2018년 여름 현재 날개셋 한글 입력기의 차기 버전인 9.5가 개발 중이다. 지금까지 수 차례 연기와 번복을 거듭해 왔지만, 9.5는 정말로 완전체 파이널 버전이 될 것이 명확해지고 있다. 작업해 놓은 것을 정리해 보니 분량이 이렇게 길어질 줄은 몰랐다.
9.5 이후로는 버전업을 하더라도 그 주기가 지금보다 더 길어질 것이며, 지금 같은 장기적인 개발 계획 없이 그때 그때 생긴 아이디어 반영이나 문제점 개선 위주로만 가볍게 새 버전이 나올 것이다. 2000년에 나왔던 1.0 이래로 18년이 지나서야 이제 좀 한글 입력기가 물건다운 물건이 완성된 것 같다.
1. '조합 안에 조합 생성' 입력 도구의 변화
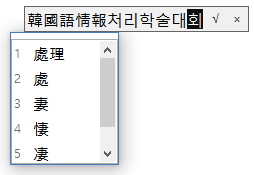
날개셋 한글 입력기의 차기 버전에서는 9.3에서 첫 도입되었던 입력 도구의 모습이 이렇게 미묘하게 바뀌었다.
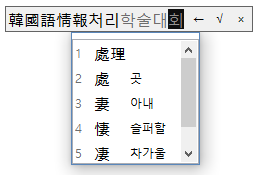
- 후보 목록이 언제나 입력란의 왼쪽 끝에 표시되는 게 아니라("한국어"), 실제로 삽입되는 위치("처리") 근처에 표시되게 했다.
- '한글 단어를 한자로' 변환 기능의 경우, 낱글자에 대해서는 한자의 훈도 표시되게 했다. (곳, 아내, 슬퍼할.. 등)
- 지금 변환 가능한 영역("처리")과 그렇지 않은 영역(그 이후 "학술대회")을 검정 vs 회색으로 구분해서 표시하게 했다.
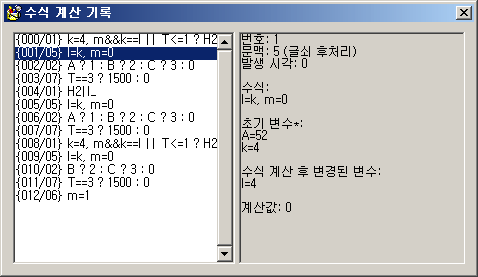
눈에 띄지 않는 개선 사항은 다음과 같다. 한글 조합 상태와 관련해서 여러 미묘한 버그들을 발견해서 잡았다.
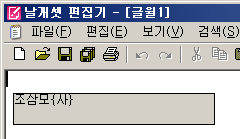
- 이미 한자로 변환되어 있는 곳으로 cursor를 옮기면 무조건 모든 한자들이 도로 한글로 돌아가는 게 아니라, 예전에 변환했던 단위로만 역순으로 복귀되게 했다. 예를 들어, 위의 그림과 같은 상태에서 마지막 한자인 '보(報)'를 건드리면 '정보'만 한글로 돌아가고 '한국어'는 아직 한자로 유지되어 있다.
- 평범한 왼쪽 화살표나 backspace 말고 특수글쇠(앞 글자 달라붙기 같은)의 기능으로 cursor를 움직여서 앞의 한자를 건드렸을 때는 한글 복귀가 제대로 되지 않던 버그를 잡았다.
- 저런 특수글쇠로 비한글 문자 사이를 왕래할 때 cursor가 일시적으로 사라지고 보이지 않던 버그를 잡았다.
- 한글을 조합하던 중에 글자판을 변경했을 때 조합이 종료되지 않던 버그, 맨 마지막 글자가 아니라 중간에서 한글을 조합하고 있다가 한자를 선택했을 때(예: '훈(민)정' 조합 중에 訓民) 변환이 제대로 되지 않던 버그를 잡았다.
2. '고급 입력 스키마 - 고급 글쇠 인식' 기능의 변화
지난 7.4에서 첫 도입되고 나서 별다른 변화가 없었던 '고급 입력 스키마'에 간단한 modifier key 필터링 기능이 추가됐다.
