고 다닌다는 건 성능과 효율로나 민족 정서(?)로나 도저히 용납할 수 없었기 때문이다.
허나, 명목상 국가 표준은 완성형이었기 때문에 마소 역시 도스와 Windows의 한글판을 전적으로 완성형 기반으로 만들었다. 완성형은 두벌식과 마찬가지로 그 시절에 소프트웨의 한글판을 필요 이상으로 더 무겁게 만든다는 비판을 피하기 어려웠다. 다만, 이건 애초에 우리나라에서 표준을 이상하게 만든 게 잘못이지 마소의 잘못은 아닐 것이다.
Windows 3.1이야 이런 배경에서 만들어졌기 때문에 한글 IME로 똠, 펲 같은 글자가 입력되지 않았으며, 또ㅁ, 페ㅍ이라고 글자가 풀어졌다. ‘썅’은 2350자에 속해 있는데 중간의 ‘쌰’는 그렇지 않기 때문에 ‘썅’까지 덩달아 입력할 수 없는 것은 유명한 사실이다.
그리고 처음부터 ‘쌰’를 입력하면 ‘ㅆㅑ’라고 잘 갈라지는데, 두벌식에서 ‘있’ 다음에 ㅑ를 입력하면 ‘이ㅆㅑ’가 되지 않고 뭔가 올바른 동작이 나오지 않았던 걸로 본인은 기억한다.
이런 것들이 한글 입력기, 특히 특정 문자 입력 제한이 걸린 두벌식 입력 방식을 구현할 때 고려해야 하는 복병이다. 날개셋이야 이 분야 전문이기 때문에 그런 것들도 다 정상적으로 처리해 준다.
그럼 차기 버전인 Windows 95는 상황이 어땠을까?
Windows 95는 오늘날 세계 표준 문자 집합 겸 인코딩인 유니코드, 특히 유니코드 중에서도 버전 2.0이 한창 제정되고 있던 와중에 개발되고 먼저 출시되었다. 이건 굉장히 중요한 사건이었다.
우리나라에서는 수 년 전 유니코드 1.x 시절에는 완성형 2350자만 그대로 제출하는 삽질을 저지른 적이 있었다. 그러다가 유니코드 2.0에서 문자 체계를 싹 재정비하는 인류 역사상 마지막 기회가 찾아왔을 때.. 한글을 11172자 모두 순서대로 등록하려는 과감한, 역사적인 계획을 세웠다. 그래야 글자 코드값으로 자모 정보를 쉽게 추출할 수 있기 때문이다.
이건 스타에다 비유하자면 종족 밸런스를 앞으로 다시는 바꾸지 않는 1.08 패치와 비슷한 타이밍이었다.
그런데 그렇게 하려면 세계를 설득해야 했다.
다른 나라들은(특히 일본과 중국도) BMP 영역의 1/5 가까이를.. 그것도 사용자가 1억도 채 안 되는 언어의 고유 문자로 싹 도배하려는 한국을 고깝게 보고 이의를 제기했다.
유니코드 회의에서 누가 발언권을 얻으려면 한화로 억대에 달하는 회원 등록비도 많이 내야 하는데, 이런 비용을 한컴 같은 기업에서 많이 후원해 줬다. 저 때는 삼성전자도 훈민정음 워드 같은 프로그램이나 간간이 만들었지, 지금 정도로 IT계에 세계구급 영향을 행사하는 기업이 아니었다는 걸 생각해 보자!
이런 우여곡절 끝에 한글 11172자는 1996년 7월, 유니코드 위원회의 승인을 받아서 성공적으로 등재되었다. 이거 내막을 아는 사람이라면 이것도 1981년 서울 올림픽 바덴바덴의 기적에 맞먹는 외교 승리라고 여기고 칭송한다. 올림픽은 52:27의 압승이라도 했지만 11172자 등재는 찬성이 반대를 한 표 차이로 정말 간신히 꺾은 거라고 한다.
그런데 문제는 Windows 95는 유니코드 2.0이 정식으로 발표되기 미묘하게 약간 전에 출시되었다는 것이다. 한글판도 1995년 11월 말에 출시됐으니..;;
그럼에도 불구하고 각종 글꼴과 코드 변환 테이블은 이미 유니코드 2.0을 기준으로 맞춰져 있다. 어떻게 이게 가능했을까?
