1. 아이콘 불러오기
창(그 자체 또는 클래스)에다가 아이콘을 지정하기 위해 흔히 LoadIcon 함수가 쓰인다.
얘는 원래 고정된 32*32 크기의 기본 아이콘 하나만을 달랑 가져오는 함수로 출발했다. 허나 Windows 95부터는 글자 크기와 같은 16*16 작은 아이콘이라는 것도 추가됐고, 나중에 XP쯤부터는 24*24, 48*48 같은 다양한 중간 크기가 도입됐다.
거기에다 화면 DPI까지 가변화가 가능하지, 256픽셀 대형 아이콘까지 도입됐지.. 이거 뭐 아이콘이라는 건 이제 도저히 단일 크기 이미지라고 볼 수 없는 물건으로 바뀌었다. 한 아이콘이 다양한 크기와 색상 버전을 가질 수 있다는 점에서 과거의 비트맵 글꼴과 약간 비슷한 위상이 됐다.
한편, 원래 마우스 포인터(cursor)와 아이콘은 기술적인 원천과 본질이 거의 같은 물건이었다. 작은 정사각형 크기의 이미지 비트맵과 마스크 비트맵의 쌍으로 표현된다는 점에서 말이다. 마우스 포인터는 거기에다가 hot spot 위치 정보가 추가됐을 뿐이었다.
그랬는데 마우스 포인터는 애니메이션이라는 바리에이션이 생겼고, 아이콘은 크기 바리에이션이 생겼다고 보면 되겠다. 동일한 특성을 같이 공유하다가 서로 다른 방향으로 기능이 추가된 것이다.
Windows 95에서는 창이나 창 클래스에다가 아이콘을 지정할 때 큰 아이콘과 작은 아이콘을 구분해서 지정할 수 있게 했다. 그래서 WNDCLASS에는 멤버가 하나 더 추가된 Ex버전이 만들어졌다. WM_SETICON 메시지도 아이콘의 대소 종류를 지정하는 부분이 wParam에 추가됐다.
그리고 LoadIcon 함수 자체도.. Ex가 추가된 건 아니고, 비트맵, 아이콘, 포인터까지 다양한 크기를 모두 처리할 수 있는 완벽한 상위 호환 LoadImage에 흡수되었다. 스펙을 보면 알겠지만 기능이 정말 많다.
하지만 내 경험상, 굳이 Ex 버전을 쓰지 않고 WNDCLASS의 hIcon에다가 큰 아이콘만 LoadIcon으로 지정해 주더라도.. 동일한 ID의 아이콘에 큰 아이콘과 작은 아이콘이 모두 있다면 별도의 처리가 없어도 괜찮았다. 프로그램 타이틀 창에 작은 아이콘은 그 별도의 작은 아이콘으로 자동으로 지정되는 듯하다. 큰 아이콘을 흐리멍텅하게 resize한 놈이 지정되는 게 아니라는 뜻이다.
그래서 본인은 지금까지 프로그램을 개발하면서 굳이 WNDCLASSEX와 RegisterClassEx를 사용한 적이 없었다. 큰 아이콘과 작은 아이콘이 ID까지 다른 서로 완전히 다른 아이콘일 때에나 이런 전용 함수가 필요한 듯하다.
단, 윈도우 클래스를 등록하는 상황이 아니라 대화상자 같은 데서 WM_SETICON으로 아이콘을 지정할 때는 큰 아이콘과 작은 아이콘을 LoadImage 함수로 구분해서 일일이 지정해 줘야 했다.
참고로 Windows에서 아이콘이라는 건 메모리 관리 형태가 크게 세 종류로 나뉜다. (1) 메시지박스에서 흔히 볼 수 있는 ! ? i 표지처럼 시스템 공통 공유 아이콘, (2) 응용 프로그램의 아이콘 리소스를 직통으로 가리키기만 하는 공유 아이콘, (3) 그게 아니라 자체 메모리를 할당하여 동적으로 독자적으로 생성된 놈.
(3)만이 나중에 DestroyIcon을 호출해서 제거해 줘야 한다. (2)는 해당 모듈의 생존 주기와 동일하게 관리된다. (1)이야 뭐 언제 어디서나 유비쿼터스이고..
