- 지금으로부터 무려 30년도 더 전에 만들어진 엄청난 옛날 물건이다. 나이가 본인과 맞먹는다~!
- 게임기(오락기 포함)이 아닌 PC용이다. 그래서 비주얼이 겨우 4색 CGA로 맞춰져 있는지라 당대의 게임기용 게임들보다는 그래픽이 다소 초라해 보인다.
- 본인은 옛날에 컴퓨터 학원에서 구경했던 적이 있다. 그런 인연이 있기 때문에 이렇게 내 블로그에다 소개도 하는 것이다.
- 개인 작품이다.
- 프로그램은 롬/카트리지 이미지 따위가 아니라 COM 파일 하나로 존재한다. 그래서 도스박스 정도의 에뮬레이터에서 간단히 실행 가능하다.
- 딱히 이렇다 할 엔딩이 없다. 단지 인간이 도저히 감당할 수 없을 정도로 게임 진행이 점점 더 빨라지고 어려워질 뿐이다.
- PC용이지만 그래도 여전히 게임기용 게임을 표방하는지, 실행을 종료하는 명령도 없다.
- 오늘날은 다들 '리메이크' 작품이 나와 있다. 특히 모바일용으로. 게임 목표와 방식은 동일하지만 그래픽과 사운드를 월등히 더 고퀄로 끌어올려서 말이다.
"아~ 이거! 그때 그랬지" 하면서 공감하는 old-timer들이 많이 계시기를 기대하며 글을 시작하겠다.
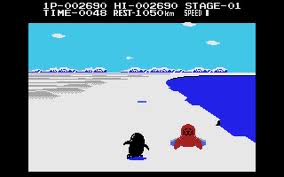
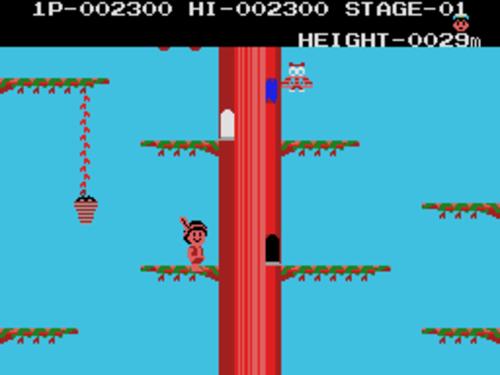
1. Paratroopers (1982)
우리는 화면 하단 중앙의 포탑의 각도를 좌우 화살표로 조종할 수 있다. 하늘 위로는 헬리콥터들이 수시로 드나드는데 총알을 맞혀서 떨어뜨려야 한다. 총알을 한 발 쏠 때마다 점수를 1 잃지만 목표물을 맞히면 그보다 더 많은 수의 점수를 얻는다. 단, 0점이라도 총알 보급 자체는 무한임.

가끔은 헬리콥터에서 낙하산을 탄 군인이 떨어지는데 얘는 반드시 쏴 죽여야 한다. 좌나 우 한 방향에 군인이 4명이 생기면 이 군인은 포탑 위로 기어 올라와서 포탑을 부수며 이로써 게임이 끝난다.
또한 주기적으로 헬리콥터 대신 제트기가 날아오면서 폭탄을 일직선으로 투하하는데, 이 폭탄도 요격해야 한다. 안 그러면 포탑은 폭탄에 맞아 박살 난다. 폭탄을 요격했을 때의 점수가 가장 높다.
재미있는 것은 사람의 경우 사람 자체가 아니라 낙하산만 맞히는 게 가능하다는 점이다. 그러면 그 사람은 땅바닥으로 운지-_-하는데, 아래에 다른 사람이 있다면 그 사람도 같이 죽는다. 이것이 포탑 아래에 이미 내려간 군인을 제거하는 유일한 방법이다.
나름 아기자기한 요소가 여기저기 담겼고 상당히 재미있는 시간 죽이기용 게임이다.
다만 실제로 게임을 해 보면 조작이 굉장히 불편하다는 게 아쉬운 점이다. 폭탄 요격도 생각보다 잘 안 돼서 첫 제트기 씬 때 죽어 버리는 경우가 허다하다.
포탑이 돌아가는 속도, 총알이 날아가는 속도도 그리 빠른 편이 아니어서 군인들이 좌우로 사정없이 떨어질 때 신속하게 대응하기 어렵다.