지금까지는 얘를 이용해서 D 같은 문자 글쇠에다가 입력 기능을 배당하고 나면, Shift+D는 말할 것도 없고, 심지어 Alt+D 같은 걸 눌러도 글쇠가 아무 구분 없이 인식하고 동작해 왔다. (Alt 인식이 불가능한 외부 모듈 구현체는 제외)
얘는 말 그대로 저수준 고급 글쇠 인식 기능이기 때문에, modifier의 인식 여부는 modifier 글쇠 자체가 눌렸을 때 변수와 수식을 이용해서 사용자가 알아서 처리하라는 게 취지이긴 하다. 하지만 저건 너무 고지식하다고 여겨져서 Shift, Ctrl, Alt에 대해서 인식 여부를 사용자가 지정할 수 있게 했다.
물론 이건 단축글쇠 규칙만치 세밀하지는 않기 때문에 modifier 글쇠의 좌우까지 구분하는 기능은 없다. 고급 입력 스키마는 A, S, D 같은 인접한 글쇠가 동시에 눌린 것, B를 길게 누른 것, C를 눌렀다가 뗀 것 같은 이벤트를 감지하는 것이 목적이지, 단축글쇠처럼 왼쪽 Shift+L, Ctrl+Win+X 이런 combination을 세밀하게 감지하는 게 일차적인 목표가 아니기 때문이다.
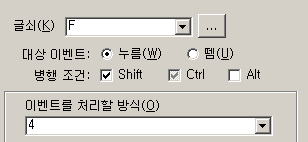
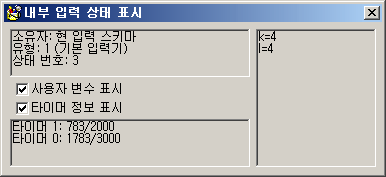
modifier key 필터링 여부를 지정하는 체크 박스는 on/off뿐만 아니라 indeterminate라는 제3의 상태도 있는데(위의 그림에서 Ctrl), 이게 바로 예전처럼 modifier가 눌렸든 안 눌렸든 따지지 않는다는 뜻이다. D와 Shift+D에 대해서 동작을 구분하고 싶다면 Shift는 indeterminate로 맞춰 놓고 별도의 변수로 상황을 구분하면 된다.
Shift는 몰라도 Ctrl과 Alt는 단축글쇠와 충돌하지 않으려면 사실상 언제나 off로 지정해 놓는 게 좋을 것이다. 단축글쇠 옵션에는 좌우 중 무엇을 눌렀는지 구분하지 않는다는 옵션이 있을 뿐, 아예 on/off 여부를 구분하지 않는 옵션이 있지는 않다. 이 역시 대조적이다.
modifier key 필터링은 key down에 대해서만 동작한다. key up은 key down 이벤트에 걸렸던 글쇠가 떼졌다면 그 당시의 modifier와 관계 없이 언제나 동작한다. 키보드가 무슨 마우스 버튼도 아닌데.. A키를 그냥 뗐을 때는 이렇게 동작하고, Shift가 눌러진 상태에서 뗐을 때는 이렇게 동작하는.. 그런 상황은 고려하지 않기로 한 것이다. 그런 기능을 굳이 구현해야겠다면 역시 변수와 수식을 이용해서 사용자가 직접 구현하면 된다.
3. '고급 입력 스키마' 기능의 변화
오랫동안 빈 공간이 많아 황량하고, 별로 자주 쓰이지도 않는 옵션밖에 없던 '고급 스키마 옵션' 탭에 유의미한 옵션이 하나 추가되었다. 바로 '비한글 문자가 입력되어도 기존 한글 조합을 일시적으로 보존'해 주는 기능이다.

타자를 빠르게 하다 보면, 한글을 조합하고 있고 한글 입력과 관련된 글쇠들이 미처 다 떼어지기 전에 space나 쉼표 마침표 같은 문자 글쇠가 먼저 눌러질 수 있다. 이 경우 "ㄷ.ㅏ", "르 ㄹ" 같은 오타가 생기기 쉽다.
허나, 이 옵션이 지정되면 입력 스키마가 이런 비한글 문자를 문자 생성기(한글 입력 오토마타)로 곧장 보내지 않고, 한글의 옆에다가 임시로 붙여 준다. 즉, "다."처럼 된 상태에서 "당. "으로 한글 조합을 계속할 수 있다.
