지난번 상편에서는 Windows에서 인쇄 기능을 코딩으로 구현하는 절차와 인쇄 관련 기본 개념과 동작들을 살펴보았다. 이번 하편에서는 상편에서 분량상 모두 다루지 못한 인쇄 관련 추가 정보들을 한데 늘어놓도록 하겠다.
1. 인쇄 관련 공용 대화상자들
우리가 Windows에서 가장 자주 접하는 공용 대화상자는 아마 파일 열기/저장 대화상자일 것이다. 이것 말고도 글꼴 선택 내지 색깔 선택 대화상자가 있으며, 인쇄 대화상자도 그 중 하나이다.
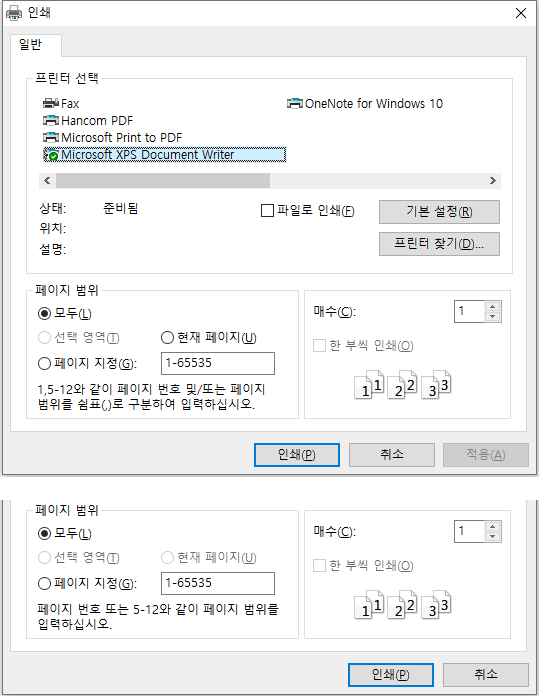
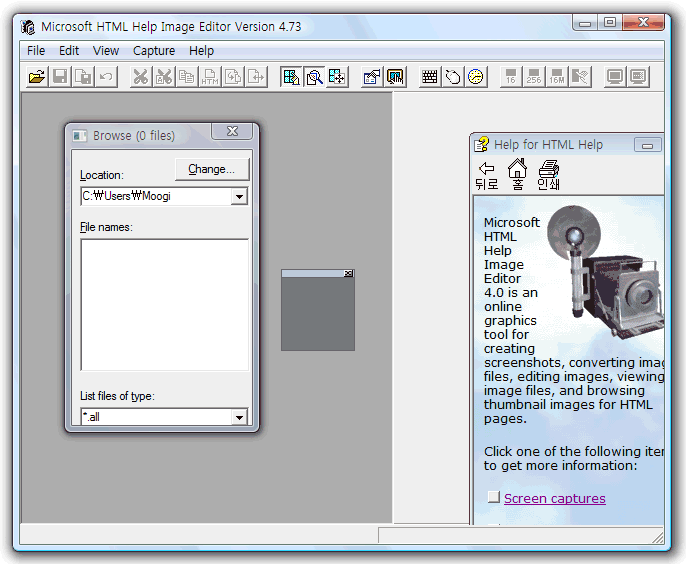
인쇄를 지원하는 대부분의 프로그램에서 Ctrl+P를 눌러서 쉽게 보는 인쇄 대화상자라는 건 위와 같이 생겼다. 기본적으로 ‘일반’이라는 탭 하나밖에 없지만, 추후 확장과 사용자의 customize 가능성을 염두에 두고 프로퍼티 시트 형태를 하고 있다. 20년 전, Windows 2000 시절부터 저런 형태가 도입되었다.
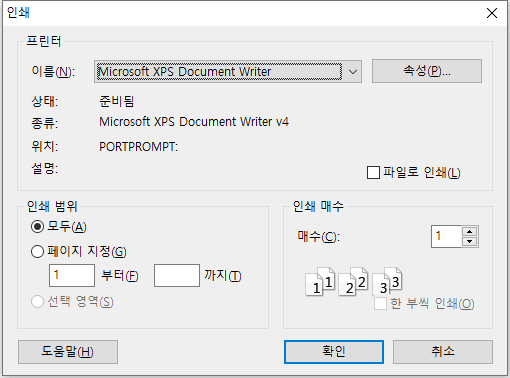
하지만 Windows 9x 내지 더 옛날 16비트 시절에는 인쇄 대화상자가 전통적으로 위와 같은 모양이었다. 외형상 가장 큰 차이는 프로퍼티 시트가 아닌 일반 대화상자 형태이고, 프린터 목록이 리스트 컨트롤이 아니라 콤보 상자라는 점이다. 지금도 좀 옛날 프로그램에서는 요런 모양의 대화상자를 여전히 볼 수 있다.