유니코드 2.0에다가 한글을 2350자가 아니라 11172자를 몽땅 집어넣기 위해서는.. 근거가 필요했다. 유니코드가 아닌 기존 2바이트 인코딩 중에도 한글 11172자 표현이 가능한 놈이 있어야 했다.
그럼 Windows가 처음부터 조합형 코드로 개발됐으면 좋았겠지만 모종의 이유로 인해 그리 되지 못했고.. 결국은 기존 완성형에다가 지저분한 독자적인 편법을 동원해서 비완성형 한글을 끼워넣을 수밖에 없었다.
이게 그 이름도 유명한 확장완성형, 일명 CP949 인코딩이다.
KS X 1001은 한글 2350자, 한자 4888자 등을 포함하는 그 2바이트 완성형 문자 집합/코드이고, KS X 1003은 역슬래시를 원화로 대체한 그 한국 특유의 1바이트 영문/숫자 아스키 문자 집합이다. 이 둘을 합쳐서 EUC-KR이라고 부르고, 여기에다가 확장완성형까지 추가하면 CP949가 된다. 집합 관계를 정리하자면
(참고: KS X 1002는 완성형 형태로 현대 한글, 옛한글, 한자를 추가로 정의하는 규격이다. 하지만 KS X 1001과 병용하는 인코딩 규칙이 제정되지 않아서 컴퓨터에서 실제로 쓰인 적은 없는 캐잉여이다. 얘는 애초에 유니코드 1.1에다가 글자를 추가로 등록할 근거를 마련하려고 어거지로 만든 문자 집합에 지나지 않는데, 이제는 유니코드 1.1 자체도 오래 전에 흑역사가 됐으니 더욱 의미와 존재감이 없다.)
이렇듯, 확장완성형이라는 건.. 비록 처음에 첫단추를 잘못 끼우긴 했지만 뒤늦게 유니코드 2.0에라도 한글을 11172자를 순서대로 다 집어넣기 위해서 도입한 2바이트용 타협 절충안이었다. 마소에서는 한국 편을 들면서 도와 주면 도와 줬지, 최소한 상황을 더 나쁘게 만든 건 절대 없었다.
그럼에도 불구하고 1990년대 당시에는 마소에서 완성형에다가 그보다 더한 확장완성형까지 집어넣어서 한글을 난도질한다고 엄청난 논란이 일었다. 심지어 한컴에서도 아래아한글 도움말 및 제품 광고에서 이 괴담을 어느 정도 활용하고 부추겼다.
왜 한글을 난도질 하느냐 하면, 확장완성형은 이미 2350가 조밀하게 순서대로 배치된 건 그대로 유지하면서 나머지 틈새에다가 비완성형 8822자를 집어넣는 형태가 되기 때문이다. 그러면 겉보기로는 11172자가 모두 배당되지만 문자의 코드값 순서가 그 문자의 사전상의 배열 순서와 일치하지 않게 된다. 사전 순 정렬을 하려면 코드값을 별도로 보정을 해야 한다.
물론 코드값만으로 문자를 정렬할 수 있는 게 가능하지 않은 것보다는 더 직관적이고 깔끔하고 낫다. 하지만 오늘날 유니코드는 시간 차를 두고 뜬금없이 여기저기 지저분하게 추가된 문자들이 워낙 많기 때문에(특히 한자~!!), 거시적으로 봤을 때 코드값만으로 문자들을 정렬하는 건 어차피 불가능하고 무의미해져 있다.
뭐, 이것도 논란이 다 끝난 오늘날의 관점에서 보니까 별것 아닌 것처럼 보이지, 2바이트 한글 코드만 단독으로 생각하던 시절에 확장완성형이 답답하고 지저분하게 보이는 것도 부인할 수 없어 보인다.
그리고 마소는 훗날 IMF 때 경영난에 빠진 한컴에다가 돈줄을 대 주는 대신 아래아한글의 개발을 중단시키려 했던 바 있다. 그러니 확장완성형에 대한 불필요한 오해 실드를 감안하더라도 마소에 대한 국민 감정이 마냥 좋을 수만은 없었을 것이다.
아무튼, 그 시절 Windows 95는 유니코드 2.0의 정식 도입을 선도하면서 온전한 한글 11172자의 입출력이 가능해지려는 과도기에 연결 고리 역할을 했다.
참고로 95 말고 Windows NT는 도스 짬뽕이던 기존 Windows와 달리, 1993년 첫 버전부터 2바이트 wide char 유니코드 기반이었다. 얘도 유니코드 2.0이 정착할 무렵이 돼서야 본격적으로 정식 한글판이 나올 수 있었다. 3.51부터 말이다.
