뭐, 무식이 자랑이랄 수는 없겠지만,
본인은 전산학 내지 컴퓨터공학의 여러 분야들 중에서 문외한에 가깝게 제일 모르는 분야는 통신, 네트워크, 웹, 보안 쪽이다.
왜 제일 모르느냐 하면, 저건 컴퓨터 한 대만으로 독학이 가능하지 않고, 뭔가 '감'을 터득할 수 없는 분야이기 때문이다. 그래서 그런 걸 잘하는 사람들이 부럽다..
일례로 완전 최저수준 소켓 API와, 고수준 HTTP API 사이의 중간 과정에 대한 감이 전혀 없다. 후자도 분명 전자를 이용해서 구현됐을 텐데, 내부 구현이 어찌 돼 있는지 난 아는 게 없다.
그리고 네트워크 트래픽이 컴퓨터의 I/O 병목엔 어떤 영향을 끼치는지, 그 패킷이 어떻게 해서 한 운영체제 내부의 특정 응용 프로그램으로 잘 전달이 되는지, DDoS 공격이 서버 컴퓨터에 어떤 물리적인 영향을 끼쳐서 서버를 뻗게 할 수 있는지, (아님 단순히 프로세스/스레드의 무한 스폰으로 인해 소프트웨어적인 자원 고갈만으로 뻗는 건가?)
HTTP 프로토콜에서 파일 업로드는 어떤 절차를 거쳐서 되는지, 방화벽이라는 게 정확히 뭘 하는 물건인지,
왜 구닥다리 윈도 2000/XP sp0을 띄운 채로 랜선을 꽂으면 뭐가 뚫려서 어떻게 되는지..
요즘은 네트워크 패킷은 하부 계층에서 압축이나 암호화를 좀 하는 게 있는지 등등..
이런 것들은 난 하나도 모..른..다. 저런 거 하나도 몰라도 <날개셋> 한글 입력기 개발하는 덴 아무 지장이 없기 때문이다.
그렇다고 해서 내가 컴퓨터 명령어 체계나 운영체제/소프트웨어 자체의 내부 구조나 보안에 대해 전혀 모르느냐 하면 그것도 물론 아니니.. 지식의 분포가 좀 불균형하다면 불균형한 셈이다.
본인은 초딩 중고학년 때 개인용 PC, 중학교 때 모뎀과 PC 통신, 고등학교 때 인터넷과 이메일, 그리고 대학교 때 무선 인터넷과 휴대전화의 순으로 문명의 이기들을 접했다. 랜 선이라는 걸 태어나서 처음으로 구경한 게 고등학교 때부터인데, 그 기간 동안 언젠가 집도 인터넷 접속 방식이 전화 모뎀에서 전용선으로 바뀌었다. 그때가 한창 전국적으로 인터넷 전용선이 깔리던 시절이었으니까.
지금까지 통신 기술은 정말 눈부신 속도로 발전했다.
신문· 방송에서 기자의 이메일을 공개하는 게 대세가 된 게 1990년대 후반부터이다.
지금으로부터 10여 년 전엔 '블로그'라는 단어가 도전 골든벨의 마지막 문제의 답이었다는 게 믿어지시는가? (그것도 학생이 못 맞혔고 그 당시엔 내게도 생소했다)
옛날에는 인터넷 연결을 위해서도 PC 통신을 할 때처럼 먼저 전화를 걸어야 했다. 사용 시간 카운터가 올라가는 자그마한 인터넷 연결 창이 뜬 동안만 인터넷을 이용할 수 있었다.
또한, 모뎀과 마우스를 동시에 사용하려면 두 물건을 서로 COM 포트가 충돌하지 않게 배치를 해야 했다.
Windows 3.x에서는 운영체제 차원의 네트워크 지원이 전무하기 때문에 트럼펫 Winsock인지 뭔지 하는 걸 먼저 설치해야 했다.
이 모든 것들이 지금은 까마득한 옛날 이야기가 됐다.
지금은 뭔가 그렇게 상태를 확인하면서 인터넷을 해야 하는 상황은 스마트폰 태더링으로 무선 인터넷을 쓸 때 정도이고 이것도 제약, 압박감, 부담 같은 건 옛날과는 비교할 수 없이 작아졌다.
메인보드가 어떻게 공간 워프를 했는지, 요즘은 유선 랜과 무선 랜도 전부 내장되어 나온다. 따로 뭘 장착조차 할 필요 없이 바로 접속만 하면 된다.