인쇄 대화상자로 할 수 있는 일은 크게 (1) 인쇄를 내릴 프린터를 선택하고, (2) 각 프린터별로 용지의 종류와 방향, 여러 부 인쇄 방식 등을 지정하고, (3) 인쇄할 페이지 영역을 지정하고, (4) 최종적으로 인쇄 명령을 내리는 것이다.
하는 일이 생각보다 많기 때문에 옛날에는 인쇄 대화상자를 약간 간소화시켜서 (2)만 지정할 수 있는 “프린터 설정” 대화상자라는 게 따로 있기도 했다. 아래처럼 말이다.
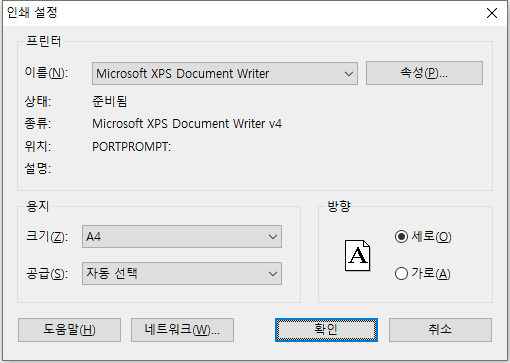
Windows 말고 아래아한글만 해도 먼 옛날 도스 시절에는 Alt+P는 인쇄 대화상자이지만 Ctrl+P는 프린터 설정이었다는 걸 생각해 보자.
하지만 Windows 2000 스타일의 최신 인쇄 대화상자에서는 인쇄와 프린터 설정이 한데 통합되었다. 어떻게..?? 기존의 '프린터 설정'은 자신의 상위 호환인(superset) 인쇄 대화상자를 '적용'만 누른 뒤 '취소'로 닫는 것으로 퉁친 것이다. 이 때문에 인쇄 대화상자는 딱히 modeless가 아닌 modal 형태--자신이 떠 있는 동안 부모 윈도우로 포커스를 옮길 수 없음--임에도 불구하고 '적용' 버튼이 따로 있는 것이다.
MFC에서는 기본 구현돼 있는 인쇄 기능만 사용하는 경우, 오늘날의 2019 최신 버전까지도 의외로 옛날 스타일의 인쇄 대화상자가 계속해서 나타난다. CPrintDialog는 PRINTDLG 구조체 기반이며, 최신 스타일 대화상자를 지원하려면 PRINTDLGEX 기반인 CPrintDialogEx를 사용해야 한다. 최신 스타일이 도입되면서 내부 동작이 많이 바뀌고 바이너리 호환성이 깨졌기 때문에 Ex 클래스는 오리지널 클래스의 파생형이 아니며, 서로 호환성이 없다.
MFC 없이 Windows API만 사용한다면 재래식 PRINTDLG 구조체만 사용하더라도 최신 스타일 대화상자가 나오게 하는 것 자체는 가능하다. 대화상자 템플릿을 customize하는 것 없이 기본 멤버만 사용한다면 말이다.
그러나 구형 구조체와 구형 API만 사용해서 나타난 최신 대화상자에는 ‘적용’ 버튼이 나오지 않는다. 구형 API에는 함수 리턴값 차원에서 그런 응답 자체가 존재하지 않았기 때문이다.
아울러, 인쇄할 영역을 단순히 x~y쪽이 아니라 x1~y1, x2~y2 이런 식으로 여러 개 지정하는 것도 구형 API로는 불가능하다. 해당 구조체 멤버가 존재하지 않기 때문이다. 이런 식의 제약이 있다.
다음은 관련 여담이다.