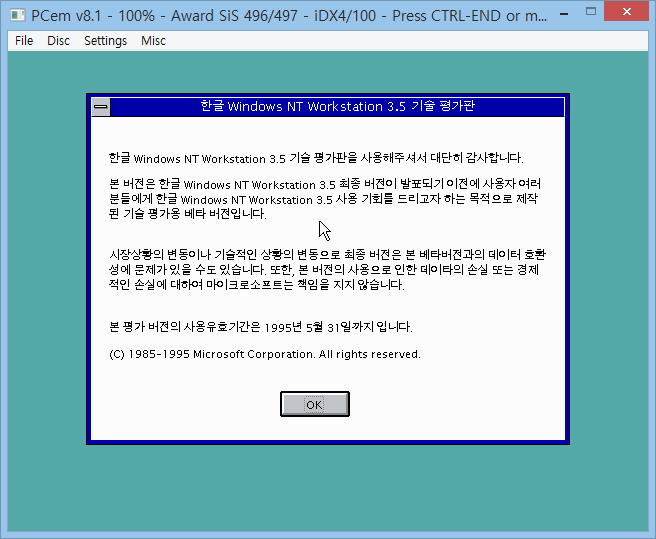
Windows NT 3.5 한글판의 ‘베타 버전’ 평가판. 이건 Windows NT의 역사상 최초로 만들어진 한글판으로, 정말 엄청난 희귀 레어템이다. 마치 Windows 2.x의 듣보잡 한글판처럼 말이다.
저 화면에서 한글 글꼴은 기존 Windows 3.1의 돋움체(큐닉스 제작) 8포인트이다. 하지만 영문은 정체를 모르겠다. W와 i의 폭이 다른 가변폭인 걸 보니 같은 돋움체의 영문은 아닌데, Arial은 물론이고 심지어 후대에 등장한 Tahoma나 Verdana까지 그 어떤 영문 글꼴도 저 크기에서 9나 5의 획이 저렇게 생기지 않았다.
그런데 저 영문 모양이 내가 보기에 전혀 낯설지는 않다.
마소에서 개발한 1990년대 옛날 프로그램의 스플래시 화면 내지 About 대화상자에서 Copyright 문구가 저런 스타일의 글꼴로 표시된 걸 본 것 같기도 한데.. 정확한 정체는 모르겠다.
내 기억이 맞다면 Windows NT 3.51의 정식 한글판은 3.51의 특성상 Windows 3.1과 같은 구형 UI 기반임에도 불구하고 한글 글꼴은 이미 Windows 95 한글판과 동일한 한양 시스템 글꼴로 갈아탔다.
Windows NT의 역사에서 유니코드 1.1 방식 한글이 존재했던 적은 내가 아는 한 없다. 만에 하나 있다면 그건 조합형 코드를 잠깐 썼었다고 전해지는 MS-DOS의 초창기 한글판만큼이나 완전 전설 속에나 존재하지 싶다.
이렇게 95건 NT건 온전한 11172자짜리 유니코드 2.0 기반임에도 불구하고.. 95의 한글 IME를 써 보면.. 구버전인 Windows 3.1과 마찬가지로 여전히 2350자밖에 입력할 수 없었다. 다만, “있+ㅑ”일 때는 ㅆ이 뒷글자로 넘어가지 않도록 로직이 약간 개선돼 있었다.;; ㅎㅎ
사실, Windows 95의 한글 IME는 확장완성형을 기반으로 11172자를 모두 입력하는 기능도 구현은 돼 있었다. 하지만 그걸 기본적으로는 봉인해 놓았으며, 사용 여부를 별도의 유틸리티를 통해 따로 지정할 수 있었다!
바로, C:\Windows 디렉터리에 있는
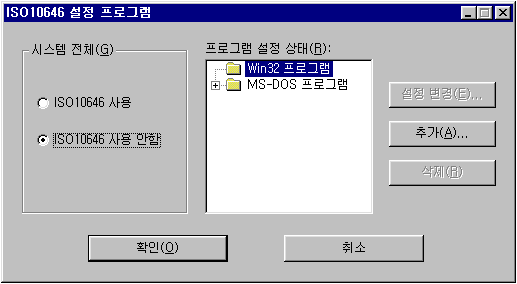
프로그램 UI에는 유니코드니 완성형이니 같은 말은 없고 그냥 "ISO 10646 사용 여부"가 전부였다. 유니코드의 문자 집합을 가리키는 표준 규격 명칭이 ISO 10646이기 때문이다.
