요즘 팔자에도 없던 지뢰찾기에 살짝 재미가 붙었다.
본인은 비슷한 학력· 경력으로 IT 업계에 종사하는 여느 사람들과는 달리, 머리 싸움을 즐기는 스타일이 전혀 아니었으며 복잡한 퍼즐 게임 따위와도 담을 쌓고 지내는 편이었다. 이런 점에서 본인은 완전 퍼즐 게임 매니아인 T모 님과는 성향이 다르다.
그래도 지뢰찾기 정도면 요령을 알고 나니까 은근히 재미있다. 초보 레벨로는(9*9, 지뢰 10개) 40초~1분 남짓한 시간 동안 대략 60~70%대의 승률로 깨겠다. 처음엔 초보 레벨조차도 5분이 넘게 끙끙대기도 했으나, 마치 경부선 서울-부산 열차의 운행 시간이 17시간에서 6시간대~4시간대로 줄어들듯이 시간이 단축되었다.
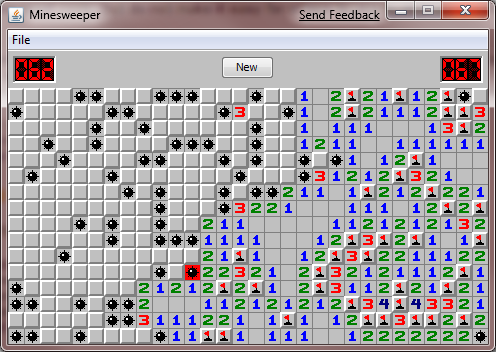
맥북의 터치패드 격인 트랙패드로는 도저히 게임을 할 수 없는 듯했다.
두 손가락을 동시에 누르거나 패드 우측 하단을 지그시 누르면 우클릭이 되긴 하는데, 이게 생각보다 정확하게 인식되지가 않는 듯하기 때문이었다.
지뢰가 있다는 깃발만 꽂으려고 우클릭을 했는데, 그게 좌클릭으로 인식되어 지뢰를 밟고 장렬히 죽는 참사가 한두 번 발생하는 게 아니어서 말이다. 단, Windows Vista 이후부터 새로 개발된 지뢰찾기는 Shift+클릭으로 우클릭, 더블클릭으로 좌우 클릭도 돼서 조작이 훨씬 더 편해졌다.
키보드로는 Space는 셀 개봉(좌클릭)이고, Shift+Space가 깃발(우클릭)이다.
그런데 이번엔 깃발이 꽂힌 것을 제외한 모든 인접 셀들을 한꺼번에 개봉하는 건 키보드로 어떻게 하는지 모르겠다. 게임에 익숙해지고 나면 셀 개봉은 하나씩 클릭하는 것보다 저렇게 개봉을 훨씬 더 즐겨 하게 되는데 말이다.
지뢰찾기라는 게임은 풀이 순서를 논리적으로 명확하게 유추 가능한 상황이 대부분이지만, 가끔은 주어진 정보만으로는 정확한 지뢰 배치를 알 수 없어서 찍기(guessing)를 해야 하는 경우도 있다. 지뢰가 정확하게 어떤 조건으로 배치되어 있을 때 그런 상황이 생기는지는 잘 모르겠다.
숫자 정보로부터 유추 가능한 지뢰 배치 가짓수는 기본적으로 폭발적으로 증가할 수 있으며, 어떻게 될 수 있는지 백트래킹으로 일일이 하나하나 때려박아 넣으며 추적을 하는 수밖에 없다. 뭔가 네모네모 로직을 푸는 것 같은 느낌이 들기도 한다. 이 때문인지 이 문제는 전산학적으로 봤을 때 NP 완전 문제라는 것까지 증명되었다.
그리고 찍기가 필요 없는 명확한 상황일 때 사람이 지뢰를 찾는 절차는 의외로 아주 명료하고 기계적이다.
딱 이 정도 영역이 개봉되고 인접 셀의 지뢰 정보가 이렇게 주어졌을 때, '명백한 해법' 하나만 동원해서라도 컴퓨터가 게임 진행을 충분히 도와 줄 수 있겠다는 생각이 들었다.
그래서, 막간을 이용해 지뢰찾기를 푸는 프로그램을 짜 봤다.
초-중급 수준의 간단한 클래스 설계와 알고리즘 구현이 동원되니 심심풀이 땅콩 코딩용으로 꽤 적절한 거 같다!
'명백한 해법'을 적용할 수 없어서 '찍기'를 해야 할 때, 지뢰가 있을 만한 위치를 가장 유력하게 유추하는 것 정도까지 구현해야 비로소 중급-고급 사이를 넘볼 수 있지 싶다.