(1) PrintDlg 내지 PrintDlgEx의 실행이 성공하면 프린터 DC뿐만 아니라 DEVMODE 내지 DEVNAMES 구조체 내용을 담고 있는 global 동적 메모리 핸들도 돌아온다. 현재 선택된 프린터에 대해서 지정한 용지 등의 설정들이 여기에 저장되기 때문에 응용 프로그램이 이 핸들을 잘 관리하고 있어야 한다. 그래서 다음에 인쇄 기능을 호출할 때 요걸 넘겨줘야 기존 인쇄 설정이 보존된다.
(2) 인쇄 대화상자 말고 용지 설정 대화상자라는 것도 있지만 이건 잘 쓰이지 않는다. 용지 종류와 방향, 상하좌우 여백 정도는 공통이겠지만 그 뒤로 인쇄 내용을 배치하는 방식들은 응용 프로그램들마다 같은 구석이 별로 없기 때문이다. 당장 워드패드, 메모장, 그림판만 해도 용지 설정 대화상자의 모양은 전부 제각각이다.
(3) 운영체제에 설치된 글꼴들을 조회하는 것처럼, 현재 설치돼 있는 프린터들을 조회하는 API도 있다. 인쇄 대화상자를 꺼내지 않고 내 대화상자의 한구석에다가 프린터 목록 같은 걸 마련하고 싶다면 이런 API를 쓰면 된다. 하지만 현실에서 사용할 일은 거의 없을 것이다.
(4) “인쇄 중” 대화상자라든가 “인쇄 미리보기(화면 인쇄)” 같은 건 공용 대화상자 버전이 존재하지 않으며, MFC의 경우 자체 구현돼 있다. 오늘날은 인쇄 진행 상황 같은 건 위대하고 전능하신 task dialog로 너무나 깔끔하게 구현할 수 있을 것이다.
그리고 인쇄 미리보기는 여느 대화상자와 달리 꽤 큰 공간이 필요한 관계로, 전통적인 modal 대화상자보다는 프로그램 주 화면에다가 곧장 미리보기를 표시하는 식으로 디자인이 바뀌는 추세이다. 요즘 MS Office 프로그램들이 대표적인 예이다.
2. 플로터
먼 옛날 한 1980~90년대쯤에 컴퓨터 개론 교양 서적에서는 컴퓨터의 출력 장치로 모니터, 프린터와 더불어 플로터라는 물건도 소개되어 있었다. 플로터는 로봇 팔 같은 게 달려서 종이에다가 도면을 말 그대로 '그려 주는' 장치이다.
덕분에 얘는 직선이나 곡선 하나는 무한한 해상도로 원본 그대로 정확하게 그릴 수 있다. 잉크를 적절히 배합해서 컬러 표현도 가능하다.
하지만 장점은 그걸로 끝.. 인쇄 속도가 도트 프린터 이상으로 끔찍하게 느리며(비록 도트 프린터처럼 시끄럽지는 않지만), 속이 채워진 도형이나 비트맵 같은 그림을 표현할 수 없다.
실제로 플로터를 가리키는 DC에다가 GetDeviceCaps(hDC, RASTERCAPS)를 호출해 보면 RC_BITBLT가 가능하지 않다는 응답이 올 것이다. 비트맵 전송을 할 수 없고 천상 원과 직선과 곡선 그리기나 하라는 소리이다.
일반 가정집이나 사무실에서 A4 용지에다가 인쇄하는 거라면 그냥 닥치고 일반 프린터만 쓰면 된다. 하지만 플로터는 프린터가 범접할 수 없는 A1 같은 엄청나게 큰 종이에다가 도면을 그릴 수 있으며, 펜 대신 커터 같은 걸 꽂아서 선 궤적대로(가령 글자의 윤곽선) 종이를 오려낸다거나 하는 용도로도 활용 가능하다는 것에 존재 의의가 있다. 즉, 산업용으로 마르지 않는 수요가 있다.
하긴, Windows에도 트루타입도 비트맵도 아니고 Modern, Roman, Script처럼 내부가 채워지지 않은 선으로만 구성된 '벡터 폰트'가 있었다. 실용적인 쓸모가 전혀에 가깝게 없는 완전 잉여인지라, 요즘 어지간한 프로그램의 글꼴 목록에서는 조회조차 되지 않을 것이다. 이런 게 바로 플로터용 글꼴이다. 물론 프린터에서도 쓸 수 있지만..