그렇게 있다가 모든 글쇠에서 손이 떼어지고 나면 조합이 종료된다.
이거 간단한 발상이지만 생각보다 꽤 유용하다. 오동작 부작용도 거의 없고 말이다. (물론 공백까지 저렇게 보정이 되게 하려면 '글쇠 및 변수 옵션'의 '추가로 인식할 글쇠'에다가 space도 0x20으로 추가해 줘야 한다.)
스크린샷에서 보다시피, 여는 괄호 계열에 속하는 (<[{ 이런 것은 같이 눌러졌을 때 한글의 뒤가 아니라 '앞'에 붙도록 별도의 옵션을 줄 수도 있다.
이미 옆에 붙은 글자가 있는 상태에서 또 비한글 문자가 입력되면, 이 기능은 그것까지 추가로 붙여 주지는 않는다.
단지, 이미 붙었던 글자를 없애고 새로 들어온 문자로 대체하도록 할 수는 있다. '중복 입력 허용' 옵션은 그렇게 동작 방식을 바꾸는 역할을 한다.
이 기능은 여러 글쇠의 keydown과 keyup을 감지해서 동작하기 때문에 고급 스키마에서 담당하고 있으며, 한편으로 한글과 비한글이 섞인 가변 길이의 조합을 표시하기 때문에 문자 생성기도 '고급 입력기'와 연계해서 동작한다. 정말 말 그대로 고급스러운 기능인 셈이다. 기본 입력기만 사용하고 있을 때는 이 옵션이 사용 불가 상태로 표시된다.
4. 한글 입력 엔진 쪽의 변화
(1) 오토마타 중에서 'xxx 처리 후 조합 중단'을 의미하는 -6, -9 같은 마이너한 기능들이.. 조합이 완료된 한글 뒤에 쓰레기 문자를 삽입하기도 하던 버그를 고쳤다.
그리고 마지막 두 타의 입력 순서를 교환하는 꽤 어려운 -11도 복잡한 상황에서 제대로 동작하지 않던 버그를 고쳤으며, 이 기능은 더 전문적인 특수글쇠에다가도 구현해 넣었다.
(2) 오토마타의 O 변수는 지금까지 입력 글쇠 또는 현재 조합 중인 한글의 종류가 두벌식인지 여부를 비트 1|2 플래그 형태로 갖고 있는데, 이 뿐만이 아니라 지금 한글 조합이 처음부터 사용자의 타자로 입력된 건지 아니면 프로그램에 의해 자동 재현되었는지(4)에 대한 정보도 추가했다.
달라붙었거나 특수글쇠 같은 걸로 재구성된 조합에는 O 변수에 4라는 비트값도 추가되어서 나온다. 그래서 사용자가 처음 한글을 입력할 때는 모아치기 오토마타를 사용하는데, 달라붙은 한글에 대해서는 더 세밀하게 무한 낱자 수정을 사용한다거나 식으로 오토마타를 구성할 수 있다.
(3) C0|0x23이라고 직전 두 글쇠의 입력 순서를 교환하는 특수글쇠를 추가했다.
이건 더 말이 필요하지 않다. 'ㄷ.ㅏ'를 '다.'로, 특히 두벌식 자판에서는 '뭥미'를 '뭐임'으로, '생리'를 '새일'로, 'ㅇ버'를 '업'으로 바꿔 준다. 물론 앞 글자의 조합 상태를 마음대로 넘나들고 바꾸기 위해서는 날개셋 편집기나 MS Word 같은 환경이 필요하다.
두벌식 자판은 구조적으로 동시치기를 구현하기 힘들다 보니, 순서가 뒤바뀐 오타는 이런 식으로 강제 보정하는 것밖에 방법이 없다. 내가 테스트를 해 보니.. 순서가 뒤바뀌는 오타가 날 정도이면 그 오타 이후에도 타자가 여러 타가 진행되어 버리는 편이기 때문에 이런 보정 특수글쇠를 적절한 타이밍에 누르는 것도 그리 쉽지 않을 것 같다. 하지만 이 기능이 없는 것보다는 있는 것이 나으리라고 본다.