그리고 RegisterClass 계열 함수가 특례를 보장해 주는 건 역시 리소스 기반인 (2) 한정이다.
wndClass.hIcon = LoadIcon(hInst, IDI_MYICON) 이렇게 돼 있던 곳에서 LoadIcon(...)의 결과를 CopyIcon( LoadIcon(...))으로 감싸서 아이콘의 형태를 (3)으로 바꿔 보시라. 그러면 그 프로그램의 제목 표시줄에 표시된 작은 아이콘은 큰 아이콘을 resize한 뭉개진 모양으로 곧장 바뀔 것이다. 이것이 차이점이다.
사실, Visual Studio의 리소스 에디터 상으로는 구분이 잘 되지 않지만, 응용 프로그램 모듈(EXE/DLL)에 저장되는 리소스 차원에서는 단순 아이콘(RT_ICON)과 아이콘 집합(RT_GROUP_ICON)이 서로 구분되어 있다. 후자는 전자의 상위 호환이다. RegisterClass는 이를 감안해서 동작하지만 HICON 자료형이나 LoadIcon 같은 타 함수들은 일반적으로 그렇지 않은 것으로 보인다.
이럴 거면 wndClass.hbrBackground에 (HBRUSH)(COLOR_WINDOW+1)이 있는 것처럼 hIcon에도 (HICON)IDI_MYICON 이런 게 허용되는 게 더 깔끔하겠다는 생각도 든다.
자, 이 정도면 아이콘 지정에 대해서 더 다룰 게 없어야 하겠지만.. 그렇지 않다. LoadImage 함수에 약간의 버그가 있다.
얘는 (1) 시스템 공용 아이콘에 대해서는 요청한 크기에 맞는 버전을 되돌리지 않고 가장 큰 놈 또는, 걔네들 용어로는 캐시에 보관돼 있는 크기의 이미지만을 되돌린다. 즉, 기존 LoadIcon과 다를 바 없이 동작한다.
특정 크기에 해당하는 아이콘을 정확하게 되돌리라고 별도의 함수까지 만들었는데 그건 (2), (3) 계층에 해당하는 custom 아이콘에 대해서만 동작한다. (1)에 대해서는 글쎄, 성능 때문인지 호환성 때문인지 잘못된 동작을 일부러 방치해 버리고는 더 고치지 않는 듯하다.
그렇기 때문에 시스템 공용 아이콘의 16픽셀급 작은 버전을 이 함수로 얻을 수 없다.
Windows Vista부터는 사용자 계정 컨트롤이라는 보안 기능이 추가되어서 관리자 권한을 나타내는 방패 아이콘(IDI_SHIELD)이 추가되었다. 얘도 UI 텍스트와 함께 작은 크기로 그려야 할 텐데.. LoadImage로는 256픽셀짜리 대형 아이콘만 얻을 수 있기 때문에 이걸 16픽셀로 줄여서 그리면 보기가 흉하다.
마소에서는 LoadImage 함수의 버그를 고친 게 아니라 Vista부터 LoadIconMetric이라는 함수를 추가했다.
얘를 사용하면 시스템 공용 아이콘에 대해서도 정확한 크기를 얻을 수 있다.
얘는 아이콘을 언제나 (3)번 형태로 동적 할당해서 되돌리기 때문에 다 사용하고 나서는 DestroyIcon을 해 줘야 한다. 처리하기 간편한 shared, read-only 속성을 포기하고 정확한 동작을 하도록 로직을 바꾼 것 같다.
그 외에 SHGetStockIconInfo라는 함수도 있어서 얘를 사용하면 한 마디로 탐색기에서 쓰이는 각종 디스크 드라이브, 폴더, 돋보기, 네트워크 등의 표준 셸 아이콘을 얻을 수 있다.
2. DrawFocusRect
Windows에서 대화상자를 키보드로 조작하다 보면, 현재 포커스를 받아 있는 각종 버튼(라디오/체크 박스 포함)이라든가 리스트 아이템에 가느다란 점선 테두리가 쳐진 것을 볼 수 있다. 이것은 DrawFocusRect라는 함수를 이용해서 그려진 것이다.