옛날에 도스용 터보 C의 BGI에도 비트맵 말고 벡터 글꼴 컬렉션이 있었다. 큰 크기에서는 내부가 채워지지 않고 선만 그어졌으며.. 힌팅이 없어서 작은 크기에서는 영 보기 좋지 않았으니 반쪽짜리인 건 동일했다. 비트맵 같은 계단 현상만 없을 뿐 다른 방면으로 단점투성이였다.
3. 프린터 드라이버의 가상화
컴퓨터라는 기계는 개나 소나 다 “물리적으로는 없지만 그래도 일단 있다고 치자”라고 넘기는 가상화가 통용되는 동네이다. 메모리는 진작부터 가상화하고 지내고 컴퓨터 자체도 가상 머신, 그리고 iso 같은 광학 디스크는 뭐.. 이제 운영체제(드라이브 마운트)와 압축 유틸조차(생성) 정식으로 지원하는 세상이 됐다.
그러니 프린터도 당연히 가상화의 대상이다. 당장 내 자리에 프린터가 존재하지는 않지만 어떻게든 인쇄를 하는 방법은 크게 두 가지인데, 하나는 그냥 pdf나 xps 같은 파일로 인쇄하는 것이고 다른 하나는 원격 프린터에 네트워크로 연결해서 인쇄하는 것이다. 한때는 컴퓨터조차 한데 공유하는 자원이고 각 사용자는 단말기로 접속만 하던 시절이 있었지만 지금은 프린터 정도나 사무실 같은 데서 여러 컴퓨터들이 한데 공유한다는 점이 흥미롭다.
옛날에는 PC에 Windows 운영체제만 달랑 설치하고 나면 프린터가 잡힌 게 없었다. 프린터는 네트워크나 비디오/오디오 장치만치 필수는 아니니까..
기본 프린터가 없는 컴퓨터에서는 어지간한 프로그램에서 인쇄 미리보기 기능조차 동작하지 않았다. 프린터 공급 용지의 크기를 알 수 없기 때문이다. 하지만 Vista부터는 xps 문서 생성기라는 드라이버가 기본 연결되어 저런 광경을 볼 일은 없어졌다.
pdf/xps가 대중화되기 이전에도 "파일로 인쇄"라는 개념 자체는 마치 "램 드라이브"와 비슷한 위상으로 존재했으며, 지금도 인쇄 대화상자의 옵션으로 존재한다. 인쇄할 내용이 저장된 컴퓨터와 프린터가 연결된 컴퓨터가 서로 일치하지 않을 때 파일로 인쇄하는 기능이 꼭 필요하지 않겠는가?
하지만 지난번 글에서도 잠시 언급했듯이 이런 파일 인쇄 결과는 특정 프린터 기종에 종속적이기 때문에 범용성이 떨어진다. 본인도 저걸 활용한 적은 거의 없었던 것 같다. 그 대신 오늘날은 위지윅만 보장되고 물리적인 프린터의 구조와는 철저하게 독립적인 전자 문서 파일 포맷이 활발히 쓰이고 있다.
우리나라는 인터넷으로 은행 거래나 공문서 발급 같은 걸 받을 때 보안 ActiveX들을 잔뜩 설치해야 해서 원성이 자자하다. 그래서 이런 사이트 접속 전용으로 ActiveX 설치 총알받이 가상 머신을 만들려고 해도 안 되는 경우가 많다. 반드시 본머신(?)만 쓰라고 강요하면서 가상 머신에서는 설치되기를 거부하는 매우 악랄한 ActiveX도 있기 때문이다.
그것처럼.. 증명서 같은 것을 인쇄하는 전용 프로그램의 경우, 가상 프린터인 건 또 어떻게 감지하는지 pdf 같은 파일 생성은 거부하는 경우가 대부분이다.
가상 CD를 감지하는 프로그램은 못 봤는데 프린터와 PC는 어째 감지하는지? 신기한 노릇이다. 하드카피 종이 인쇄는 뭐 변조 못 할 줄 아나..;; 어차피 원본대조필 워터마크가 필요한 건 똑같을 텐데.
한편, 가상 프린터 드라이버라는 게 파일 아니면 네트워크만 있는 건 아니다. 예전에는 FinePrint라고 인쇄되는 데이터를 인위로 보정해서 1페이지에 여러 페이지 내용을 축소해서 인쇄한다거나, 잉크의 농도를 인위로 줄이는.. 뭐랄까 메타 프린터 드라이버 유틸이 있었다. 최종 목적지는 물리적인 프린터이지만 그 사이에 중재를 한다는 것이다.