이전에 추가되었던 C0|0x22도 원래는 이걸 의도했었으나, 기술적인 난이도 때문에 기능을 온전히 구현하지 못했다. 그래서 글쇠의 교환이 아니라 글자 전체의 위치 교환 수준에 그쳤었다.
5. 편집기의 미세한 버그 수정
이제 더 고칠 게 없을 거라 여겨지는 편집기에서 의외로 버그가 몇 개 발견되어 고쳐졌다. 그것도 직전 버전에만 있던 게 아니라 꽤 오래된 버그들이다.
- 이전 글에서 언급한 대로, 24픽셀 글꼴을 사용하고 있는데 일본어· 중국어 IME의 조합을 나타내는 밑줄(점선이나 실선..)이 여전히 16픽셀 기준 높이로 취소선처럼 잘못 표시되던 문제를 해결했다.
- 아주 미묘하고 발견하기 어려운 버그이긴 한데, 도구모음줄의 세로 폭이 실제보다 더 크게 잘못 계산되어서 아랫부분이 제대로 갱신되지 않고 가로줄 모양의 잔상이 생기는 걸 보신 분이 있으려나 모르겠다. 그런 현상이 절대로 발생하지 않게 조치를 취했다.
- 이건 사용자의 데이터를 파괴할 수 있는 치명적인 버그이다. UTF-16LE가 아닌 다른 인코딩으로 파일을 저장할 때 크기가 수MB(대략 2MB) 정도를 넘어가면 그 2MB 정도의 경계에 속하는 줄이 낮은 확률로 사라질 수 있는 문제가 있었다. 언제나 발생하는 건 아니고 좀 복잡한 조건이 우연히 충족됐을 때만 발생하기 때문에 문제가 이제야 발견되었다.
6. 사소한 UI 개선 사항
(1) 날개셋 제어판에서 어떤 글자판(입력 항목)에 어떤 입력 스키마와 어떤 문자 생성기를 배당할지--빈/기본/고급-- 지정하는 부분의 명칭은 지금까지 아주 오랫동안 "이 입력 항목의 기반 루틴"이었다.
허나, '루틴'이라는 말이 엔지니어가 아닌 일반 사용자 입장에서는 굉장히 어색하고 생뚱맞아 보여서 이걸 '기능 수준'이라고 바꿨다. '빈/기본/고급'이 기능의 수준을 결정하는 것이기 때문이다.
이것 말고 '기술 기반', '기술 수준' 등의 용어도 고려하다가 최종적으로는 "기능 수준"이라고 말을 정했다.
또한 날개셋 한글 입력기가 제공하는 날개셋문자의 종류로는 일반 문자, 세벌식/두벌식 한글 등이 있는데.. 특수글쇠의 명칭이 '특수 코드'라고도 혼용되고 있어서 이를 없앴다. 그냥 '특수글쇠'로 통일했다.
(2) 굉장히 사소한 변화이다만.. 날개셋 편집기에서 다수의 블록을 잡은 뒤 날개셋 외부 모듈로 텍스트 필터를 사용할 때, 블록이 4개까지만 인식되고 5개째 이상부터는 필터 변형이 되지 않던 문제를 해결했다.
이것도 거의 10년 가까이 전부터 변함없이 존재하던 문제였지만, 여파가 워낙 미미하기 때문에 지금까지 방치돼 있었다. 애초에 외부 모듈에서 텍스트 필터는 TSF A급 프로그램이 아닌 곳에서는 사용조차 할 수 없기 때문에 더욱 존재감이 없다..
이 문제를 해결하기 위해 날개셋 편집기가 바뀌어야 할지, 아니면 외부 모듈이 바뀌어야 할지는 난 정확하게 잘 모르겠다. Windows의 TSF 스펙이란 게 한 치의 모호성 없이 명확하게 정의돼 있지 않기 때문이다. 하지만 외부 모듈이 문제를 피해 가는 것이 당장 더 간단하기 때문에 그것부터 조치를 취했다.
일단 내가 주변에서 보는 텍스트 에디터나 워드 프로세서 중에서 불연속적인 다수의 블록을 잡을 수 있는 프로그램 자체가 날개셋 편집기와 MS Word밖에 없다. 하지만 Word는 여전히 외부 모듈에다가 자기가 갖고 있는 모든 블록의 내용을 넘겨주지 않기 때문에 이 기능이 직통으로 동작하는 프로그램은 같은 계열의 날개셋 편집기밖에 없다. 레퍼런스로 삼을 프로그램이 이것밖에 없으니 편집기와 외부 모듈 중 무엇을 고쳐야 할지를 판단하기가 더욱 어려웠다.