오늘날 인터넷이라고 불리는 그 통신망은 OSI 레이어 계층 중 제3계층(네트워크 계층)을 차지하는 IP라는 프로토콜을 기반으로 동작한다. IPv4, IPv6 같은 주소 체계도 이 계층에서 규정하는 것이기 때문에 모든 인터넷 통신은 이 체계를 기반으로 구성되어 있다.
그리고 그 아래의 제4계층(전송 계층)에는 인터넷 프로토콜을 따르는 네트워크 패킷을 보내는 방식의 차이를 규정하는 프로토콜이 있는데, 크게 TCP와 UDP가 있다.
TCP는 보낸 패킷이 반드시 순서대로 도착한다는 것은 보장되지만, 보냈던 단위랄까 형태가 그대로 도착하지는 않는다.
aaa, bb, ccccc, ddd, e 이렇게 패킷을 보냈으면 받는 쪽은 aa, ab, bccc, cc, dd, d, e 뭐 이렇게 받을 수도 있고 다른 형태가 될 수도 있다. 조립은 받는 쪽에서 알아서 해야 한다.
UDP는 TCP와는 달리 보낸 패킷이 원래의 형태 그대로 간다는 보장은 되지만.. 일부 패킷이 전송 과정에서 누락될 수가 있다.
즉, 위의 경우 ddd가 누락돼서 aaa, bb, ccccc, e 이렇게 갈지도 모르지만.. 일단 간 놈은 원래 형태 그대로 간다. 패킷의 누락 여부 판단을 받는 쪽에서 알아서 해야 한다.
그래서 TCP는 일종의 스트림 지향적이며, UDP는 개개의 패킷이 모 아니면 도 형태로 가는 메시지 지향적이다.
형태도 보존되고 누락 현상도 없는 만능 프로토콜이 없는 이유야 뭐, 세상에 값도 싸고 성능도 좋은 물건은 존재하지 않기 때문인 것과 같은 맥락일 것이다.
그게 필요하면 UDP 같은 걸 기반으로 패킷 누락을 감지하고 재전송을 요청하는 로직을 응용 프로그램이 별도로 구현해 줘야 한다.
온라인 게임에서는 “기관총 난사 내지 캐릭터 이동 같은 것만 UDP이고 나머지는 다 TCP”라는 말 한 마디로 요약된다.
자주 발생하기 때문에 반응성이 중요하고 적당히 좀 씹혀도 상관 없는 것만 UDP이고.. 나머지 크리티컬한 것들은 다 TCP를 써야 한다는 뜻이다.
그러나 온라인 게임에서 발생하는 트래픽의 상당수, 대략 70% 가까이는 그래도 UDP 방식이라고 한다.
실시간으로 스트리밍되는 대용량 오디오/비디오 데이터도 자명한 이유로 인해 UDP 방식으로 전송된다.
이런 차이를 보면, TCP와 UDP의 관계는 사실상 무손실 압축과 손실 압축의 관계나 마찬가지인 것 같다.
TCP의 경우 응용 프로그램이 아니라 아래의 프로토콜 차원에서 패킷의 누락을 감지하여 누락이 있는 경우 재전송 요청을 한다.
그런데 모바일처럼 네트워크 환경이 원래 워낙 열악해서 패킷 손실이 굉장히 자주 발생하는 곳에서는
TCP 방식에서는 끝도 없이 재전송 요청을 하고 받은 데이터에 결함이 없는지 체크와 빠꾸만 반복하느라 응용 프로그램이 그 동안 멍하니 있어야만 하는 일이 발생한다고 한다.
즉, TCP가 구조적으로 오버헤드가 더 크니, 네트워크가 열악한 곳에서는 그런 동작을 감안해야 한다.
게임에서 그래픽 엔진, 물리 엔진, 동영상/캡처 엔진도 아니고 네트웍 엔진 미들웨어로 먹고 사는 분이 국내에 일단 한 분 계신다. 넷텐션의 대표이사인 배 현직 씨. 이 업계에서는 이미 유명인사이다.
난 네트워크 쪽 프로그래밍을 해 본 건 먼~ 옛날에 소켓 API 대충 뚝딱해서 오목을 만들고..
DirectPlay를 써서 스크래블 정도 보드 게임에다가 네트웍 플레이를 넣어 본 게 전부이다. 그래도 그것만으로도 굉장히 재미있는 경험이었다.