대략의 코딩 내역은 이러하다.
지뢰 답을 알고 있는 MineSource 클래스(각 칸마다 지뢰 여부를 실제로 담고 있는 2차원 배열),
그리고 그 MineSource에다가 쿼리를 해 가며 1~8 숫자와 자기가 찾아낸 지뢰 위치 정보만을 알고 있는 MineSolver 클래스를 만들었다.
이들은 다 2차원 배열과 배열의 크기는 공통 정보로 갖고 있으므로 MapData라는 동일 기반 클래스를 설정했다.
MineSource는 특정 위치 x,y에 대한 쿼리가 온 경우, MineSolver에다가 인접 셀들의 지뢰 개수를 써 준다. 인접 셀에 지뢰가 하나도 없다면 여느 지뢰찾기 프로그램이 그러는 것처럼 인접 셀 8개도 한꺼번에 개봉하면서 flood fill을 한다.
곧바로 지뢰를 찍었다면 당연히 곧바로 게임 오버라고 알려 준다. 그리고 요즘 지뢰찾기 게임 구현체들이 그런 것처럼, 첫 턴에서는 절대로 지뢰를 찍는 일이 없게 내부 보정을 하는 것도 이 클래스에서 하는 일이다.
지뢰찾기의 '명백한 해법'은 딱 두 가지이다.
- 열리지 않은(지뢰 마크가 있는 놈 포함) 인접 셀의 개수와 자기 숫자가 '같은' 셀은 주변 미개봉 셀이 다 지뢰임이 100% 확실하므로 그것들을 전부 지뢰 마크(깃발)로 표시한다.
- 깃발이 꽂힌 주변 셀의 개수와 자기 숫자가 같은 셀의 경우, 지뢰 마크가 없는 나머지 열리지 않은 인접 셀은 지뢰가 아닌 게 100% 확실하다. 따라서 전부 개봉한다.
- (위의 명백한 해법만으로 개봉할 만한 셀이 존재하지 않는 건 운이 나쁜 케이스다. 패턴을 기반으로 랜덤 추측을 해야 하는데, 이건 일단 보류.)
텍스트 모드에서 자기 스스로 무작위하게 지뢰밭을 만들고 지뢰찾기를 풀기도 하는 자문자답 프로그램을 만드니, 200줄이 좀 안 되는 코드가 완성되었다.
이 프로그램은 인접 셀에 대해서 뭔가 조건을 만족하는 셀의 개수를 세거나, (getCount) 일괄적으로 동일한 조치를 취하는(doAction) 패턴이 많다.
이걸 그냥 for(j=y-1; j<=y+1; j++) for(i=x-1; i<=x+1; i++)이라는 2중 for문만으로 돌리기에는 i나 j가 boundary 밖인 경우도 고려해야 하고, (i,j)가 (x,y)와 같은 위치인 경우도 피해 가야 하기 때문에 loop 자체가 생각보다 복잡하다.
그러니, 그 loop 자체만 하나만 짜 놓고 loop 안에서 하는 일을 그때 그때 달리 지정하는 것은 템플릿-람다로 깔끔하게 설계했다.
다음은 프로그램의 간단한 실행 결과이다.
after the first turn:
+ + 1 . . . . . .
+ + 1 . 1 1 1 . .
+ + 1 . 1 + 2 1 .
+ + 1 . 1 2 + 1 .
1 1 1 . . 1 + 2 1
. . . . 1 1 + + +
. . . . 1 + + + +
. 1 1 2 2 + + + +
. 1 + + + + + + +
(중간 과정 생략)
picking 7 9
@ @ 1 . . . . . .
2 2 1 . 1 1 1 . .
1 1 1 . 1 @ 2 1 .
1 @ 1 . 1 2 @ 1 .
1 1 1 . . 1 2 2 1
. . . . 1 1 3 @ 2
. . . . 1 @ 3 @ 2
. 1 1 2 2 2 2 1 1
. 1 @ 2 @ 1 . . .
You Won!
이 정도 초보적인 지뢰 찾기 풀이 프로그램은 이미 다 개발되고도 남았으니,
유튜브를 뒤지면 신의 경지 수준의 속도를 자랑하는 지뢰찾기 TAS (매크로 프로그램 내지 역공학을 동원한 게임 스피드런) 동영상들이 나돌고 있다.
여담이다만, 지뢰찾기를 하다가 지뢰를 밟아서 게임 오버가 될 때 본인은 깜짝 깜짝 잘 놀란다. =_= 마치 옛날에 페르시아의 왕자를 하는데 타이밍을 잘못 잡아서 왕자가 쇠톱날(chopper)에 두 동강 나서 죽는 것 같은 그런 느낌이다.
Posted by 사무엘