하지만 요즘은 축소 인쇄라든가 잉크 절약 모드는 프린터 드라이버 차원에서 기본 제공되는 옵션이 돼서 그런 메타 드라이버의 필요성이 많이 줄어든 게 사실이다.
또한, 레이저 프린터는 기술 배경이 복사기와 비슷하다 보니, 같은 페이지를 여러 부 인쇄하는 것을 소프트웨어가 아니라 프린터에게 맡기는 게 매우 능률적이다.
양면 인쇄를 위해 페이지별 인쇄 순서를 교묘하게 바꾸는 것도 해당 워드 프로세서/전자출판 프로그램, 심지어 메타 드라이버가 담당할 법도 하지만.. 요즘은 프린터 드라이버 차원의 옵션으로 자체 제공하기도 한다. 물론 파일로 인쇄할 때는 이런 것들은 전혀 고려할 필요가 없을 것이다.
4. 창 내용을 인쇄(?)하는 API
끝으로, 이것만 마지막으로 언급하고 글을 맺도록 하겠다.
Windows에서 화면에 표시돼 보이는 각각의 창(윈도우!)들은 WM_PAINT라는 특수한 메시지가 왔을 때 invalid region과 BeginPaint - EndPaint 사이클에 맞춰 자기 내용을 그리는 일에 특화돼 있다. 이는 창 내용을 다시 그리라는 요청이 여러 번 반복해서 오더라도 그리는 건 한 번만 행해지고, 꼭 다시 그려야 하는 부분만 효율적으로 그리기 위한 조치이다.
그런데 가끔은 윈도우도 저런 사이클에 구애받지 않고, 특정 DC가 하나 주어졌을 때 묻지도 따지지도 말고 거기에다가 자기 모습 전체를 있는 그대로 싹 다시 그리게 하고 싶을 때가 있다.
이럴 때를 위해 운영체제는 WM_PRINT 및 WM_PRINTCLIENT라는 메시지를 정의하고 있다. 이건 어지간한 Windows 프로그래머라도 접하거나 구현해 본 적이 거의 없는 듣보잡일 것이다.
그런데 Windows XP에서는 저 메시지로도 모자라서 하는 일이 거의 차이가 없어 보이는 PrintWindow라는 함수까지 추가됐다. 이건 뭐 WM_GETTEXT와 GetWindowText의 관계와 비슷한 것일까?
MSDN을 찾아보면..
- The PrintWindow function copies a visual window into the specified device context (DC), typically a printer DC.
- The WM_PRINT message is sent to a window to request that it draw itself in the specified device context, most commonly in a printer device context.
이라고 이런 물건들이 주로 인쇄용으로 쓰일 거라고 대놓고 문서화돼 있다. 하지만 현실에서 창 스크린샷 한 장 달랑 프린트 할 일이 얼마나 될까? 실제로는 이것들 역시 화면 출력용으로 쓰인다.
가령, alt+tab을 눌렀을 때 나타나는 각 프로그램 창들의 썸네일 말이다. 물론 Vista 이후부터는 DWM이 창들 화면을 하드웨어빨로 몽땅 저장하는 세상이 되긴 했지만, 그런 것 없이 invalid region과 무관하게 자기 모습 캡처 화면을 떠야 할 때는 저런 함수/메시지가 필요하다.
그리고 메뉴나 콤보 상자 목록이 스르륵 미끄러지며 표시되는 것 말이다. 이런 걸 구현하기 위해서도 WM_PAINT와 별개 계통인 그리기 전담 메시지가 쓰인다.
스르륵 미끄러지는 걸 구현한답시고 매 프레임마다 WM_PAINT가 날아온다거나 하지는 않는다. WM_PRINTCLIENT를 날려서 전체 리스트 모양을 메모리 DC에다가 한번 그려 놓은 뒤, 그걸로 애니메이션은 운영체제가 알아서 구현해 준다.
이런 걸 생각하면 창 핸들과 DC 하나 던져주고 print를 요청하는 메시지와 함수가 왜 필요하고 어떨 때 쓰이는지 약간 수긍이 갈 것이다. 하지만 그게 왜 하필 print라는 단어가 붙었으며 함수 버전과 메시지 버전이 모두 필요한지는 나로서는 아직도 잘 모르겠다.
Posted by 사무엘