저수준에서 패킷 암호화, 각종 오류 처리 그런 건 모른다. DPlay는 나름 하드웨어 독립을 추구한 통신 API이긴 한데, 요즘은 모뎀이고 시리얼 케이블 그딴 건 다 없어졌으니 그런 추상화 계층이 필요가 없어지면서 자연스레 도태했다. 잘은 모르겠지만 제1계층(물리 계층)은 거의 획일화가 돼 버린 것 같다.
※ 여담. IPX는 어디로 갔는가?
스타크래프트에서 배틀넷 말고 그냥 LAN으로 친구들끼리 팀플을 할 때, 옛날에는 배틀넷 다음으로 위에서 둘째인 IPX를 으레 고르곤 했다. 그러나 어느 패치 때부터인가 맨 아래에 UDP가 추가되었으며 그걸 고르는 걸로 구조가 바뀌었다. IPX는 동작하지 않기 시작했다. 어찌 된 일일까?
IPX라는 프로토콜은 똑같이 이더넷 랜선으로 통신을 하지만, 오늘날의 인터넷과는 다른 방식으로 통신을 한다. 즉, IP와 대등한 제3계층에서 방식이 다른 프로토콜인 것이다. IPX는 옛날에 네트워크 솔루션으로 유명했던 노벨 사에서 개발했고 실제로 매우 널리 쓰이기도 했지만 오늘날은 IP에 밀려서 사라졌다.
Windows 95때까지만 해도 네트워크 구성요소들을 설치하고 나면 기본으로 깔리는 것은 IPX였다. TCP/IP 지원 기능은 운영체제 CD를 넣어서 별도로 설치해야 했다. 무슨 말이냐 하면, 오늘날 당연시되고 있는 이 컴퓨터의 IP 주소를 설정하는 기능이 Windows 95에는 기본으로 없었다는 뜻이다. (심지어 네트워크 기능이 설치된 컴에서도)
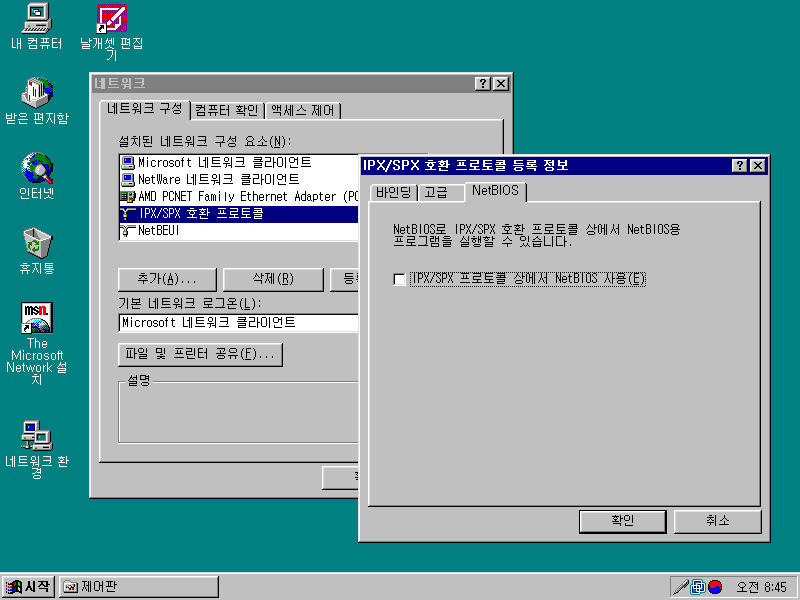
그 다음 1990년대 중후반, Windows 98부터는 인터넷의 중요성이 워낙 크게 부각되기 시작했으니 TCP/IP 지원도 같이 포함되었다.
여담이지만 Windows에서는 등록정보/속성을 나타내는 단축키가 R인 편인데, 95에서는 유독 저 대화상자에서만 R은 삭제이고, 등록정보는 P였다. 무척 불편했는데 이 역시 98부터는 다같이 R로 개선됐다.
하긴, 본인도 옛날부터.. Windows가 근거리 네트워크 차원에서 제공하는 컴퓨터 간의 폴더 공유 기능과, 웹브라우저로 띄우는 인터넷은 기술적으로 무슨 관계인가 궁금하긴 했다.
인터넷 열풍 앞에서 IPX는 점점 잉여로 전락했으며, Vista부터는 드디어 IPX 지원이 hlp 도움말만큼이나 짤렸다. 그래서 스타크래프트도 근거리 팀플에 인터넷 프로토콜을 사용하는 UDP 지원이 추가된 것이다.
Posted by 사무엘