이 게임의 개발자는 폴란드계 미국인인 Greg Kuperberg인데.. 이 사람은 1967년생이다. 즉, 저 게임을 중3~고1쯤 되는 나이일 때 어셈블리어를 혼자 뚝딱거리며 만들었다는 뜻이다. 그리고 이 글에서는 소개하지 않지만, 저 사람은 비슷한 시기에 이것과 비슷한 타입의 다른 게임도 여럿 개발한 경력이 있다.
10대 중반의 나이에 엄청난 프로그램을 개발한 괴수야 이 세상에 한둘만 있는 건 아니니, 이것만으로는 그렇게까지 대단한 이야기가 아닐 수 있다. 하지만 저 사람은 좀 더 무서운 가정사와 내력이 있는데, 바로 부모가 모두 영문 위키백과에 등재되어 있을 정도로 저명한 수학자이다. (대학교 수학과 교수) 그리고 저 사람 자신도 나중에 미국의 유수의 명문대에서 박사 학위를 받은 뒤 나중에 수학과 교수가 되었고, 수학은 아니지만 물리학과 교수인 여자와 결혼했다.
이 정도면 우리나라의 홍 성대 씨에 맞먹는 수학 명문 가문이 아닐 수 없다.
수학 덕후가 만든 덕분에 헬리콥터나 대포가 박살날 때 날아가는 파티클들의 모양과 움직임이 상당히 고퀄이었던 건지도 모르겠다. 다시 말하지만 저건 중삐리~고삐리 급 애가 만든 게임이다.
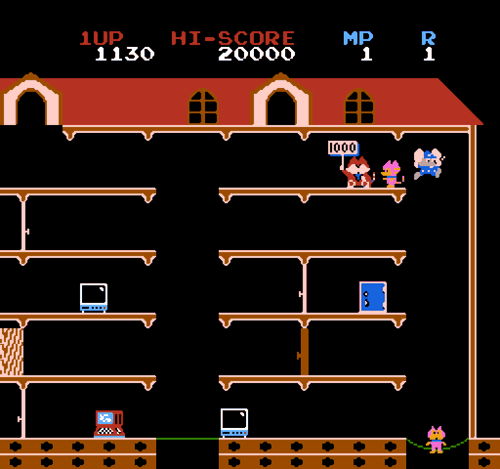
2. Bouncing Babies (1984)
화면의 왼쪽엔 5층짜리 건물이 온통 불길에 휩싸여 있으며, 미처 지상으로 대피를 못 한 어린 아기들이 수시로 창문에서 떨어진다. 그리고 당신은 안전 낙하용 매트를 든 2인조 구급대원이다. 아기는 한번 매트에 떨어지면 오른쪽으로 세 번 통통 튀는데, 이때도 아기를 매트로 받아서 구급차가 있는 데까지 안전하게 보내야 한다. 게임 진행이 하도 엽기적이어서 머리에서 잊혀지지가 않는다. (걍 구급차를 좀 더 건물에 가까이 주차시켜 놓지 그래..?? 같은 건 묻지 말자..ㅋ)
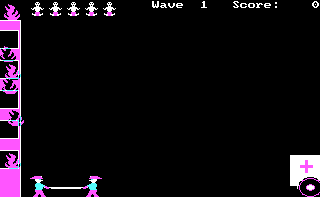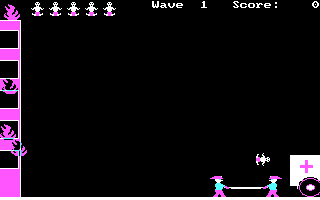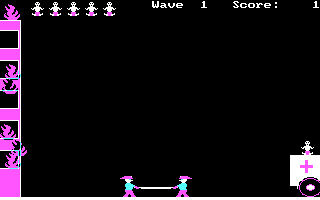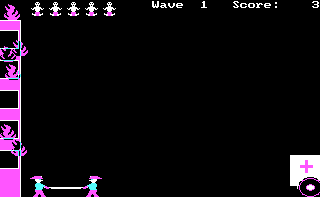
게임의 기술 수준은 그렇게 높지 않다. 건물의 불은 불꽃 애니메이션이 있는 것도 아니고 그냥 무작위로 불 스프라이트를 xor 연산한 것이 나타났다가 사라지기를 주기적으로 반복하는데, 그래도 기술적인 단순함에 비해 불 같은 느낌이 살짝은 난다. 색깔을 나타내는 숫자의 한 비트만을 xor시킨 것으로 보인다.