전체 사용 아니면 특정 프로그램에서만 사용.. 이런 걸 지정해 주면 타 프로그램에서 똠쌰 등등의 글자를 입력할 수 있었다.
신기한 것은 Windows용 프로그램뿐만 아니라 도스용 mshbios의 한글 입력기까지 이 설정의 영향을 받았다는 것이다. 설정값을 레지스트리가 아니라 파일에다 저장했던가 보다. 아니면 도스에서도 레지스트리 파일에 저수준으로 접근을 했던지..
확장 한자의 사용 여부를 옵션으로 지정하는 것처럼 2350/11172자 입력 범위도 그냥 IME의 옵션으로 지정하면 됐을 것 같은데 굳이 별도로.. 제대로 문서화되지도 않은 프로그램에다 저렇게 꽁꽁 숨겨 놨다.
부작용을 어지간히도 의식했는지 각종 프로그램별로 입력 범위를 달리 지정할 수 있게 신경을 썼다. 즉, 여느 평범한 IME 옵션이 아니라.. 날개셋으로 치면 응용 프로그램별 동작 보정 옵션과 비슷한 걸로 취급한 것이다.
훗날 MS Office 97이 나왔고.. 그 중 Word는 단품으로 따로 팔기도 했다.
마소 역시 한컴 진영의 조합형 한글 마케팅을 많이 의식했는지, 신문 광고에서 조그맣게.. "우리 마소 제품에서도 똠방각하 펩시콜라 찦차를 입력할 수 있습니다." 문구와 함께, iso10646 프로그램 사용법을 소개해 놓기도 했었다.
본인은 학창 시절에 그 광고를 직접 본 기억이 있다.
지금도 구글에서 iso10646.exe 라고 검색해 보면 옛날 흔적을 찾아볼 수 있다.
마소의 전략은.. 요런 프로그램을 몰래 집어넣은 뒤, 확장완성형이 계속 부정적인 피드백을 받으면 Windows 95는 그딴 거 지원한 적 없다고 발뺌 하면서 2350자 기존 완성형에만 머무르면 될 것이고,
한글을 2350자밖에 입력 못 한다고 욕먹는 게 더 크면, 저 비장의 프로그램을 음지에서 양지로 끄집어내려는 속셈이었던 것 같다. 쉽게 말해 간보기 전략이다.
그러다가 Windows 98부터는 이런 간보기가 없어지고 그냥 모든 프로그램에서 확장완성형까지 활용한 11172자 한글 입력이 되기 시작한 것이다. 나중에 Office 2000과 함께 옛한글 입력기가 도입됐을 때는 이제 마소의 제품이 옛한글의 표현 능력도 아래아한글 97과 한컴 2바이트 코드를 추월하게 됐다.
이상이다. “라떼는 말이야” 같은 얘기가 좀 길어졌다.. ^^
25년 전, Windows 3.1에서 95로 넘어간 것은 정말 엄청난 격변이었다. 하지만 Windows 95와 98 사이에도 컴퓨터 환경은 굉장히 많이 바뀌었다.
가정용 PC의 평균 램 용량이 4~16MB대이던 것이 그 짧은 기간 동안 32~128MB로 순식간에 뻥튀기 됐다. PC 규격도 이것저것 많이 바뀌고.. 또 무엇보다도 이 사이에 유니코드 2.0이 제정되었다. 운영체제 차원에서 UTF-8 인코딩이 직접 지원되기 시작한 최초의 Windows가 바로 98이다.
Windows에서 완성형 2350자에 구애받지 않고 한글 입력이 가능해지기까지 이런 우여곡절이 있었다.
Windows 98은 현대 한글이 완전히 해금됐고, 지난 Windows 8 (2012)부터는 옛한글까지 해금됐으니 참 격세지감이다. 그 사이의 XP는 입력 프로토콜이 IME에서 TSF로 넘어간 과도기였고 말이다.
그런데 정작 옛한글 말뭉치를 엄청나게 많이 구축한 21세기 세종 계획은 이것보다 미묘하게 일찍 진행된 바람에 비표준 한양PUA 방식으로 결과물을 산출해 버렸으니 타이밍이 안습했던 구석이 있다.
Posted by 사무엘