마소에서는 키보드 포커스를 받아 있는 GUI 구성요소에다가는 요 함수를 호출해서 점선으로 테두리를 그려 줄 것을 GUI 디자인 표준으로 명시하고 있다. 뭐, 일반 프로그래머라면 버튼 같은 커스텀 컨트롤을 직접 구현하거나 owner-draw 리스트박스를 만들 때에나 숙지할 만한 개념이다. 다른 요소들을 다 그리고 나서 맨 마지막으로 focus 테두리를 그려 주면 된다.
다만, 에디트 컨트롤은 애초에 깜빡이는 캐럿(caret; cursor)이 포커스에 대한 시각 피드백 역할을 하고 있기 때문에 또 점선 테두리를 그려 줄 필요가 없다.
이 점선은 이미 아시겠지만 xor 연산을 가미한 반전색이다. 원래 색과 반전 색이 교대로 등장하는 아주 단순한 패턴이다.
요즘 세상에 테두리는 그냥 알파 채널을 가미한 옅은 실선으로 그려도 될 것 같지만, 이 분야는 구닥다리 GDI 레거시 API와의 호환 문제도 있어서 그런지 여전히 옛날 그래픽 패러다임이 쓰이고 있다. 이 xor 테두리는 계산량 적고 간편할 뿐만 아니라, 다시 한번 그리라는 명령을 내리면 싹 사라지고 원래 이미지로 돌아온다는 특성도 있어서 더욱 편리하다.
이 테두리는 두께가 오랫동안 1픽셀로 고정되어 있었다. 하지만 1픽셀만으로는 너무 가늘어서 눈에 잘 띄지 않고 시각 장애인의 접근성에 좋지 않다는 의견이 제기되었다. 게다가 모니터의 해상도가 갈수록 올라가고 100%보다 더 높은 확대 배율도 등장하다 보니, 1픽셀 고정 두께의 한계는 더욱 두드러지게 됐다.
이 때문에 Windows XP부터는 제어판 설정에 따라 2픽셀 이상의 focus 테두리도 등장할 수 있게 됐다.
이 조치가 응용 프로그램에서 특별히 문제가 될 일은 거의 없겠지만, DrawFocusRect로 평범한 직사각형을 안 그리고 1~2픽셀 남짓한 두께의 수직선· 수평선을 그려 왔다면 선이 의도했던 대로 그려지지 않을 수도 있다. 같은 영역에 선이 두 번 그려지면서 점선이 없어져 버리기 때문이다.
DrawFocusRect는 기술적으로 사각형 테두리 모양으로 50% 흑백 음영 비트맵을 브러시로 만들어서 PatBlt() 한 것과 완전히 동일하다. raster operation은 PATINVERT (흑백 xor target)이고 말이다. 그러면 원래색 / 반전색이 교대로 등장한다.
xor이 아니라 and라면 과거 Windows 9x/2000의 시스템 종료 대화상자의 배경처럼 "검정 / 원래색"이 교대로 등장하면서 화면이 반쯤 어두워지는 걸 연출할 수 있을 텐데.. 이 래스터 연산 코드는 따로 정의돼 있지 않은 것 같다.
그런데.. Windows의 GDI API에서 흑백 비트맵은 자체적인 색이나 팔레트 따위가 없으며, 현재 DC의 글자색과 배경색이 DC에 select된 비트맵의 색깔로 쓰인다.
그렇기 때문에 DrawFocusRect로 정확하게 반전 점선 테두리를 그리려면 호출 당시에 해당 DC의 글자색과 배경색을 반드시 black & white로 해 줘야 한다. 시스템 색상 따질 것 없이 RGB(0,0,0)과 RGB(255,255,255)로 하드코딩하면 된다.
이렇게 해 주지 않으면 마지막으로 텍스트를 찍던 당시의 글자색 및 배경색이 무엇이냐에 따라서 focus 테두리의 색깔이 정확하게 반전색이 되는 게 아니라 들쭉날쭉 날뛰고 지저분해질 수 있다.