또한 구급대는 일체의 스프라이트가 존재하지 않으며, 좌우 화살표를 누를 때마다 좌중우 세 위치 중 하나로 곧바로 워프할 뿐이다. 이 정도 게임은 걍 GWBASIC으로도 만들 수 있지 않을까 싶을 정도.
그리고 그런 의심이 더욱 강하게 드는 이유가 뭐냐 하면.. 이 프로그램은 실행 직후에 불, 아기, 구급대 같은 그래픽만 화면에 잠깐 나타났다가 사라지기 때문이다.
도스 시절의 BASIC 프로그래머라면 이건 화면에 그려진 그래픽 내용을 버퍼에다 저장하는 GET 명령을 호출하는 준비 과정과 유사함을 눈치 챌 수 있을 것이다.
난이도가 올라가서, 한 아기가 완전히 구급차로 가기 전에 또 5층에서 아기가 떨어지기 시작하면 구급대는 그야말로 좌우로 축지법을 써야 하게 된다. 옛날 도스용 라이온 킹 게임의 스테이지 중간 보너스 게임으로 있던 Bug Toss와 비슷한 방식이다.
게임 화면에서 고개를 좀 갸웃거리게 하는 것은.. 잔기를 표시한 방식이다.
저 게임에서 미스는 두 말할 나위 없이, 떨어지는 아기를 하나라도 놓쳐서 땅에 떨어뜨리는 것이다. 그런 사고를 낼 때마다 잔기가 하나씩 줄어들며, 모든 잔기가 떨어지면 게임 오버가 된다.
그런데 게임에서는 그 잔기를 아기 모양으로 표시해 놓았다. 아기 모양은 차라리 한 스테이지당 구해야 하는 아기의 수를 나타내고, 스테이지가 진행될수록 그 남은 수가 줄어들게 하는 게 자연스럽지 않을까? 아기 모양으로 "허용되는 미스의 수"를 표기한 건 좀 직관적이지 못해 보인다.
물론 나도 말은 그렇게 했지만 근본적으로 아기를 떨어뜨린다고 해서 저 구급대원이 당장 다치거나 죽는 건 아니기 때문에, 이런 게임 체계에서는 뭔가 다른 대안을 떠올리기도 쉽지 않아 보인다.
뭐, 이런 게임도 있다 싶어서 소개해 보았다.
개발자는 Dave Baskin이라고 알려져 있으나, 동명이인이 많을 뿐만 아니라 직접적으로 이 게임과 프로필이 연결되어 있는 사람을 찾지 못해서 개발자가 지금은 뭘 하고 있는지 알기가 어렵다.
3. Alley Cat (1983)
그리고 그 이름도 유명한 Alley Cat. 얘는 게임 자체와 개발자 모두에 대해서 본인이 이미 심층분석을 한 적이 있기 때문에 이 글에서 또 상세히 다루지는 않겠다.
비슷한 시기에 나온 위의 두 게임과 비교해 보니 Alley Cat이 당시로서는 창의적인 명작 대작이었는지가 실감이 가지 않는가? (비록 Alley Cat은 전적으로 1인 기획은 아니었고, 다른 사람이 만들던 것을 Bill Williams가 물려받은 형태이지만)
다른 게임에 비해 얘는 일단 길거리, 집안, 최종 보스 퀘스트 등 현실 세계과 초현실 세계를 드나들면서 장면 내지 컨텐츠 자체가 엄청 많이 존재한다.
예전 글에도 적혀 있듯, 이 게임의 개발자는 훗날 게임 업계를 은퇴한 뒤 신학을 시작했다. 그러나 유전병을 갖고 있던 게 도져서 30대 후반의 나이로 세상을 떠났다. 생년과 몰년이 pkzip의 개발자인 필립 카츠와 비슷해서 비교된다는 점까지 언급한 바 있다.
* 그나저나 옛날에는 마우스가 없어도 조이스틱은 있었는지.. 그 시절엔 조이스틱을 어느 포트에다 연결해서 어떻게 썼는지 참 궁금해진다.
도스용 고전 게임들 중에서도 조이스틱을 지원 안 하는 물건은 거의 없다시피했기 때문이다.
Posted by 사무엘