(3) 이것도 아주 사소한 변화이긴 하다만, 프로그램이 제공하는 모든 대화상자들을 꼼꼼히 검토했다. 그래서 버튼들만 쭉 나열돼 있는 곳에서 좌우 화살표를 누르면 성격이 같은 것들끼리 포커스가 순환되게 했다. 여기서 버튼이라는 건 '확인/취소' 같은 누르는 버튼뿐만 아니라 라디오· 체크 버튼까지 포함이다.
옛날에 이걸 한번 정비한 적이 있었지만 세월이 흐르면서 그 규칙이 깨진 부분이 다시 많이 생겨 있었다.
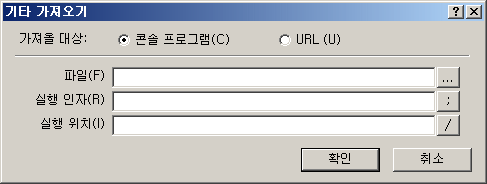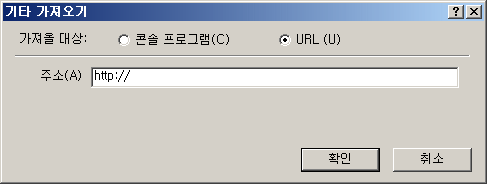
(4) 편집기의 '삽입-기타 가져오기' 대화상자도 해당 기능이 처음으로 도입됐던 3.0 이래로 변화가 없다시피했을 텐데..
콘솔 프로그램을 골랐을 때는 파일 경로와 인자, URL일 때는 주소.. 이렇게 각 방식에 필요한 추가 정보만 그때 그때 화면에 표시되게 외형을 바꿨다. 그 결과 대화상자의 크기도 약간 더 작아졌다.
7. 날개셋문자의 0문자 처리
끝으로.. 말이 나온 김에 이번 기회에 규약을 확실하게 정했다.
한글, 일반 문자, 특수글쇠 등.. 각 종류별로.. 종류만 그렇게 정하고 내부 코드값은 아무것도 없는 0인 날개셋문자를 줬을 때 어떤 일이 일어나느냐 하는 것이다.
물론 뭔가 크게 대단한 일이 발생하는 건 아니다. 다만, 한글을 조합 중인 상태에서 0번 일반 문자가 입력되면 조합만 종료된다. 그도 그럴 것이 일반 문자는 그 정의상 한글 조합을 무조건 종료시키고, 0번 문자는 '문자 없음'을 의미하기 때문에 조합만 종료되는 효과가 나는 것이 자연스럽다.
한글 기반이면서 초중종 세 성분이 모두 0인 날개셋문자는 한글 조합을 전혀 건드리지 않고 그 상태를 유지시킨다. 다만, 조합 중이던 한글의 타입은 바뀔 수 있다. 가령, 두벌식으로 '각'을 입력하고 나서 세벌식 기반의 0문자를 입력하면 조합 중이던 문자의 외형은 동일하지만 내부적인 속성이 두벌이 아닌 세벌로 바뀐다. 그렇기 때문에 다음에 두벌식 모음 'ㅏ' 같은 걸 입력하더라도 도깨비불 현상이 일어나서 '가가'가 되지 않고 그냥 '각ㅏ'가 된다.
이런 경우와 달리, 특수글쇠 0문자는 그 어떤 side effect 없이 언제나 현행 조합 유지인 것이 반드시 보장되게 했다.
글쇠 수식에서 조건부로만 무언가가 입력되고 조건이 충족되지 않을 때는 지금 입력을 그대로 놔두고 싶으면 특수글쇠 0문자를 의미하는 C0|0을 배당하면 된다. 단, 텍스트 에디터의 입장에서는 아무 동작도 안 하는 게 아니라 조합 문자열을 덮어쓰는 동작이 발생하기 때문에.. 외형상 텍스트가 바뀐 게 없더라도 텍스트가 변경됐다는(modified) 판정을 받을 수 있다.
Posted by 사무엘