이건 꽤 중요한 사항인데 왜 MSDN 같은 문서에 전혀 소개되어 있지 않았나 모르겠다. 나도 10수 년째 모르고 있다가 요 얼마 전에야 깨달았다.
또한 50% 음영은 굉장히 단순하고 자주 쓰이는 패턴인데.. 브러시나 비트맵을 stock object로 제공을 좀 해 주지, 왜 안 하나 모르겠다. 요즘 같은 트루컬러, 알파채널 이러는 시대보다도 모노크롬, 16색 이러던 옛날에 더 필요했을 텐데 말이다.
CreateCaret 함수로 caret을 생성할 때는 일반적인 비트맵 핸들 대신 특수한 상수를 넣어서 50% 음영 모양을 지정하는 게 있는데.. caret보다는 다른 형태로 쓰이는 경우가 더 많다.
다음은 파란 배경에 대해서 잘못 그려진 테두리(위: 반전색+검정)와, 맞게 그려진 테두리(아래: 반전색+원래색)의 예시이다.
3. 비트맵 윤곽으로부터 region을 곧바로 생성하는 방법의 부재
Windows에서 region은 사각형이 아닌 임의의 비트맵 영역을 scan line들의 집합 형태로 표현하는 자료구조이며, 창을 사각형이 아닌 임의의 모양으로 만드는 데 쓰이는 수단이기도 하다. 이 블로그에서 예전에 한번 집중적으로 다룬 적이 있다. (☞ 예전 글)
Windows에서는 사각형이 아닌 임의의 복잡한 모양의 region을 생성하기 위해서 다각형, 원, 모서리간 둥근 사각형 등 여러 API를 제공하며, 집합 연산 비스무리하게 기존 region과 영역을 합성하는 CombineRgn이라는 함수도 제공한다.
그런데 이것만으로는 여전히 좀 2% 부족한 구석이 있다.
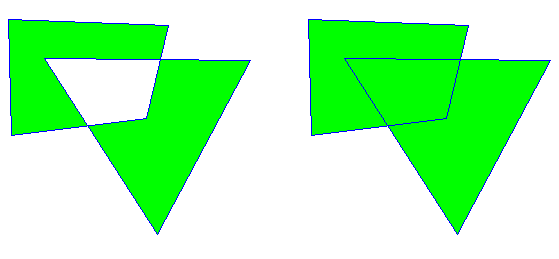
region을 생성할 때 사용되는 원· 다각형 그리기 함수의 결과와, 실제 DC에다 원· 다각형을 그리는 함수의 결과가 픽셀 단위로 100% 정확하게 일치하지 않을 때가 있다. 그래서 딱 정확하게 영역 안에다가 테두리를 깔끔하게 그리는 게 난감하다.
그리고 아예 만화 캐릭터 같은 모양의 창을 만들 때는.. 저렇게 벡터 이미지가 아니라 임의의 마스크 비트맵으로부터 그 윤곽 영역대로 region을 바로 생성할 수 있는 게 좋은데 의외로 그런 함수가 없다.
뭐, region의 내부 자료구조에 접근해서 복잡한 region을 직통으로 생성하는 방법도 없지는 않지만(정말 생짜 직사각형들의 집합..;; ) 이 역시 귀찮다는 건 어쩔 수 없다.
이 때문에 비트맵 그림으로부터 region을 생성하는 코드를 보면.. 비트맵 내용대로 한 줄 한 줄 CombineRgn(RGN_OR)로 한눈에 보기에도 정말 느리고 비효율적인 방법을 쓰고 있다.
layered window의 color key를 쓰면 투명색을 더 편리하게 구현할 수 있긴 하다. 허나, 창 아래의 그림자(CS_DROPSHADOW)는 region을 통해 지정된 경계하고만 정확하게 연계한다. 그렇기 때문에 애니메이션이 아닌 데서는 구닥다리 region도 여전히 필요하다.
이 분야는 다른 그래픽 API 같은 대안이 있는 것도 아닌데 마소에서 GDI API의 지원에 왜 이리 인식한지 모르겠다.;;
Posted by 사무엘